Web缓存杂谈
| 一、概述 |
缓存通俗点,就是将已经得到的‘东东’存放在一个相对于自己而言,尽可能近的地方,以便下次需要时,不会再二笔地跑到起始点(很远的地方)去获取,而是就近解决,从而缩短时间和节约金钱(坐车要钱嘛)。Web缓存,也是同样的道理,说白了,就是当你第一次访问网址时,将这个东东(representations),如html页面、图片、JavaScript文件等,存在一个离你较近的地方,当你下次还需要它时,不用再一次跋山涉水到服务器(origin servers)去获取。继而,web缓存的优势也就很明显了:
1、 减少了网络延迟,加快了页面响应速度,增强了用户体验嘛。(因为我是就近获取的,路程缩短了,所以响应速度当然比到遥远的服务器去获取快哦);
2、 减少了网络带宽消耗嘛。(就近获取);
3、 通过缓存,我们都不用到服务器 (origin servers)去请求了,从而也就相应地减轻了服务器的压力。
那web缓存将这些东东放在哪儿呢?下面我就看看有哪些缓存种类,从而了解放在哪吧。
| 二、Web缓存的种类 |
--数据库缓存--:
当web应用关系复杂,数据表蹭蹭蹭往上涨时,可以将查询后的数据放到内存中进行缓存,下次再查询时,就直接从内存缓存中获取,从而提高响应速度。
--CDN缓存--:
CDN通俗点,就是当我们发送一个web请求时,会先经过它一道手,然后它帮我们计算路径,去哪得到这些东东(representations)的路径短且快。这个是网站管理员部署的,所以他们也可以将大家经常访问的representations放在CDN里,这样,就响应就更快了。
--代理服务器缓存--:
代理服务器缓存,其实跟下面即将讲的浏览器缓存性质差不多,差别就是代理服务器缓存面向的群体更广,规模更大而已。即,它不只为一个用户服务,一般为大量用户提供服务,同一个副本会被重用多次,因此在减少相应时间和带宽使用方面很有效。
--浏览器缓存--:
简而言之,就是,每个浏览器都实现了 HTTP 缓存,我们通过浏览器使用HTTP协议与服务器交互的时候,浏览器就会根据一套与服务器约定的规则进行缓存工作。当我们点击浏览器上‘后退’或者‘前进’按钮时,显得特别有用。
| 三、Web缓存的执行机制 |
所谓机制就是一些双方的约定,清晰地告诉对方,什么时候该做什么事。web缓存也一样,你总得告诉我(请求)什么时候到缓存中去获取,什么到服务器去获取representations吧。So,也得有一套相应的机制,web 缓存机制分为两大部分http协议(HTTP1.0和HTTP1.1)和网站管理人员制定的协议。抛开网站内部制定的协议,我们来看看http协议中定义的缓存机制。
By the way,我们可以在HTML文档中的<head>中通过<meta>来缓存,如下:
<meta http-equiv="Pragma" content="no-cache"/>
但,它只有部分浏览器可以用,并且代理服务器也不会鸟它。(因为meta在html中,代理服务器几乎不回去读它滴)。
--http缓存机制--
1、 Expires
http缓存机制主要在http响应头中设定,响应头中相关字段为Expires、Cache-Control、Last-Modified、If-Modified-Since、Etag。
HTTP 1.0协议中的。简而言之,就是告诉浏览器在约定的这个时间前,可以直接从缓存中获取资源(representations),而无需跑到服务器去获取。
另:Expires因为是对时间设定的,且时间是Greenwich Mean Time (GMT),而不是本地时间,所以对时间要求较高。
2、 Cache-Control
HTTP1.1协议中的,因为有了它,所以可以忽略上面提到的Expires。因为Cache-Control相对于Expires更加具体,细致。
且,就算同时设置了Cache-Control和Expires,Cache-Control的优先级也高于Expires。
