rsync用于同步目录
rsync是unix/linux下同步文件的一个高效算法,它能同步更新两处计算机的文件与目录,并适当利用查找文件中的不同块以减少数据传输。rsync中一项与其他大部分类似程序或协定中所未见的重要特性是镜像是只对有变更的部分进行传送。rsync可拷贝/显示目录属性,以及拷贝文件,并可选择性的压缩以及递归拷贝。rsync利用由Andrew Tridgell发明的算法。这里不介绍其使用方法,只介绍其核心算法。我们可以看到,Unix下的东西,一个命令,一个工具都有很多很精妙的东西,怎么学也学不完,这就是Unix的文化啊。
本来不想写这篇文章的,因为原先发现有很多中文blog都说了这个算法,但是看了一下,发现这些中文blog要么翻译国外文章翻译地非常烂,要么就是介绍这个算法介绍得很乱让人看不懂,还有错误,误人不浅,所以让我觉得有必要写篇rsync算法介绍的文章。(当然,我成文比较仓促,可能会有一些错误,请指正)
问题
首先, 我们先来想一下rsync要解决的问题,如果我们要同步的文件只想传不同的部分,我们就需要对两边的文件做diff,但是这两个问题在两台不同的机器上,无法做diff。如果我们做diff,就要把一个文件传到另一台机器上做diff,但这样一来,我们就传了整个文件,这与我们只想传输不同部的初衷相背。
于是我们就要想一个办法,让这两边的文件见不到面,但还能知道它们间有什么不同。这就出现了rsync的算法。
算法
rsync的算法如下:(假设我们同步源文件名为fileSrc,同步目的文件叫fileDst)
1)分块Checksum算法。首先,我们会把fileDst的文件平均切分成若干个小块,比如每块512个字节(最后一块会小于这个数),然后对每块计算两个checksum,
- 一个叫rolling checksum,是弱checksum,32位的checksum,其使用的是Mark Adler发明的adler-32算法,
- 另一个是强checksum,128位的,以前用md4,现在用md5 hash算法。
为什么要这样?因为若干年前的硬件上跑md4的算法太慢了,所以,我们需要一个快算法来鉴别文件块的不同,但是弱的adler32算法碰撞概率太高了,所以我们还要引入强的checksum算法以保证两文件块是相同的。也就是说,弱的checksum是用来区别不同,而强的是用来确认相同。(checksum的具体公式可以参看这篇文章)
2)传输算法。同步目标端会把fileDst的一个checksum列表传给同步源,这个列表里包括了三个东西,rolling checksum(32bits),md5 checksume(128bits),文件块编号。
我估计你猜到了同步源机器拿到了这个列表后,会对fileSrc做同样的checksum,然后和fileDst的checksum做对比,这样就知道哪些文件块改变了。
但是,聪明的你一定会有以下两个疑问:
- 如果我fileSrc这边在文件中间加了一个字符,这样后面的文件块都会位移一个字符,这样就完全和fileDst这边的不一样了,但理论上来说,我应该只需要传一个字符就好了。这个怎么解决?
- 如果这个checksum列表特别长,而我的两边的相同的文件块可能并不是一样的顺序,那就需要查找,线性的查找起来应该特别慢吧。这个怎么解决?
