转:sql语句中GROUP BY 和 HAVING和使用 count()
|
id
|
user
|
num
|
|
1
|
a
|
3
|
|
2
|
a
|
4
|
|
3
|
b
|
5
|
|
4
|
b
|
7
|
在介绍GROUP BY 和 HAVING 子句前,我们必需先讲讲sql语言中一种特殊的函数:聚合函数,
例如SUM, COUNT, MAX, AVG等。这些函数和其它函数的根本区别就是它们一般作用在多条记录上。
SELECT SUM(population) FROM bbc
这里的SUM作用在所有返回记录的population字段上,结果就是该查询只返回一个结果,即所有
国家的总人口数。
having是分组(group by)后的筛选条件,分组后的数据组内再筛选
where则是在分组前筛选
通过使用GROUP BY 子句,可以让SUM 和 COUNT 这些函数对属于一组的数据起作用。
当你指定 GROUP BY region 时, 属于同一个region(地区)的一组数据将只能返回一行值.
也就是说,表中所有除region(地区)外的字段,只能通过 SUM, COUNT等聚合函数运算后返回一个值.
HAVING子句可以让我们筛选成组后的各组数据.
WHERE子句在聚合前先筛选记录.也就是说作用在GROUP BY 子句和HAVING子句前.
而 HAVING子句在聚合后对组记录进行筛选。
让我们还是通过具体的实例来理解GROUP BY 和 HAVING 子句,还采用第三节介绍的bbc表。
SQL实例:
一、显示每个地区的总人口数和总面积.
SELECT region, SUM(population), SUM(area)
FROM bbc# `& e4 k' X* n1 v% ?+ |
GROUP BY region
先以region把返回记录分成多个组,这就是GROUP BY的字面含义。分完组后,然后用聚合函数对每组中的不同字段(一或多条记录)作运算。# B* i' z `, }* S, E5 i
二、 显示每个地区的总人口数和总面积.仅显示那些面积超过1000000的地区。
SELECT region, SUM(population), SUM(area)7 ]; Z& I! t% i
FROM bbc8 F4 w2 v( P- f
GROUP BY region
HAVING SUM(area)>1000000# y" P z. O7 D9 `# X
在这里,我们不能用where来筛选超过1000000的地区,因为表中不存在这样一条记录。
相反,HAVING子句可以让我们筛选成组后的各组数据
三、查询CUSTOMER 和ORDER表中用户的订单数
select c.name, count(order_number) as count from orders o,customer c where c.id=o.customer_id group by customer_id;
+--------+-------+
| name | count |
+--------+-------+
| d | 9 |
| cc | 6 |
| 菩提子 | 1 |
| cccccc | 2 |
+--------+-------+
增加HAVING过滤
select c.name, count(order_number) as count from orders o,customer c where c.id=o.customer_id group by customer_id having count(order_number)>5;
+------+-------+
| name | count |
+------+-------+
| d | 9 |
| cc | 6 |
+------+-------+
四、我在多举一些例子
SQL> select * from sc;
SNO PNO GRADE
---------- ----- ----------
1 YW 95
1 SX 98
1 YY 90
2 YW 89
2 SX 91
2 YY 92
3 YW 85
3 SX 88
3 YY 96
4 YW 95
4 SX 89
SNO PNO GRADE
---------- ----- ----------
4 YY 88
这个表所描述的是4个学生对应每科学习成绩的记录,其中SNO(学生号)、PNO(课程名)、GRADE(成绩)。
1、显示90分以上学生的课程名和成绩
//这是一个简单的查询,并没有使用分组查询
SQL> select sno,pno,grade from sc where grade>=90;
SNO PNO GRADE
---------- ----- ----------
1 YW 95
1 SX 98
1 YY 90
2 SX 91
2 YY 92
3 YY 96
4 YW 95
已选择7行。
2、显示每个学生的成绩在90分以上的各有多少门
//进行分组显示,并且按照where条件之后计数
SQL> select sno,count(*) from sc where grade>=90 group by sno;
SNO COUNT(*)
---------- ----------
1 3
2 2
4 1
3 1
3、这里我们并没有使用having语句,接下来如果我们要评选三好学生,条件是至少有两门课程在90分以上才能有资格,列出有资格的学生号及90分以上的课程数。
//进行分组显示,并且按照where条件之后计数,在根据having子句筛选分组
SQL> select sno,count(*) from sc where grade>=90 group by sno having count(*)>=2;
SNO COUNT(*)
---------- ----------
1 3
2 2
这个结果是我们想要的,它列出了具有评选三好学生资格的学生号,跟上一个例子比较之后,发现这是在分组后进行的子查询。
4、学校评选先进学生,要求平均成绩大于90分的学生都有资格,并且语文课必须在95分以上,请列出有资格的学生
//实际上,这个查询先把语文大于95分的学生号提取出来,之后求平均值,分组显示后根据having语句选出平均成绩大于90的
SQL> select sno,avg(grade) from sc where SNO IN (SELECT SNO FROM SC WHERE GRADE>=95 AND PNO='YW') group by sno having avg(grade)>=90;
SNO AVG(GRADE)
---------- ----------
1 94.3333333
4 90.6666667
5、查询比平均成绩至少比学号是3的平均成绩高的学生学号以及平均分数
//having子句中可进行比较和子查询
SQL> select sno,avg(grade) from sc
group by sno
having avg(grade) > (select avg(grade) from sc where sno=3);
注意:
个人在tbl_user表进行如下查询:
id username pwd
1 demo a
2 user1 user1
3 user2 user2
4 user1 pwe
5 user2 pwe
SELECT * FROM `tbl_user` group by username;
结果如下:
id username pwd
1 demo a
2 user1 user1
3 user2 user2
可以看到,group by columnName,这个columnName值一定是唯一的,重复的忽略掉。
mysql筛选GROUP BY多个字段组合
想实现这样一种效果
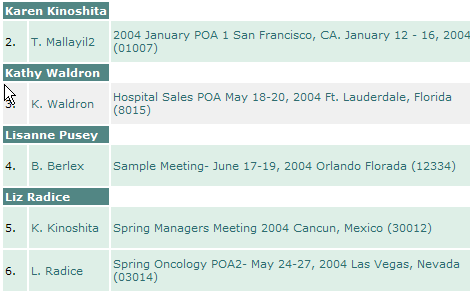
如果使用group by一个条件的话,得到的结果会少了很多,如何多个条件组合筛选呢
循环的时候可以通过判断后一个跟前面一个是否相同来分组,一个示例
foreach($list as $k=>$v)
{ if((!isset($list[$k+])) || $list[$k+]['platform_id']!=$list[$k]['platform_id'])
{
echo "分割"
}
}
转:sql语句中GROUP BY 和 HAVING和使用 count()的更多相关文章
- sql语句中GROUP BY 和 HAVING的使用 count()
在介绍GROUP BY 和 HAVING 子句前,我们必需先讲讲sql语言中一种特殊的函数:聚合函数, 例如SUM, COUNT, MAX, AVG等.这些函数和其它函数的根本区别就是它们一般作用在多 ...