下面就来看看,Cache-Control响应头中常用字段的具体含义:
(1)、max-age:用来设置资源(representations)可以被缓存多长时间,单位为秒;
(2)、s-maxage:和max-age是一样的,不过它只针对代理服务器缓存而言;
(3)、public:指示响应可被任何缓存区缓存;
(4)、private:只能针对个人用户,而不能被代理服务器缓存;
(5)、no-cache:强制客户端直接向服务器发送请求,也就是说每次请求都必须向服务器发送。服务器接收到请求,然后判断资源是否变更,是则返回新内容,否则返回304,未变更。这个很容易让人产生误解,使人误以为是响应不被缓存。实际上Cache-Control: no-cache是会被缓存的,只不过每次在向客户端(浏览器)提供响应数据时,缓存都要向服务器评估缓存响应的有效性。
(6)、no-store:禁止一切缓存(这个才是响应不被缓存的意思)。
3、 Etag & If-None-Match
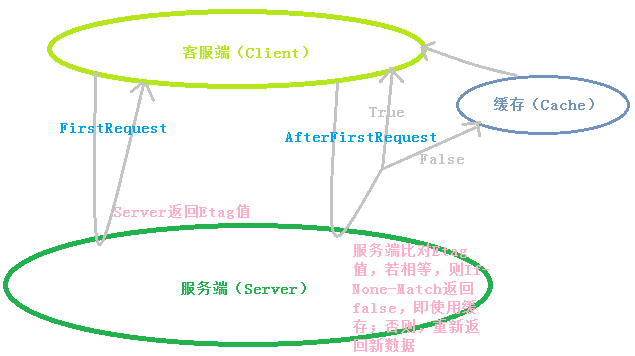
Etag是属于HTTP 1.1属性,它是由服务器生成返回给后端,当你第一次发起HTTP请求时,服务器会返回一个Etag,并在你再一次发起同一个请求时,客服端会同时发送一个If-None-Match,而它的内容就是Etag的值。最后,服务器会比对这个客服端发送过来的Etag是否与服务器的相同,如果相同,就If-None-Match的值为false,返回304继续使用本地缓存,否则就200。说白了,Etag就是服务器生成的一个标记而已。且Etag的优先级高于Last-Modified。
4、 Last-Modified & If-Modified-Since
Last-Modified与Etag类似。不过Last-Modified表示响应资源在服务器最后修改时间而已。与Etag相比,不足为:
(1)、Last-Modified标注的最后修改只能精确到秒级,如果某些文件在1秒钟以内,被修改多次的话,它将不能准确标注文件的修改时间;
(2)、如果某些文件会被定期生成,当有时内容并没有任何变化,但Last-Modified却改变了,导致文件没法使用缓存;
(3)、有可能存在服务器没有准确获取文件修改时间,或者与代理服务器时间不一致等情形。
然而,Etag是服务器自动生成或者由开发者生成的对应资源在服务器端的唯一标识符,能够更加准确的控制缓存。
| 四、扩展阅读 |
Web缓存杂谈的更多相关文章
- Web缓存杂谈--Etag & If-None-Match
一.概述 缓存通俗点,就是将已经得到的‘东东’存放在一个相对于自己而言,尽可能近的地方,以便下次需要时,不会再二笔地跑到起始点(很远的地方)去获取,而是就近解决,从而缩短时间和节约金钱(坐车要钱嘛). ...
- 作为前端应当了解的Web缓存知识
缓存优点 通常所说的Web缓存指的是可以自动保存常见http请求副本的http设备.对于前端开发者来说,浏览器充当了重要角色.除此外常见的还有各种各样的代理服务器也可以做缓存.当Web请求到达缓存时, ...
- 前端应当了解的Web缓存知识
缓存优点 通常所说的Web缓存指的是可以自动保存常见http请求副本的http设备.对于前端开发者来说,浏览器充当了重要角色.除此外常见的还有各种各样的代理服务器也可以做缓存.当Web请求到达缓存时, ...
- 浅谈Web缓存
在前端开发中性能一直都是被大家所重视的一点,然后判断一个网站的性能最直观的就是看网页打开的速度. 其中提高网页反应的速度的一个方式就是使用缓存.一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟, ...
- web缓存
web缓存HTTP协议的一个核心特性,它能最小化网络流量,并且提升用户所感知的整个系统响应速度. 什么能被缓存? *Logo和商标图像 *普通的不变化的图像(例如,导航图标) *CSS样式表 *普通的 ...