很好,让我们来看一下同步源端的算法。
3)checksum查找算法。同步源端拿到fileDst的checksum数组后,会把这个数据存到一个hash table中,用rolling checksum做hash,以便获得O(1)时间复杂度的查找性能。这个hash table是16bits的,所以,hash table的尺寸是2的16次方,对rolling checksum的hash会被散列到0 到 2^16 – 1中的某个整数值。(对于hash table,如果你不清楚,建议回去看大学时的数据结构教科书)
顺便说一下,我在网上看到很多文章说,“要对rolling checksum做排序”(比如这篇和这篇),这两篇文章都引用并翻译了原作者的这篇文章,但是他们都理解错了,不是排序,就只是把fileDst的checksum数据,按rolling checksum做存到2^16的hash table中,当然会发生碰撞,把碰撞的做成一个链表就好了。这就是原文中所说的第二步——搜索有碰撞的情况。
4)比对算法。这是最关键的算法,细节如下:
4.1)取fileSrc的第一个文件块(我们假设的是512个长度),也就是从fileSrc的第1个字节到第512个字节,取出来后做rolling checksum计算。计算好的值到hash表中查。
4.2)如果查到了,说明发现在fileDst中有潜在相同的文件块,于是就再比较md5的checksum,因为rolling checksume太弱了,可能发生碰撞。于是还要算md5的128bits的checksum,这样一来,我们就有 2^-(32+128) = 2^-160的概率发生碰撞,这太小了可以忽略。如果rolling checksum和md5 checksum都相同,这说明在fileDst中有相同的块,我们需要记下这一块在fileDst下的文件编号。
4.3)如果fileSrc的rolling checksum 没有在hash table中找到,那就不用算md5 checksum了。表示这一块中有不同的信息。总之,只要rolling checksum 或 md5 checksum 其中有一个在fileDst的checksum hash表中找不到匹配项,那么就会触发算法对fileSrc的rolling动作。于是,算法会住后step 1个字节,取fileSrc中字节2-513的文件块要做checksum,go to (4.1) - 现在你明白什么叫rolling checksum了吧。
4.4)这样,我们就可以找出fileSrc相邻两次匹配中的那些文本字符,这些就是我们要往同步目标端传的文件内容了。
图示
怎么,你没看懂? 好吧,我送佛送上西,画个示意图给你看看(对图中的东西我就不再解释了)。
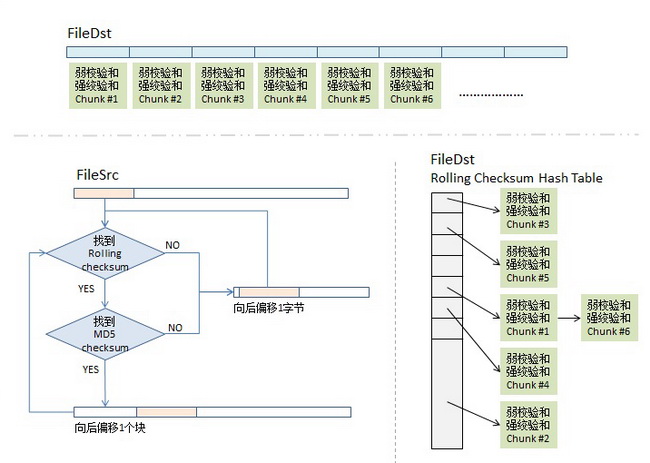
这样,最终,在同步源这端,我们的rsync算法可能会得到下面这个样子的一个数据数组,图中,红色块表示在目标端已匹配上,不用传输(注:我专门在其中显示了两块chunk #5,相信你会懂的),而白色的地方就是需要传输的内容(注意:这些白色的块是不定长的),这样,同步源这端把这个数组(白色的就是实际内容,红色的就放一个标号)压缩传到目的端,在目的端的rsync会根据这个表重新生成文件,这样,同步完成。

最后想说一下,对于某些压缩文件使用rsync传输可能会传得更多,因为被压缩后的文件可能会非常的不同。对此,对于gzip和bzip2这样的命令,记得开启 “rsyncalbe” 模式。
rsync用于同步目录的更多相关文章
- puppet使用rsync模块同步目录和文件
puppet使用rsync模块同步目录和文件 2013-09-23 14:28:57 分类: LINUX 环境说明: OS : CentOS5.4 ...
- 使用rsync同步目录
本文描述了linux下使用rsync单向同步两个机器目录的问题. 使用rsync同步后可以保持目录的一致性(含删除操作). 数据同步方式 从主机拉数据 备机上启动的流程 同步命令: rsync -av ...
- rsync同步目录及同步文件
最简单的只读同步工作. 一,服务端的配置 1,安装rsync(阿里云默认已有此程序) 略 2,生成文件rsyncd.conf,内容如下: #secrets file = /etc/rsyncd.sec ...
