Hadoop入门学习整理(二)
2020-04-15
在上一篇文章中介绍了Linux虚拟机的安装,Hadoop的安装和配置,这里接着上一篇的内容,讲Hadoop的简要介绍和简单使用, 以及HBase的安装和配置。
1、首先要了解Hadoop的目录:
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
2、了解Hadoop的运行模式:
Hadoop包括3种安装模式
(1)单机模式。只在一台机器上运行,存储采用本地文件系统,没有采用分布式文件系统HDFS
(2)伪分布式模式。存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上
(3)分布式模式。存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
在Linux虚拟机中安装完Hadoop后默认为单机模式,无需进行其它配置即可运行。
我个人在目前的学习当中,采用伪分布式模式。
若想让 Hadoop在伪分布式模式下顺利运行,则需要配置相关文件。
伪分布式模式:
Hadoop可以在单个节点(一台机器)上以伪分布式的方式运行,同一个节点既作为名称节点( Name Node),
也作为数据节点( Data Node),读取的是分布式文件系统HDFS中的文件。
3、伪分布式模式的配置修改
Hadoop的配置文件位于hadoop/etc/ hadoop/中,进行伪分布式模式配置时,需要修改2个配置文件,即 core-site.xml和 hdfs-site.xml。
可以使用vim编辑器打开 core-site.xml文件。
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[guan@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置:core-site.xml
|
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> |
(c)配置:hdfs-site.xml
|
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> |
修改配置文件以后,要执行名称节点的格式化,命令如下:
[guan@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
【注】第一次启动时格式化,以后就不要总格式化。
我在格式化的过程中出现了以下错误:

原因是没有配置主机名称映射。解决办法:进入/etc/hosts,然后:

再次格式化,成功。
如果要格式化,那么需要在格式化之前:
(1、查看NameNode和DataNode进程是否关掉。(必须关掉)
关闭命令: sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
(2、将/data和/logs删掉
(3、格式化NameNode
4、启动伪分布式集群
(a)启动NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
(b)启动DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
(c)查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
启动集群也可以群起: sbin/start-dfs.sh
5.使用Web界面查看HDFS信息
Hadoop成功启动后,可以在 Linux系统中(不是 Windows系统)打开一个浏览器,
在地址栏输入地址http://localhost:50070 就可以查看名称节点和数据节点信息,还可以在线查看HDFS中的文件。
6、遇到bug时,可以查看产生的日志。具体方法如下:

7、关闭Hadoop
执行命令 /sbin/stop-dfs.sh
接下来是HBase的安装和使用。
( 具体参考 厦门大学大数据实验室 https://dblab.xmu.edu.cn/blog/install-hbase/)
其实HBase的安装非常简单,先下载 tar 包传输到Linux系统中,然后解压,配置环境变量,这样就好了,和前面的Hadoop安装差不多。
HBase也有三种运行模式:单机模式、伪分布式模式和分布式模式,也是通过修改配置文件来选择模式的。
但是注意,HBase的配置有以下先决条件:
- jdk
- Hadoop(单机模式不需要,伪分布式和分布式需要)
- SSH
其中SSH的配置参考 :https://blog.csdn.net/lixufei12138/article/details/102556824
接下来就是修改配置文件,按照上面链接的内容即可,这里不做过多的赘述。
这里放一张环境变量的截图,图中顺带有我安装的版本信息。

还是写一下HBase 伪分布式配置:
(1)配置 /opt/module/hbase-1.3.1/conf/hbase-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_CLASSPATH=/opt/module/hadoop-2.7.2/etc/hadoop
export HBASE_MANAGES_ZK=true
(2)配置/opt/module/hbase-1.3.1/conf/hbase-site.xml
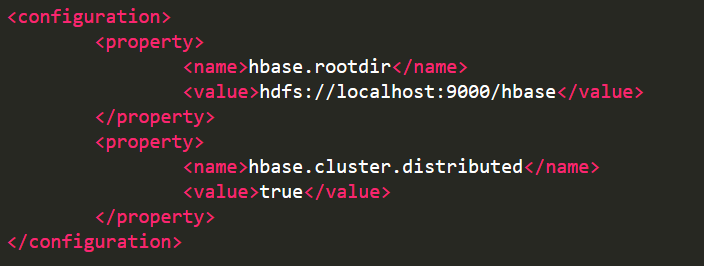
接下来就可以登录SSH,启动Hadoop,启动HBase
Hadoop的启动方式为 ./sbin/start-dfs.sh
Hbase 的启动方式为 bin/start-hbase.sh
输入jps查看是否启动成功,看到一下界面说明hbase启动成功