- (转载)SQL语句中Group by语句的详细介绍
转自:http://blog.163.com/yuer_d/blog/static/76761152201010203719835 SQL语句中Group by语句的详细介绍 ...
- sql语句中group by使用
group by分组函数,group by name 将查询结果按照name进行分组,相同name的记录一组,配合聚合函数,显示每个name的情况. 1,数据源 表A结构如下: CREATE TA ...
- SQL语句中GROUP BY的问题
今天查询数据库时用到集合函数sum(drp),遇到问题: 百度后,确定如下问题:当select后面查询字段有sum(drp)以外的字段时,必须使用group by函数,对数据进行排序,且查询字段中除s ...
- 转>>在同一个sql语句中如何写不同条件的count数量
今天在做Portal中的Dashboard展现的时候,需要对多个统计字段做展现,根据我现在的掌握水平,我只能在sql调用构建器中实现一种sql语 句返回的resultSet做展现.没有办法,只能从数据 ...
- [转]SQL语句:Group By总结
1. Group By 语句简介: Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若 ...
- SQL语句:Group By总结
1. Group By 语句简介: Group By语句从英文的字面意义上理解就是"根据(by)一定的规则进行分组(Group)".它的作用是通过一定的规则将一个数据集划分成若干个 ...
- sql语句中处理金额,把分换算成元
问题,sql语句中直接将金额/100返回的结果会有多个小数位. as value from account as acc left join conCategory as cate on acc.ca ...
- SQL语句中各个部分的执行顺序(转)
原文链接:http://www.tuicool.com/articles/fERNv2 写在前面的话:有时不理解SQL语句各个部分执行顺序,导致理解上出现偏差,或者是书写SQL语句时随心所欲,所以有必 ...
随机推荐
- Cmake 脚本对项目输出路径和输出头文件的路径定义
对Lib项目的统一输出路径以下时解决方案: set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR}/Lib)set(CMAKE_LIBRARY_O ...
- Android SDK 下载速度慢解决方法
Mac 本搞Android开发,遇到Android SDK 下载速度慢,解决方法大概有两种.第一,FQ.这种方法比较彻底,但是要想有稳定的效果还的要花大价钱.第二,有些高人直接给了SDK中各软件的下载 ...
- JAVA车票管理系统(简单GUI)
一. 需求分析 1.设计题目:车票管理系统 用JAVA语言和数据结构知识设计设计车票管理系统.要求如下所述: 一车站每天有n个发车班次,每个班次都有一个班次号(1.2.3…n),固定的发车时间, ...
- 关于时间的操作(JavaScript版)——依据不同区时显示对应的时间
如今项目基本上告一段落了,难得有一定的闲暇,今天利用数小时完毕了一个功能模块--依据不同区时显示对应的时间,这方面网上基本没有现成的样例,如今将代码粘贴例如以下: <!DOCTYPE HTML ...
- float position的測试案例
依据<a target=_blank href="http://blog.csdn.net/goodshot/article/details/44348525">htt ...
- Java MongoDB 资料集合
一.Mongodb介绍及对比 1.NoSQL介绍及MongoDB入门 http://renial.iteye.com/blog/684829 2.mongoDB 介绍(特点.优点.原理) http:/ ...
- [RxJS] Stopping a Stream with TakeUntil
Observables often need to be stopped before they are completed. This lesson shows how to use takeUnt ...
- android实现计算器功能
设计一个简单的计算器. 第一个Activity的界面. 第二个Activity显示算式和计算结果. 第一个Activity代码: import android.app.Activity; import ...
- Android状态栏颜色修改
android状态栏颜色修改 状态栏颜色的修改在4.4和5.x环境下分别有不同的方式,低于4.4以下是不能修改的. 5.x环境下 方式一,状态栏将显示为纯净的颜色,没有渐变效果 /** * 状 ...
- [ASP.NET] 檔案讀寫權限問題
今天遇到一個問題,環境如下: IIS Server: Server 2008 R2 沒加域 File Server: Server 2003 加域 當我的Web程序需要把位於File Server的一 ...