- rsync+inotify 实现资源服务器的同步目录下的文件变化时,备份服务器的同步目录更新,以资源服务器为准,去同步其他客户端
测试环境: 资源服务器(主服务器):192.168.200.95 备份服务器(客户端):192.168.200.89 同步目录:/etc/test 同步时使用的用户名hadoop密码12345 实验目 ...
- 使用rsync, 向另外一台服务器同步目录和文件的脚本
#!/bin/bash #亚特兰蒂斯-同步目录#定时任务ini_file="/usr/local/sunlight/conf/rsync-file.ini"target_ip=&q ...
- Rsync文件同步
Rsync文件同步 本章结构 关于rsync 1.一款增量备份工具,remote sync,远程同步,支持本地复制或者与其他SSH.rsync主机同步,官方网站:http://rsync.samba. ...
- 架设rsync服务器同步数据
什么是rsync rsync 是一个快速增量文件传输工具,它可以用于在同一主机备份内部的备分,我们还可以把它作为不同主机网络备份工具之用.本文主要讲述的是如何自架rsync服 务器,以实现文件传输.备 ...
- rsync 文件同步和备份
rsync 是同步文件的利器,一般用于多个机器之间的文件同步与备份,同时也支持在本地的不同目录之间互相同步文件.在这种场景下,rsync 远比 cp 命令和 ftp 命令更加合适,它只会同步需要更新的 ...
- inotify 与 rsync文件同步实现与问题
首先分别介绍inotify 与 rsync的使用,然后用两者实现实时文件同步,最后说一下这样的系统存在什么样的问题. 1. inotify 这个具体使用网上很多,参考 inotify-tools 命令 ...
随机推荐
- [bzoj1052] [HAOI2007]覆盖问题
Description 某人在山上种了N棵小树苗.冬天来了,温度急速下降,小树苗脆弱得不堪一击,于是树主人想用一些塑料薄膜把这些小树遮盖起来,经过一番长久的思考,他决定用3个L * L的正方形塑料薄膜 ...
- 洛谷 P1251 餐巾计划问题
题目链接 最小费用最大流. 每天拆成两个点,早上和晚上: 晚上可以获得\(r_i\)条脏毛巾,从源点连一条容量为\(r_i\),费用为0的边. 早上要供应\(r_i\)条毛巾,连向汇点一条容量为\(r ...
- 2018牛客多校第一场 A.Monotonic Matrix
题意: 给一个n*m的矩阵赋值(0,1,2).使得每个数都不小于它左面和上面的数. 题解: 构建0和1的轮廓线.对于单独的轮廓线,共需要往上走n步,往右走m步.有C(n+m,n)种方式. 两个轮廓线的 ...
- sqlplus 几个命令:
sqlplus 几个命令: 在sys,system,sysman,scott四个用户权限中,scott用户最低. 其权限依次从高到低. cmd进入sqlplus sqlplus 登录命令: 登录sys ...
- HDU 5671 矩阵
Matrix Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)Total Su ...
- MongoDB加索引
1.登陆MongoDB, 命令行在MongoDB主目录下执行:mongo -port 27017 2.切换至需要添加索引的db 并授权 use MeetingBooking db.auth({&quo ...
- The 'brew link' step did not complete successfully
在mac 上更新node时遇到了一系列的问题: 卸载node重新安装之后提示: The 'brew link' step did not complete successfully 其实这里已经给出了 ...
- Nginx配置配置文件详解
文章目录 配置文件 nginx.conf配置文件详解 用于调试.定位问题的配置参数 正常运行必备的配置参数 优化性能的配置参数 事件相关配置 Fastcgi相关配置参数 常需要调整的参数 nginx作 ...
- JAVA程序打包成exe文件详细图解
我们都知道Java可以将二进制程序打包成可执行jar文件,双击这个jar和双击exe效果是一样一样的,但感觉还是不同.其实将java程序打包成exe也需要这个可执行jar文件. 准备: eclipse ...
- GridPanel 带头和锁定列共存
该功能还存在很多BUG,仅供参考 Ext.net.ResourceMgr.load([{ url: _HOST + "Js/OverwriteExtjs/LockingHeaderGroup ...