Lucene分页-----SearcherAfter
/**
* 分页,SearcherAfter
* @param query
* @param pageIndex
* @param pageSize
*/
public void searchPageByAfter(String query,int pageIndex,int pageSize){
try {
IndexSearcher indexSearcher = getSearcher();
QueryParser parser = new QueryParser("content", new StandardAnalyzer());
Query q = parser.parse(query);
//获取上一页的最后一个元素
ScoreDoc lastScoreDoc = getLastScoreDoc(pageIndex, pageSize, q, indexSearcher);
//通过最后一个元素搜索下页的pageSize个元素
TopDocs topDocs = indexSearcher.searchAfter(lastScoreDoc,q,pageSize);
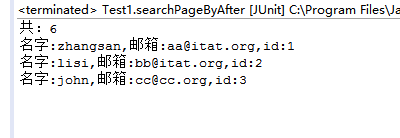
System.out.println("共:"+topDocs.totalHits);
for (ScoreDoc item : topDocs.scoreDocs) {
Document doc = indexSearcher.doc(item.doc);
System.out.println("名字:" + doc.get("name") + ",邮箱:" + doc.get("email") + ",id:" + doc.get("id"));
}
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}finally{
try {
directory.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
测试:
@Test
public void searchPageByAfter(){
SearchUtil util = new SearchUtil();
util.searchPageByAfter("like",1,3);
}

Lucene分页-----SearcherAfter的更多相关文章
- Lucene 分页搜索实现
Lucene中有两种分页查询方式 1.一次查询出大量数据,然后根据页码定位是哪个文档,其实就是暴力获取了 2.通过调用searchAfter来实现 我们都知道collect是lucene中对搜索到的文 ...
- 关于Lucene分页标准
public IEnumerable<SearchResult> Search(string keyword, string[] fieldNames, int pageSize, int ...
- Lucene查询索引(分页)
分页查询只需传入每页显示记录数和当前页就可以实现分页查询功能 Lucene分页查询是对搜索返回的结果进行分页,而不是对搜索结果的总数量进行分页,因此我们搜索的时候都是返回前n条记录 package c ...
- lucene 查询+分页+排序
lucene 查询+分页+排序 1.定义一个工厂类 LuceneFactory 1 import java.io.IOException; 2 3 import org.apache.lucene.a ...
- 谈谈个人网站的建立(二)—— lucene的使用
首先,帮忙点击一下我的网站http://www.wenzhihuai.com/ .谢谢啊,如果可以,GitHub上麻烦给个star,以后面试能讲讲这个项目,GitHub地址https://github ...
- lucene4.7学习总结
花了一段时间学习lucene今天有时间把所学的写下来,网上有很多文章但大部分都是2.X和3.X版本的(当前最新版本4.9),希望这篇文章对自己和初学者有所帮助. 学习目录 (1)什么是lucene ( ...
- lucene4.7学习总结 (zhuan)
http://blog.csdn.NET/mdcmy/article/details/38167955?utm_source=tuicool&utm_medium=referral ***** ...
- lucene两个分页操作
基于lucene两个分页: lucene3.5查询方式(每次查询所有记录,然后取当中部分记录.这样的方式用的最多),lucene官方的解释:因为我们的速度足够快. 处理海量数据时.内存easy内存溢出 ...
- lucene的两种分页操作
基于lucene的分页有两种: lucene3.5之前分页提供的方式为再查询方式(每次查询全部记录,然后取其中部分记录,这种方式用的最多),lucene官方的解释:由于我们的速度足够快.处理海量数据时 ...
随机推荐
- selenium webdriver(1)---浏览器操作
启动浏览器 如何启动浏览器已在上篇文章中说明,这里还是以chrome为例,firefox.IE启动方式相同. //启动浏览器 import org.openqa.selenium.WebDriver; ...
- Qt学习之路(2)------Qt中的字符串类
QString QString的一些基本用法 basic.cpp #include <QTextStream> int main(void) { QTextStream out(stdou ...
- Python初始值表示为无穷大
之前只知道设置变量的初始值为0.今天在写网络路径分析的时候,为了找到离任意坐标距离最近的节点,初始设置最短距离为无穷大,然后不断的去替换,直到找到最近的节点. 刚开始设置是min_dis = 9999 ...
- 借助bool判断使冒泡排序效率提高
排序问题是编程中最常见的问题.实际应用中,计算机有接近一半时间是在处理有关数据排列的问题,提高排序的效率有助于更快地解决问题. 先来说说平常一般的冒泡算法,使用两个循环,外循环作为整体排序,每趟循环使 ...
- hdu 4758 Walk Through Squares
AC自动机+DP.想了很久都没想出来...据说是一道很模板的自动机dp...原来自动机还可以这么跑啊...我们先用两个字符串建自动机,然后就是建一个满足能够从左上角到右下角的新串,这样我们直接从自动机 ...
- Stackdump: 一个可以离线看stackoverflow的工具
博客搬到了fresky.github.io - Dawei XU,请各位看官挪步.最新的一篇是:Stackdump: 一个可以离线看stackoverflow的工具.
- Windows操作系统的历史
30 years ago Windows was first released, see how much it has changed回顾了Windows操作系统的历史. 1985, Windows ...
- LCD深度剖析
LCD 深度剖析 来源:http://blog.csdn.net/hardy_2009/article/details/6922900 http://blog.csdn.net/jaylondon/a ...
- 深入了解当前ETL中用到的一些基本技术
数据集成是把不同来源.格式和特点的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享,是企业商务智能.数据仓库系统的重要组成部分.ETL是企业数据集成的概念出发,简要分析了当前ETL中用到的 ...
- PAT---1050. String Subtraction (20)
#include<iostream> #include<string.h> #include<stdio.h> using namespace std; #defi ...