CS224--1:语言模型和词向量
参考:
https://www.cnblogs.com/pinard/p/7243513.html
https://blog.csdn.net/cindy_1102/article/details/88079703
http://web.stanford.edu/class/cs224n/readings/cs224n-2019-notes01-wordvecs1.pdf
1、NLP简介
1.1、什么是自然语言?
用来表示某种意义或东西的符号
1.2、NLP任务
1)、简单
拼写检查
关键词提取
同义词查询
2)、中等
信息抽取
3)、高难
机器翻译
语义分析
指代
问答
2、词向量(word vectors)
2.1、ont-hot
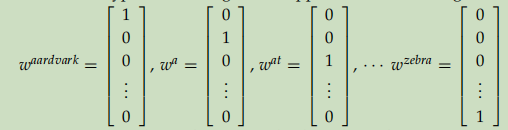

如图,每个词由V维的0,1向量组成,V是词典大小。有以下缺点:
1)、词之间凉凉正交,体现不出诸如男人、女人,中国、日本之间的相关性。
2)、当词典很大时,词向量太大。
那么我们是不是可以找到一种可以以低维的方式且能表示词之间相关性的词向量表示方法呢?
3、基于SVD的方法
4、基于迭代的方法-word2vector
4.1、语言模型
语言模型就是对一个语言序列进行建模。
比如
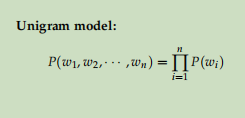
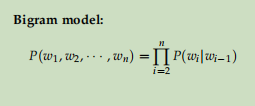
4.2、CBOW
模型思路:一个语言序列,通过某个词其周围的词预测中心词。
符号说明:
- wi : 词典里第i个词
- V : shape: (n, v), 输入的单词矩阵,n代表词向量的维度,v代表词典大小
- vi : V的第i列,shape=(n,1)
- U : shape=(v, n), 输出的单词矩阵
- ui : U的第i行,wi的输出向量表示
模型步骤:
- 对于一个序列,假设某词为x(c),其上下文为x(c-m), ...,x(c-1), x(c+1), ..., x(c+m),将其做one-hot表示
- 通过lookup得到上下文单词的嵌入词向量:v(c-m), v(c-m+1), ..., v(c+m)
- 对上下文词向量求平均:

- 将U与3中得到的向量做点乘,得到一个分。
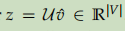
- 对z做softmax进行分类,预测属于哪个词:
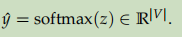
- 定义损失函数,交叉熵损失:

- 根据梯度下降法不断迭代反向传播,直到loss收敛。
模型结构:

4.3、skip-gram model
模型思路:一个序列,通过中心词预测其上下文的词。
符号说明:
- wi : 词典里第i个词
- V : shape: (n, v), 输入的单词矩阵,n代表词向量的维度,v代表词典大小
- vi : V的第i列,shape=(n,1)
- U : shape=(v, n), 输出的单词矩阵
- ui : U的第i行,wi的输出向量表示
模型步骤:
- 得到中心词的one-hot表示
- lookup得到中心词的词向量
- 计算得分:
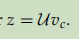
- 根据得分计算softmax, 预测上下文的词:

- 根据4得出的概率,计算预测出的词
- 同样采用交叉熵作为损失函数,此处值得留意的是,预测出的多个上下文单词之间假设是独立的,不因其与中心词的距离而受到影响,因此loss可以这么计算:

- 使用随机梯度下降法优化loss, 直到loss收敛。
模型结构:
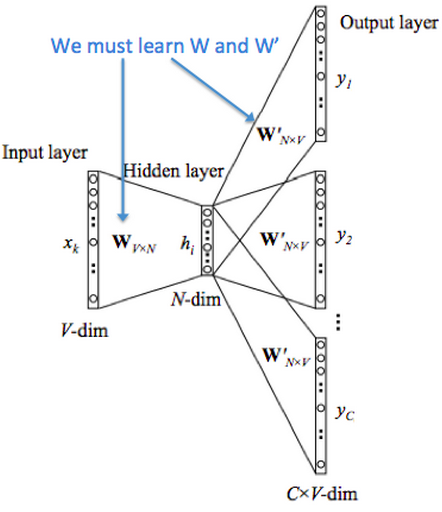
4.4、负采样
4.5、hierarchical softmax
词向量训练的时候,假如说词典的大小为v,那么每次前向传播通常需要进行v次的点击运算,然后算出每个词的概率,非常耗时。
这里采用了两个方法减少计算,一个是把词向量进来后经过线性运算通常会加的非线性激活函数给去掉,换成求平均值。第二个就是把词分类的softmax换成一颗二叉霍夫曼树。

和之前的神经网络语言模型相比,我们的霍夫曼树的所有内部节点就类似之前神经网络隐藏层的神经元,其中,根节点的词向量对应我们的投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。在霍夫曼树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成的,因此这种softmax取名为"Hierarchical Softmax"。
如何“沿着霍夫曼树一步步完成”呢?在word2vec中,我们采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(霍夫曼树编码1),沿着右子树走,那么就是正类(霍夫曼树编码0)。判别正类和负类的方法是使用sigmoid函数,即:

