pandas进行数据分析需要的一些操作
一、查看数据
1.查看DataFrame前xx行或后xx行
a=DataFrame(data);
a.head(6)表示显示前6行数据,若head()中不带参数则会显示全部数据。
a.tail(6)表示显示后6行数据,若tail()中不带参数则也会显示全部数据。
2.查看DataFrame的index,columns以及values
a.index ; a.columns ; a.values 即可
3.describe()函数对于数据的快速统计汇总
a.describe()对每一列数据进行统计,包括计数,均值,std,各个分位数等。
4.对数据的转置
a.T
5.对轴进行排序
a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
6.对DataFrame中的值排序
a.sort(columns='x')
即对a中的x这一列,从小到大进行排序。注意仅仅是x这一列,而上面的按轴进行排序时会对所有的columns进行操作。
二、选择对象
1.选择特定列和行的数据
a['x'] 那么将会返回columns为x的列,注意这种方式一次只能返回一个列。a.x与a['x']意思一样。
取行数据,通过切片[]来选择
如:a[0:3] 则会返回前三行的数据。
2.通过标签来选择
a.loc['one']则会默认表示选取行为'one'的行;
a.loc[:,['a','b'] ] 表示选取所有的行以及columns为a,b的列;
a.loc[['one','two'],['a','b']] 表示选取'one'和'two'这两行以及columns为a,b的列;
a.loc['one',''a]与a.loc[['one'],['a']]作用是一样的,不过前者只显示对应的值,而后者会显示对应的行和列标签。
3.通过位置来选择
这与通过标签选择类似
a.iloc[1:2,1:2] 则会显示第一行第一列的数据;(切片后面的值取不到)
a.iloc[1:2] 即后面表示列的值没有时,默认选取行位置为1的数据;
a.iloc[[0,2],[1,2]] 即可以自由选取行位置,和列位置对应的数据。
4.使用条件来选择
使用单独的列来选择数据
a[a.c>0] 表示选择c列中大于0的数据
使用where来选择数据
a[a>0] 表直接选择a中所有大于0的数据
使用isin()选出特定列中包含特定值的行
a1=a.copy()
a1[a1['one'].isin(['2','3'])] 表显示满足条件:列one中的值包含'2','3'的所有行。
三、设置值(赋值)
赋值操作在上述选择操作的基础上直接赋值即可。
例a.loc[:,['a','c']]=9 即将a和c列的所有行中的值设置为9
a.iloc[:,[1,3]]=9 也表示将a和c列的所有行中的值设置为9
同时也依然可以用条件来直接赋值
a[a>0]=-a 表示将a中所有大于0的数转化为负值
四、缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中。
1.reindex()方法
用来对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝。
a.reindex(index=list(a.index)+['five'],columns=list(b.columns)+['d'])
a.reindex(index=['one','five'],columns=list(b.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd data={
'date':pd.date_range('',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=pd.DataFrame(data)
#print(a)
b=a.groupby('gender').size()
c=a.groupby('gender').sum()
print(c)
print(b)
输出的结果为:
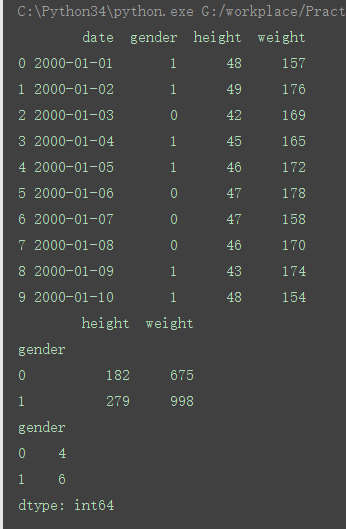
所有grouby是以里面的参数为标准,去分组,然后去统计相对应的数量
比如:
b=a.groupby('gender').size()
是统计以gender类型的个数
而:
c=a.groupby('gender').sum()
是统计以gender类型的其他属性的个数
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
b=a.groupby(level=0).size()
c=a.groupby(level=0).sum()
输出结果为:
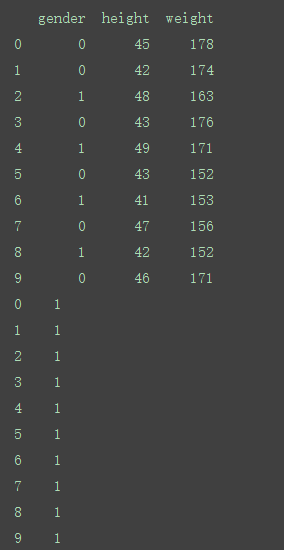
即按index分组并求和,就是根据前面的行号进行分组,得出来的数据
由上图可知:如果是sum的话,就只是列出具有数值型的数据出来,如果是size的话,就是列出每一列的个数出来。
其还有mean()的方法
如果有必要,其实就是原理就是对哪个类型,进行以谁为分组,然后进行统计该数值得和或者是平均值都可以。
如果是对进行分组的类别进行计算大小的话,就是使用.size()的方法。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定其实日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
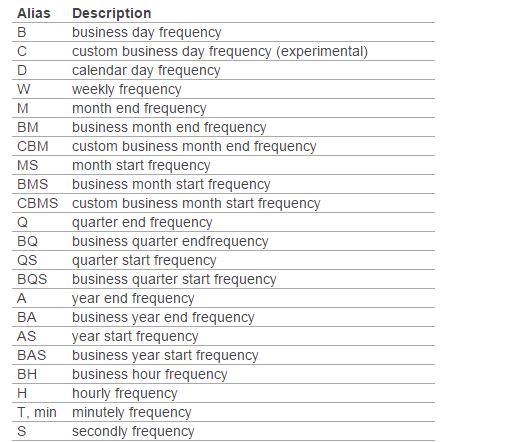
pandas进行数据分析需要的一些操作的更多相关文章
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- 基于 Python 和 Pandas 的数据分析(1)
基于 Python 和 Pandas 的数据分析(1) Pandas 是 Python 的一个模块(module), 我们将用 Python 完成接下来的数据分析的学习. Pandas 模块是一个高性 ...
