pandas 数据子集的获取
有时数据读入后并不是对整体数据进行分析,而是数据中的部分子集,例如,对于地铁乘客量可能只关心某些时间段的流量,对于商品的交易可能只需要分析某些颜色的价格变动,对于医疗诊断数据可能只对某个年龄段的人群感兴趣等。所以,该如何根据特定的条件实现数据子集的获取将是本节的主要内容。
通常,在pandas模块中实现数据框子集的获取可以使用iloc,loc和ix三种‘方法’,这三种方法既可以对数据进行筛选,也可以实现变量的挑选,它们的语法可以表示
成【row_select,cols_select】.
iloc只能通过行号和列号进行数据筛选,我们可以将iloc中的‘i’理解为“integer”,即只能向【rows_select,cols_select】指定整数列表。该索引方式与数组的索引方式类似,都是从0开始,可以间隔取号,对于切片仍然无法取到上限。
loc要比iloc灵活一些,读者可以将loc中的“1”理解为“label”,即可以向【rows_select,col_select】指定具体的行标签和列标签。注意,这里是标签不再是索引。而且,还可以将rows_select指定为具体的筛选条件,在iloc中是无法做到的。
ix是iloc和loc的混合,读者可以将ix理解为“mix”,该方法吸收了iloc和loc的优点,市数据库子集的获取更加灵活。(此方法忽略,最新的模块好像已经去掉了,编译的时候警告,待再验证)
如下用具体的代码来说明iloc和loc二者之间的差异:
import pandas as pd
df1 = pd.DataFrame({'name':['张三','李四','王二','丁一','李五'],
'gender':['男','女','女','女','男'],
'age':[23,26,22,25,27]},columns = ['name','gender','age'])
df1
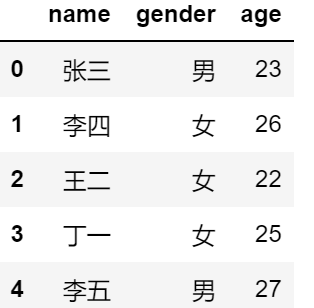
#去除数据集的中间三行(所有女性),并且返回姓名和年龄两列
df1.iloc[1:4,[0,2]]
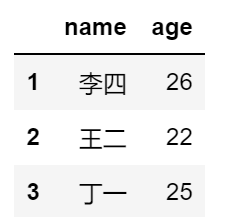
df1.loc[1:3,['name','age']]
# df1.ix[1:3,[0,2]]
out:

再继续研究,将员工的姓名用做行标签
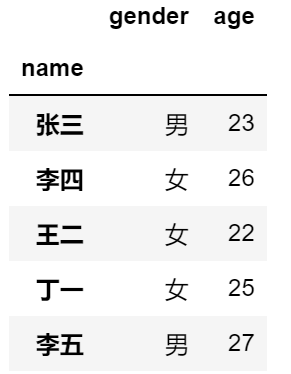
#将员工的姓名用作行标签
df2 = df1.set_index('name')
df2
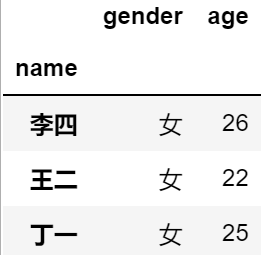
#同样取出数据集的中间三行
df2.iloc[1:4,:]
df2.loc[['李四','王二','丁一'],:]
out:

很显然,在实际的学习和工作中,观测行的筛选很少是通过写入具体的行索引或行标签,而是对某些列做条件筛选,进而获得目标数据.例如,在上面的df1数据集中,如何返回所有男性的姓名和年龄,代码如下:
df1.loc[df1.gender == '男',['name','age']]
out:
pandas 数据子集的获取的更多相关文章
- 利用pandas进行数据子集的获取
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- pandas数据操作
pandas数据操作 字符串方法 Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素 t = pd.Series(['a_b_c_d','c_d_e',np. ...
- Python使用Flask框架,结合Highchart处理csv数据(引申-从文件获取数据--从数据库获取数据)
参考链接:https://www.highcharts.com.cn/docs/process-text-data-file 1.javascript代码 var options = { chart: ...
