记一次SqlServer大表查询语句优化和执行计划分析
数据库: sqlserver2008r2
表: device_data
数据量:2000w行左右
表结构
CREATE TABLE [dbo].[device_data](
[Id] [int] IDENTITY(1,1) NOT NULL,
[DeviceId] [nvarchar](30) NOT NULL,
[CollectCycle] [int] NOT NULL,
[BroadcastCycle] [int] NOT NULL,
[Behavior] [tinyint] NOT NULL,
[SystemTick] [int] NOT NULL,
[Sport] [int] NOT NULL,
[SportTime] [int] NOT NULL,
[SleepTime] [int] NOT NULL,
[Temperature] [int] NOT NULL,
[Voltage] [int] NOT NULL,
[DeviceSatatus] [int] NOT NULL,
[DeviceType] [int] NOT NULL,
[FireVersion] [int] NOT NULL,
[SportRange] [int] NOT NULL,
[UploadTime] [datetime] NOT NULL,
[DataFlag] [tinyint] NOT NULL,
[TagType] [tinyint] NOT NULL,
[RSSI] [tinyint] NOT NULL,
[CollectorMac] [nvarchar](20) NOT NULL,
CONSTRAINT [PK__device_d__3214EC0770FDBF69] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
索引情况:分别有两个联合索引
idx_deviceid(DeviceId,UploadTime)
idx_collector(CollectorMac,UploadTime)
问题:这张表上传的数据都是随上传时间递增,批量有序插入进去。但是 最近几天日志经常出现插入数据超时,然后去分析了一下数据库,发现对外接口出现了慢 sql导致了死锁,
慢sql是where条件在某些情况下没有加上时间筛选过滤,2000万的表导致非常慢,于是进行了优化,优化的时候变出现了下面的两条sql语句
这两个索引对应着两个接口 查询语句分别是:
select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data
where [DeviceId]='C9C810B18272' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc;
和
select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data
where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc;
现在遇到一个情况是 相同的where条件下 如果我Order by Id Desc 就会发现返回结果中会比order by UploadTime desc慢一点,我一开始不太理解为啥会出现这个情况。
于是想到了sqlserver的查询分析器来分析一下具体的sql执行计划
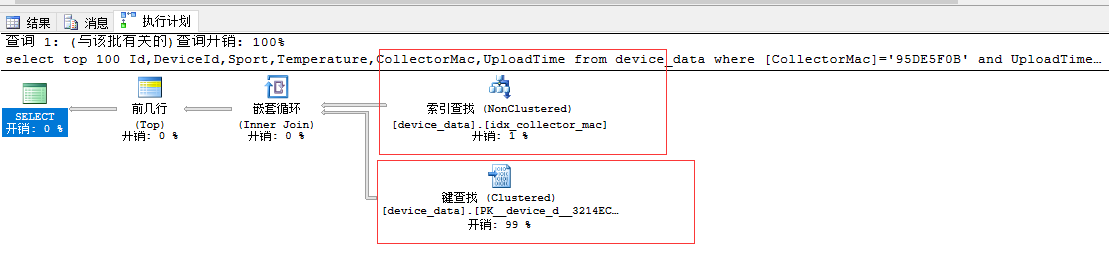
1,首先我来执行order by UploadTime desc的语句来看一下具体的执行计划
dbcc dropcleanbuffers
set statistics io on
select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data
where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc;
set statistics io off
具体执行计划为:
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 (100 行受影响)
表 'device_data'。扫描计数 1,逻辑读取 1899 次,物理读取 5 次,预读 24 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
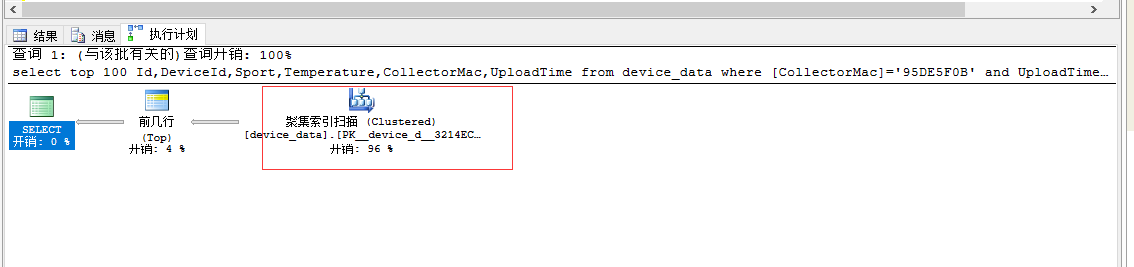
2,再来看一下order by Id desc的具体执行计划
dbcc dropcleanbuffers
set statistics io on
select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data
where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by Id desc;
set statistics io off
具体执行计划为:
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 (100 行受影响)
表 'device_data'。扫描计数 1,逻辑读取 40 次,物理读取 36 次,预读 4942 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
这里先说一下逻辑读取和物理读取等区别
那么,这几个词语代表什么意思呢?我们怎么根据这些来了解SQL语句或者存储过程的I/O过程呢?