hbase进入shell界面的命令:
bin/hbase shell
注:Linux中安装eclipse的方式 https://blog.csdn.net/caoyang0105/article/details/77948145
Hadoop入门学习整理(二)的更多相关文章
- Hadoop入门学习整理(一)
今天是2020年4月8日,是一个平凡而又特殊的日子,武汉在经历了77天的封城之后,于今日0点正式解封.从1月14日放寒假离开武汉,到今天已近3个月,学校的花开了又谢了.随着疫情好转,春回大地,万物复苏 ...
- hadoop入门学习整理
技术性网站 1.http://dongxicheng.org/ 2.http://www.iteblog.com/ 3.http://www.cnblogs.com/shishanyuan/p/414 ...
- Hadoop入门学习整理(三)
1.Hive 的安装 下载tar包,并且要注意和Hadoop版本兼容. 下载 -----> 传输 -------> 解压 即可. 然后配置环境变量和相关配置信息. 参考: ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- hadoop入门学习
hadoop入门学习:http://edu.csdn.net/course/detail/1397hadoop hadoop2视频:http://pan.baidu.com/s/1o6uy7Q6HDF ...
- 【转载】salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句
salesforce 零基础开发入门学习(二)变量基础知识,集合,表达式,流程控制语句 salesforce如果简单的说可以大概分成两个部分:Apex,VisualForce Page. 其中Apex ...
随机推荐
- 后端程序员必备的 Linux 基础知识+常见命令(近万字总结)
大家好!我是 Guide 哥,Java 后端开发.一个会一点前端,喜欢烹饪的自由少年. 今天这篇文章中简单介绍一下一个 Java 程序员必知的 Linux 的一些概念以及常见命令. 如果文章有任何需要 ...
- Windows下的Minio启动命令
1.首先安装Minio到你的 Windows系统的盘符中,例如D盘 2. 打开dos命令行,进入存放minio.exe的文件夹下,输入 minio.exe server /data 命令,意味着启动 ...
- ms14-064漏洞复现
本博客最先发布于我的个人博客,如果方便,烦请移步恰醋的小屋查看,谢谢您! 这是我在实验室学习渗透测试的第五个漏洞复现,一个多小时便完成了.学长给的要求只需完成查看靶机信息.在指定位置创建文件夹两项操作 ...
- int ,long , long long , __int64类型的范围
首先见测试代码(在g++/gcc下运行): #include<iostream> using namespace std; int main() { cout<<sizeof( ...
- java实现高斯平滑
高斯模糊也叫作高斯平滑,这里主要用来实现图像降噪.官方有入门教程:http://opencv-java-tutorials.readthedocs.io/en/latest/ 实现代码如下: pack ...
- Python之运维
这几日一直研究运维监控的事情,有次看见有一个脚本写的还不错,如今已经找不到地址了 就只能用Python代替shell了 其中原理是 监控 /proc/下的各种文件,/proc/ 顾名思义其为进程的文件 ...
- Bagging与随机森林(RF)算法原理总结
Bagging与随机森林算法原理总结 在集成学习原理小结中,我们学习到了两个流派,一个是Boosting,它的特点是各个弱学习器之间存在依赖和关系,另一个是Bagging,它的特点是各个弱学习器之间没 ...
- 软工团队项目之团队展示&选题(OnTime——S.L.N)
软工团队项目之团队展示&选题(OnTime——S.L.N) 一.团队展示 队名:『S.L.N』即Seigelion——乃“攻城狮”之意. 队员学号: 团队项目描述:(项目名称:OnTime) ...
- Vue 构造选项 - 进阶
Directive指令:减少DOM操作的重复 Vue实例/组件用于数据绑定.事件监听.DOM更新 Vue指令主要目的就是原生DOM操作 减少重复 自定义指令 两种声明方式 方法一:声明一个全局指令 V ...
- 牛客网PAT练兵场-打印沙漏
题目地址:https://www.nowcoder.com/pat/6/problem/4053 题意:模拟题 /** * Copyright(c) * All rights reserved. * ...