- Python 数据分析:让你像写 Sql 语句一样,使用 Pandas 做数据分析
Python 数据分析:让你像写 Sql 语句一样,使用 Pandas 做数据分析 一.加载数据 import pandas as pd import numpy as np url = ('http ...
- 万字长文,Python数据分析实战,使用Pandas进行数据分析
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
- 基于 Python 和 Pandas 的数据分析(4) --- 建立数据集
这一节我想对使用 Python 和 Pandas 的数据分析做一些扩展. 假设我们是亿万富翁, 我们会想要多元化地进行投资, 比如股票, 分红, 金融市场等, 那么现在我们要聚焦房地产市场, 做一些这 ...
- python 抓取金融数据,pandas进行数据分析并可视化系列 (一)
终于盼来了不是前言部分的前言,相当于杂谈,算得上闲扯,我觉得很多东西都是在闲扯中感悟的,比如需求这东西,一个人只有跟自己沟通好了,总结出某些东西了,才能更好的和别人去聊,去说. 今天这篇写的是明白需求 ...
- 基于 Python 和 Pandas 的数据分析(3) --- 输入/输出 基础
这一节, 我们要讨论 Pandas 的输入与输出, 并且应用在现实的实际例子中. 为了得到大量的数据, 向大家推荐一个网站 Quandl. Quandl 有很多免费和付费的资源. 这个网站最大的优势在 ...
- pandas:数据分析
一.介绍 pandas是一个强大的Python数据分析的工具包,是基于NumPy构建的. 1.主要功能 具备对其功能的数据结构DataFrame.Series 集成时间序列功能 提供丰富的数学运算和操 ...
随机推荐
- HDU-4518 吉哥系列故事——最终数 AC自动机+数位DP
题意:如果一个数中的某一段是长度大于2的菲波那契数,那么这个数就被定义为F数,前几个F数是13,21,34,55......将这些数字进行编号,a1 = 13, a2 = 21.现给定一个数n,输出和 ...
- postgresql如何实现group_concat功能
MySQL有个聚集函数group_concat, 它可以按group的id,将字段串联起来,如 表:id name---------------1 A2 B1 B SELECT id, group_c ...
- PLSQL Developer连接远程Oracle方法(非安装客户端)
Oracle比较麻烦,通常需要安装oracle的客户端才能实现.通过instantclient可以比较简单的连接远程的Oracle. 1.新建目录D:\Oracle_Cleint用于存放相关文件,新建 ...
- JavaScript的事件对象_其他属性和方法
在标准的 DOM 事件中,event 对象包含与创建它的特定事件有关的属性和方法.触发的事件类型不一样,可用的属性和方法也不一样. 在这里,我们只看所有浏览器都兼容的属性或方法.首先第一个我们了解一下 ...
- @responseBody注解的使用
1. @responseBody注解的作用是将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML 数 ...
- JS 的子父级页面调用
window.frames["iframevehquery"].add(); // 父页面调用嵌套子页面的js函数, iframevehquery 为 iframe 的name值, ...
- hiho_1048_状态压缩2
题目大意 用1x2的单元拼接出 NxM的矩形,单元可以横放或者纵放,N < 1000, M <= 5. 求不同的拼接方案总数. 分析 计算机解决问题的基本思路:搜索状态空间.如果采用dfs ...
- js文字上下滚动代码
<div id="dome"> <div id="dome1"> <ul class="express"> ...
- sqlserver计算表使用大小sql
) create table #spt_space ( ) null, [rows] int null, ) null, ) null, ) null, ) null ) set nocount on ...
- R语言与正态性检验
1.Kolmogorov-Smirnov正态性检验 Kolmogorov-Smirnov是比较一个频率分布f(x)与理论分布g(x)或者两个观测值分布的检验方法,若两者间的差距很小,则推论该样本取自某 ...