预读:用于估计信息,去硬盘读取数据到缓存。
物理读:查询计划生成以后,如果发现缓存缺少所需要的数据,让缓存再次去读硬盘数据。如果内存里没有缓存数据或者执行计划(如果SQL语句发生了改变,
那么执行计划将不能重用,需要重新生成新的执行计划),那么SQLSERVER就要去硬盘读取这些数据,这个时候就是物理读取,我们大家都知道,硬盘速度
与内存速度根本不在一个数量级上,所以物理读是比较慢的。
逻辑读:SQLSERVER去内存里的缓存取数据或者执行计划,所以逻辑读是比较快的。
SQLSERVER存储的最小单位是页,每一页大小为8K,即8*1024=8192字节,SQLSERVER对页的读取是原子性的,即要么读完一页,要么完全不读。即使
仅仅要获得一条数据,也要读完该页,而页之间的数据组织结构为B树结构。所以SQLSERVER对于逻辑读,物理读,预读的单位是页。
可以看到bytime 走的是索引查找和键查找 并且大部分读取走的是逻辑读取
byid 走的是聚集索引扫描,并且大部分读取走的是预读取
看上面的介绍我们发现 逻辑读取走的是内存缓存,预读取是去硬盘读取数据到缓存然后再逻辑读取,在这一步我们基本确定了 byid慢的原因是读取了硬盘数据。
那么上图出现的索引查找和索引扫描这两者又有什么区别呢
查看了相关资料发现
Clustered Index Scan(聚集索引扫描)、Index Scan(非聚集索引扫描)

聚集索引扫描:聚集索引的数据体积实际是就是表本身,也就是说表有多少行多少列,聚集所有就有多少行多少列,那么聚集索引扫描就跟表扫描差不多,也要进行全表扫描,遍历所有表数据,查找出你想要的数据。
非聚集索引扫描:非聚集索引的体积是根据你的索引创建情况而定的,可以只包含你要查询的列。那么进行非聚集索引扫描,便是你非聚集中包含的列的所有行进行遍历,查找出你想要的数据。
Clustered Index Seek(聚集索引查找)、Index Seek(非聚集索引查找)

聚集索引查找和非聚集索引查找都是使用该图标。
聚集索引查找:聚集索引包含整个表的数据,也就是在聚集索引的数据上根据键值取数据。
非聚集索引查找:非聚集索引包含创建索引时所包含列的数据,在这些非聚集索引的数据上根据键值取数据。
Key Lookup(键值查找)

首先需要说的是查找,查找与扫描在性能上完全不是一个级别的,扫描需要遍历整张表,而查找只需要通过键值直接提取数据,返回结果,性能要好。
当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
我们发现byid引起全量扫描了 所以会慢很多
疑问:我的理解是既然我已经加了where条件去筛选数据了 order by Id还是 order by Uploadtime 是不是应该在我where筛选出来的数据中再去排序,为啥只是因为Orderby的不同,最终的执行计划差别这么大
我对理论方面不深入,只能从现象来解决问题,还请大佬们赐教
参考资料:
T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
MSSQLSERVER执行计划详解
记一次SqlServer大表查询语句优化和执行计划分析的更多相关文章
- MySQL 表查询语句练习题
MySQL 表查询语句练习题: 一. 设有一数据库,包括四个表:学生表(Student).课程表(Course).成绩表(Score)以及教师信息表(Teacher).四个表的结构分别如表1-1的表 ...
- sql查询语句优化
http://www.cnblogs.com/dubing/archive/2011/12/09/2278090.html 最近公司来一个非常虎的dba 10几年的经验 这里就称之为蔡老师吧 在征得 ...
- 转载《mysql 一》:mysql的select查询语句内在逻辑执行顺序
原文:http://www.jellythink.com/archives/924 我的抱怨 我一个搞应用开发的,非要会数据库,这不是专门的数据库开发人员干的事么?话说,小公司也没有数 据库开发人员这 ...