- pandas数据读取(DataFrame & Series)
1.pandas数据的读取 pandas需要先读取表格类型的数据,然后进行分析 数据说明 说明 pandas读取方法 csv.tsv.txt 用逗号分割.tab分割的纯文本文件 pd.read_csv ...
- Qt之界面数据存储与获取(使用setUserData()和userData())
在GUI开发中,往往需要在界面中存储一些有用的数据,这些数据可以来配置文件.注册表.数据库.或者是server. 无论来自哪里,这些数据对于用户来说都是至关重要的,它们在交互过程中大部分都会被用到,例 ...
- R语言学习笔记:取数据子集
上文介绍了,如何生成序列,本文介绍一下如何取出其数据子集 取出元素的逻辑值 > x<-c(0,-3,4,-1,45,90,5) > x>0 [1] FALSE FALSE T ...
- 数据分析与展示——Pandas数据特征分析
Pandas数据特征分析 数据的排序 将一组数据通过摘要(有损地提取数据特征的过程)的方式,可以获得基本统计(含排序).分布/累计统计.数据特征(相关性.周期性等).数据挖掘(形成知识). .sort ...
- pandas小记:pandas数据输入输出
http://blog.csdn.net/pipisorry/article/details/52208727 数据输入输出 数据pickling pandas数据pickling比保存和读取csv文 ...
随机推荐
- pagehelper的使用和一些坑!
[toc] ##1.1 pagehelper介绍和使用 PageHelper是一款好用的开源免费的Mybatis第三方物理分页插件. 原本以为分页插件,应该是很简单的,然而PageHelper比我想象 ...
- bzoj 题目选做
这里将记录着我在接下来的日子里在bzoj上遇到的各种 毒瘤题目 1.轮状病毒 题目是很没意思的 列出状态 显然无法递推 我简单推了一下加动态加点的状态 嗯发现规律没有那么简单 打表 也不太能发现吧 正 ...
- 【FZYZOJ】「Paladin」瀑布 题解(期望+递推)
题目描述 CX在Minecraft里建造了一个刷怪塔来杀僵尸.刷怪塔的是一个极高极高的空中浮塔,边缘是瀑布.如果僵尸被冲入瀑布中,就会掉下浮塔摔死.浮塔每天只能工作 $t$秒,刷怪笼只能生成 $N$ ...
- QString字符串的查找与截取实例
QString是Qt中封装的字符串类,相对于标准库里的string,使用方法有些不同,个人感觉使用qt习惯后,感觉QString更好用,下面的代码主要是针对QString的字符查找.截取做的测试: # ...
- Java实现短信验证码
前言 本人使用的是阿里短信服务,一开始尝试了许多不同的第三方短信服务平台,比如秒滴科技.梦网云通讯.当初开始为什么会选择这两个,首先因为,他们注册就送10元钱(#^.^#),但是后来却发现他们都需要认 ...
- Python初学者的自我修养,找到自己的方向
今天是 Python专题 的第22篇文章,原本今天是准备和大家继续Python当中多线程的使用的相关内容.然而前两天有一个读者在后台问我,学习Python有哪些适合新手入门的小项目推荐,所以今天这篇临 ...
- JavaScript按位运算符~
1. JavaScript按位运算符 Bit operators work on 32 bits numbers. 2. JavaScript按位运算符~ 值得注意的是,在JavaScript中,~5 ...
- one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [3, 1280, 28, 28]], which is output 0 of LeakyReluBackward1, is at version 2;
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace o ...
- MySQL“被动”性能优化汇总!
年少不知优化苦,遇坑方知优化难. --村口王大爷 本文内容导图如下: 我之前有很多文章都在讲性能优化的问题,比如下面这些: <switch 的性能提升了 3 倍,我只用了这一招!> < ...
- docker,容器,编排,和基于容器的系统设计模式
目录 从容器说起 背景 docker实现原理 编排之争 基于容器的分布式系统设计之道 单节点协作模式 Sidecar pattern(边车模式) Ambassador pattern(外交官模式) A ...