- Web 技术人员需知的 Web 缓存知识(转)
最近的译文距今已有4年之久,原文有一定的更新.今天踩着前辈们的肩膀,再次把这篇文章翻译整理下.一来让自己对web缓存的理解更深刻些,二来让大家注意力稍稍转移下,不要整天HTML5, 面试题啊叨啊叨的~ ...
- c# web 缓存管理
using System; using System.Collections; using System.Text.RegularExpressions; using System.Web; usin ...
- HTML5时代的Web缓存机制
HTML5 之离线应用Manifest 我们知道,使用传统的技术,就算是对站点的资源都实施了比较好的缓存策略,但是在断网的情况下,是无法访问的,因为入口的HTML页面我们一般运维的考虑,不会对其进行缓 ...
- Web缓存的作用与类型
前言 Web缓存是指一个Web资源(如html页面,图片,js,数据等)存在于Web服务器和客户端(浏览器)之间的副本.缓存会根据进来的请求保存输出内容的副本:当下一个请求来到的时候,如果是相同的UR ...
随机推荐
- HTML 获取屏幕、浏览器、页面的高度宽度
本篇主要介绍Web环境中屏幕.浏览器及页面的高度.宽度信息. 目录 1. 介绍:介绍页面的容器(屏幕.浏览器及页面).物理尺寸与分辨率.展示等内容. 2. 屏幕信息:介绍屏幕尺寸信息:如:屏幕.软件可 ...
- 窥探Vue.js 2.0 - Virtual DOM到底是个什么鬼?
引言 你可能听说在Vue.js 2.0已经发布,并且在其中新添加如了一些新功能.其中一个功能就是"Virtual DOM". Virtual DOM是什么 在之前,React和Em ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(74)-微信公众平台开发-自定义菜单
系列目录 引言 1.如果不借用Senparc.Weixin SDK自定义菜单,编码起来,工作量是非常之大 2.但是借助SDK似乎一切都是简单得不要不要的 3.自定义菜单无需要建立数据库表 4.自定义菜 ...
- jQuery学习之路(3)- 事件
▓▓▓▓▓▓ 大致介绍 jQuery增加了并扩展了基本的事件处理机制,不但提供了更加优雅的事件处理语法,而且极大地增强了事件处理能力 ▓▓▓▓▓▓ jQuery中的事件 ▓▓▓▓▓▓ 加载DOM 在j ...
- 如何利用pt-online-schema-change进行MySQL表的主键变更
业务运行一段时间,发现原来的主键设置并不合理,这个时候,想变更主键.这种需求在实际生产中还是蛮多的. 下面,看看pt-online-schema-change解决这类问题的处理方式. 首先,创建一张测 ...
- 解决“chrome提示adobe flash player 已经过期”的小问题
这个小问题也确实困扰我许久,后来看到chrome吧里面有人给出了解决方案: 安装install_flash_player_ppapi, 该软件下载地址:http://labs.adobe.com/do ...
- 水平可见直线 bzoj 1007
水平可见直线 (1s 128M) lines [问题描述] 在xoy直角坐标平面上有n条直线L1,L2,...Ln,若在y值为正无穷大处往下看,能见到Li的某个子线段,则称Li为可见的,否则Li为被覆 ...
- 【原】无脑操作:express + MySQL 实现CRUD
基于node.js的web开发框架express简单方便,很多项目中都在使用.这里结合MySQL数据库,实现最简单的CRUD操作. 开发环境: IDE:WebStorm DB:MySQL ------ ...
- JDK安装与配置
JDK安装与配置 一.下载 JDK是ORACLE提供免费下载使用的,官网地址:https://www.oracle.com/index.html 一般选择Java SE版本即可,企业版的选择Java ...
- 在开源中国(oschina)git中新建标签(tags)
我今天提交代码到主干上面,本来想打个标签(tags)的. 因为我以前新建过标签(tags),但是我现在新建的时候不知道入库在哪了.怎么找也找不到了. 从网上找资料也没有,找客服没有人理我,看到一个交流 ...