- mysql数据库系统学习(一)---一条SQL查询语句是如何执行的?
本文基于----MySQL实战45讲(极客时间----林晓斌 )整理----->https://time.geekbang.org/column/article/68319 一.第一节:一条sq ...
- php面试专题---MYSQL查询语句优化
php面试专题---MYSQL查询语句优化 一.总结 一句话总结: mysql的性能优化包罗甚广: 索引优化,查询优化,查询缓存,服务器设置优化,操作系统和硬件优化,应用层面优化(web服务器,缓存) ...
- 一文读懂一条 SQL 查询语句是如何执行的
2001 年 MySQL 发布 3.23 版本,自此便开始获得广泛应用,随着不断地升级迭代,至今 MySQL 已经走过了 20 个年头. 为了充分发挥 MySQL 的性能并顺利地使用,就必须正确理解其 ...
- 当程序执行一条查询语句时,MySQL内部到底发生了什么? (说一下 MySQL 执行一条查询语句的内部执行过程?
先来个最基本的总结阐述,希望各位小伙伴认真的读一下,哈哈: 1)客户端(运行程序)先通过连接器连接到MySql服务器. 2)连接器通过数据库权限身份验证后,会先查询数据库缓存是否存在(之前执行过相同条 ...
- SQLServer查询执行计划分析 - 案例
SQLServer查询执行计划分析 - 案例 http://pan.baidu.com/s/1pJ0gLjP 包括学习笔记.书.样例库
- mysql大表设计以及优化
MYSQL千万级数据量的优化方法积累https://m.toutiao.com/group/6583260372269007374/?iid=6583260372269007374 MySQL 千万级 ...
随机推荐
- WindowsServer系统设置U盘引导及安装
准备一台服务器,我的服务器上图. 1.开机启动,按DEL进入BIOS.我的显示如下图,按F7进入. 2.找到设置启动项的地方 3.修改U盘启动项 4.保存退出. 5.重启服务器正常的话应该能够从U盘引 ...
- PHP代码审计分段讲解(1)
PHP源码来自:https://github.com/bowu678/php_bugs 快乐的暑期学习生活+1 01 extract变量覆盖 <?php $flag='xxx'; extract ...
- typora字体与字体颜色
字体 基本格式:\字体信息{内容} 罗马体\rm \rm{罗马体abc}>>\(\rm{罗马体abc}\) 意大利体\it \it{意大利体}>>\(\it{意大利体}\) 等 ...
- nginx转发上传图片接口图片的时候,报错413
我这边有一个接口是上传图片,使用nginx进行代理,上传大一点的图片,直接调用我的接口不会报错,但是调用nginx上传图片就会报错"413 Request Entity Too Large& ...
- eclipse提示JVM版本太低
解决方案:去eclipse的安装路径找到eclipse.ini文件,然后在头部指定JVM的版本(第一第二行) -vm C:/Program Files/Java/jdk-11.0.9/bin -sta ...
- CD租赁售卖系统javaweb系统展示SSM框架
一.功能要点 1.管理员登录 2.用户注册登录 3.用户权限,可以查看可借或可买cd,并实现对cd的买租 4.管理员可以添加cd, 5.cd的类型,价格由管理员设置 二.运行环境 数据库mysql: ...
- JavaSE14-集合·其一
1.Collection集合 1.1 集合体系结构 集合 (接口)Collection:单列 (接口)List:可重复 (实现类)ArrayList (实现类)LinkedList (接口)Set:不 ...
- shell,计算指定行的和,计算指定列的和
有一个文本文件,里面某行某列为数字,那么如何用shell计算指定行(列)的和,方法如下 计算指定行的和: awk 'NR==3{for(i=1;i<=NF;i++)sum=sum+$i;}END ...
- Elastic Search 学习之路(二)——inverted index(反向索引)
这是篇翻译文,图画的挺有意思. Elastic使用非常特殊的数据结构,称作反向索引.反向索引中,包括了一组document中出现的唯一的单词,和对应的单词,所出现的位置.反向索引是在ES中,docum ...
- 牛客挑战赛46 D
题目链接: 数列 查询有多少\([l,r]\)区间满足每个数出现\(k\)的倍数次 即为\(1\)到\(r\)与\(1\)到\(l-1\)每个数相减的次数为\(k\)的倍数次 可以使用哈希维护 记录每 ...