其中xwxw是当前内部节点的词向量,而θθ则是我们需要从训练样本求出的逻辑回归的模型参数。
使用霍夫曼树有什么好处呢?首先,由于是二叉树,之前计算量为VV,现在变成了log2Vlog2V。第二,由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到,这符合我们的贪心优化思想。
CS224--1:语言模型和词向量的更多相关文章
- Deep Learning In NLP 神经网络与词向量
0. 词向量是什么 自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化. NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representati ...
- 第一节——词向量与ELmo(转)
最近在家听贪心学院的NLP直播课.都是比较基础的内容.放到博客上作为NLP 课程的简单的梳理. 本节课程主要讲解的是词向量和Elmo.核心是Elmo,词向量是基础知识点. Elmo 是2018年提出的 ...
- NLP直播-1 词向量与ELMo模型
翻车2次,试水2次,今天在B站终于成功直播了. 人气11万. 主要讲了语言模型.词向量的训练.ELMo模型(深度.双向的LSTM模型) 预训练与词向量 词向量的常见训练方法 深度学习与层次表示 LST ...
- PyTorch基础——词向量(Word Vector)技术
一.介绍 内容 将接触现代 NLP 技术的基础:词向量技术. 第一个是构建一个简单的 N-Gram 语言模型,它可以根据 N 个历史词汇预测下一个单词,从而得到每一个单词的向量表示. 第二个将接触到现 ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- word2vec生成词向量原理
假设每个词对应一个词向量,假设: 1)两个词的相似度正比于对应词向量的乘积.即:$sim(v_1,v_2)=v_1\cdot v_2$.即点乘原则: 2)多个词$v_1\sim v_n$组成的一个上下 ...
- 学习笔记CB009:人工神经网络模型、手写数字识别、多层卷积网络、词向量、word2vec
人工神经网络,借鉴生物神经网络工作原理数学模型. 由n个输入特征得出与输入特征几乎相同的n个结果,训练隐藏层得到意想不到信息.信息检索领域,模型训练合理排序模型,输入特征,文档质量.文档点击历史.文档 ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...
- DNN模型训练词向量原理
转自:https://blog.csdn.net/fendouaini/article/details/79821852 1 词向量 在NLP里,最细的粒度是词语,由词语再组成句子,段落,文章.所以处 ...
随机推荐
- Spring集成GuavaCache实现本地缓存
Spring集成GuavaCache实现本地缓存: 一.SimpleCacheManager集成GuavaCache 1 package com.bwdz.sp.comm.util.test; 2 3 ...
- 与图论的邂逅05:最近公共祖先LCA
什么是LCA? 祖先链 对于一棵树T,若它的根节点是r,对于任意一个树上的节点x,从r走到x的路径是唯一的(显然),那么这条路径上的点都是并且只有这些点是x的祖先.这些点组成的链(或者说路径)就是x的 ...
- uni-app开发经验分享四: 实现文字复制到选择器中
这里分享一个我经常用到的一个方法,主要是用来复制文字内容,具体代码如下: var that=this; if(!document){ uni.setClipboardData({ data:复制的值, ...
- Jmeter-插件扩展及性能监控插件的安装
需要对http服务进行大数据量的传值测试:看看产品中的http服务,能支持传多少字符:目标值是希望能到10w+: 上次测试中,服务器总是内存满导致服务不响应,因此想增加对服务端的性能监控:查阅了smi ...
- Hmailserver搭建邮箱服务器
由于阿里云,谷歌云,腾讯云等服务器都不开放25端口和pop3端口,想要使用邮箱服务得购买他们的企业邮箱,但是对于个人而言比较贵. 所以我们需要利用家庭宽带申请公网IP. 首先打电话给运营商客服,申请动 ...
- no-referrer-when-downgrade
原因: 从一个网站链接到另外一个网站会产生新的http请求,referrer是http请求中表示来源的字段.no-referrer-when-downgrade表示从https协议降为http协议时不 ...
- 研发流程 接口定义&开发&前后端联调 线上日志观察 模型变动
阿里等大厂的研发流程,进去前先了解一下_我们一起进大厂 - SegmentFault 思否 https://segmentfault.com/a/1190000021831640 接口定义 测试用例评 ...
- Java 从数组来看值传递和引用传递
从数组来看值传递和引用传递 惯例先看一段代码 public class DemoCollection14 { public static void main(String[] args) { Stri ...
- 在Centos7上安装Python+Selenium+Firefox+Geckodriver
1.事先准备好Centos7的系统 Centos系统是CentOS Linux release 7.4.1708 (Core) 查看Centos内核版本命令cat /etc/centos-releas ...
- Apache Hudi 0.7.0版本重磅发布
重点特性 1. Clustering 0.7.0版本中支持了对Hudi表数据进行Clustering(对数据按照数据特征进行聚簇,以便优化文件大小和数据布局),Clustering提供了更灵活地方式增 ...