Redis基础篇(二)高性能IO模型
我们经常听到说Redis是单线程的,也会有疑问:为什么单线程的Redis能那么快?
这里要明白一点:Redis是单线程,主要是指Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化、异步删除、集群数据同步等,都是由额外的线程执行的。
我们知道多线程能够提升并发性能,那为什么Redis会采用单线程,而非多线程?为什么单线程能那么快?
下面我们就来学习一下Redis采用单线程的原因。
为什么采用单线程?
使用多线程,虽然可以增加系统吞吐率,或是增加系统扩展性,但同样会产生开销。
Redis的数据是在内存里的,是共享的,如果使用多线程就会引发共享资源的竞争,需要引入互斥锁来解决,使得并行变串行。最终系统吞吐率并没有随着线程的增加而增加。
另外,多线程开发需要精细的设计,会增加系统的复杂度,降低代码的易调试性和可维护性。为了避免这些问题,Redis采用单线程模式。
单线程Redis为什么那么快?
通常来说,单线程的处理能力比多线程要差很多,那Redis却能使用单线程模型达到每秒数十万级别的处理能力,这是为什么呢?
一方面,Redis大多数操作是在内存上完成的,并且采用高效的数据结构,例如哈希表和跳表。另一方面,Redis采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率。
在学习多路复用机制前,我们要弄明白网络操作的基于IO模型和潜在的阻塞点。
基本IO模型与阻塞点
以Get请求为例,为了处理一个Get请求:
- 需要监听客户端请求(bind/listen)
- 和客户端建立连接(accept)
- 从socket中读取请求(recv)
- 解析客户端发送请求(parse)
- 根据请求类型读取键值数据(get)
- 最后给客户端返回结果,即向socket中写回数据(send)。
下图显示了这一过程,其中,bind/listen、accept、recv、parse和send属于网络IO处理,而get属性键值数据操作。
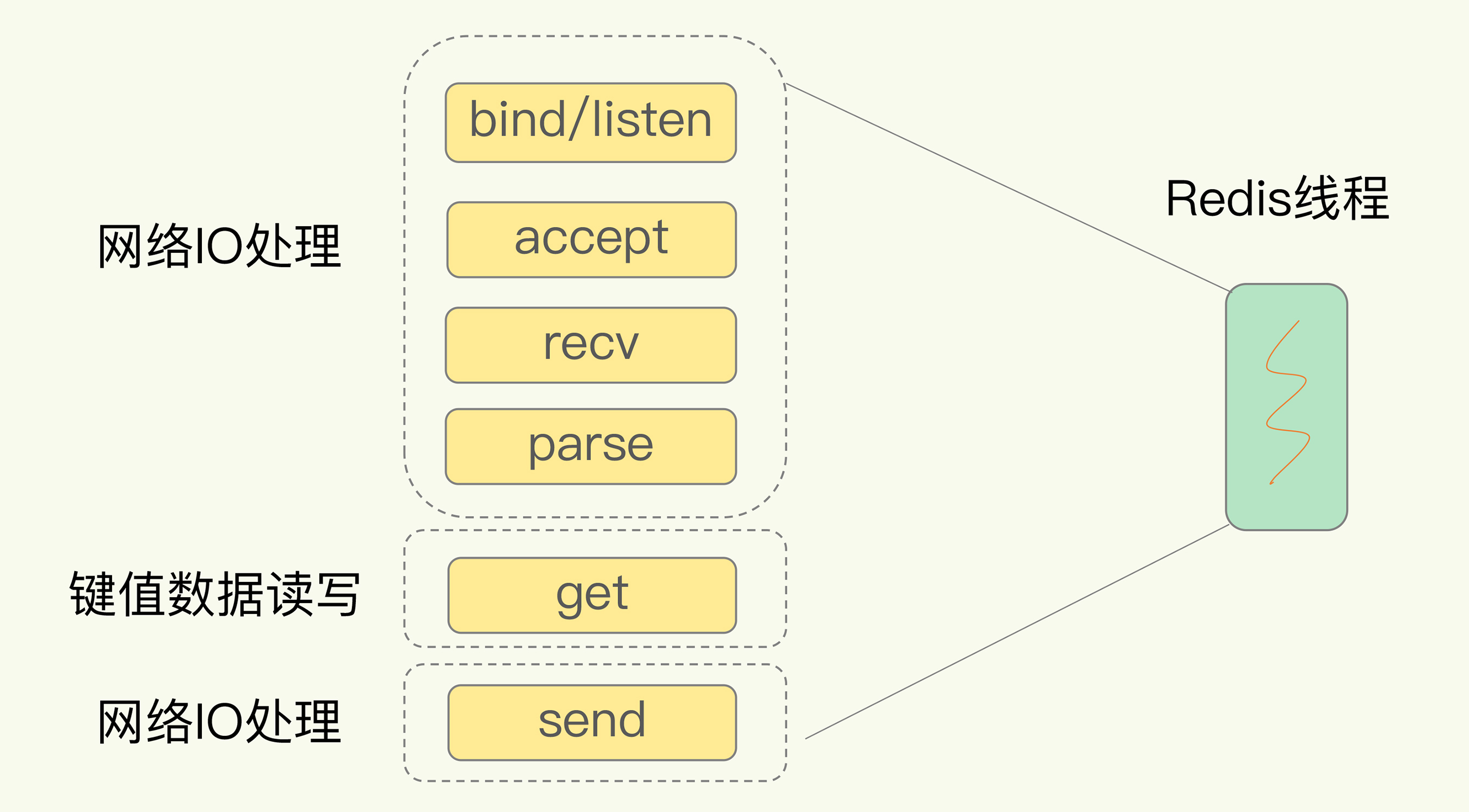
但是在这里的网络IO操作中,有潜在的阻塞点,分别是accept()和recv()。
- 当Redis监听到一个客户端有连接请求,但一直未能成功建立起连接时,会阻塞在accept()
- 当Redis通过recv()从一个客户端读取数据时,如果数据一直没有到达,Redis也会一直阻塞在recv()
这就导致Redis整个线程阻塞,无法处理其他客户端请求,效率很低。不过,幸运的是,socket网络模型本身支持非阻塞模式。
非阻塞模式
Socket网络模型可以设置非阻塞模式。

这样能保证Redis线程既不会像基本IO模型中一直在阻塞点等待,也不会导致Redis无法处理实际到达的连接请求或数据。
下面就到多路复用机制登场了。
基于多路复用的高性能I/O模型
Linux的IO多路复用机制是指一个线程处理多个IO流,也就是select/epoll机制。
在Redis运行单线程下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。
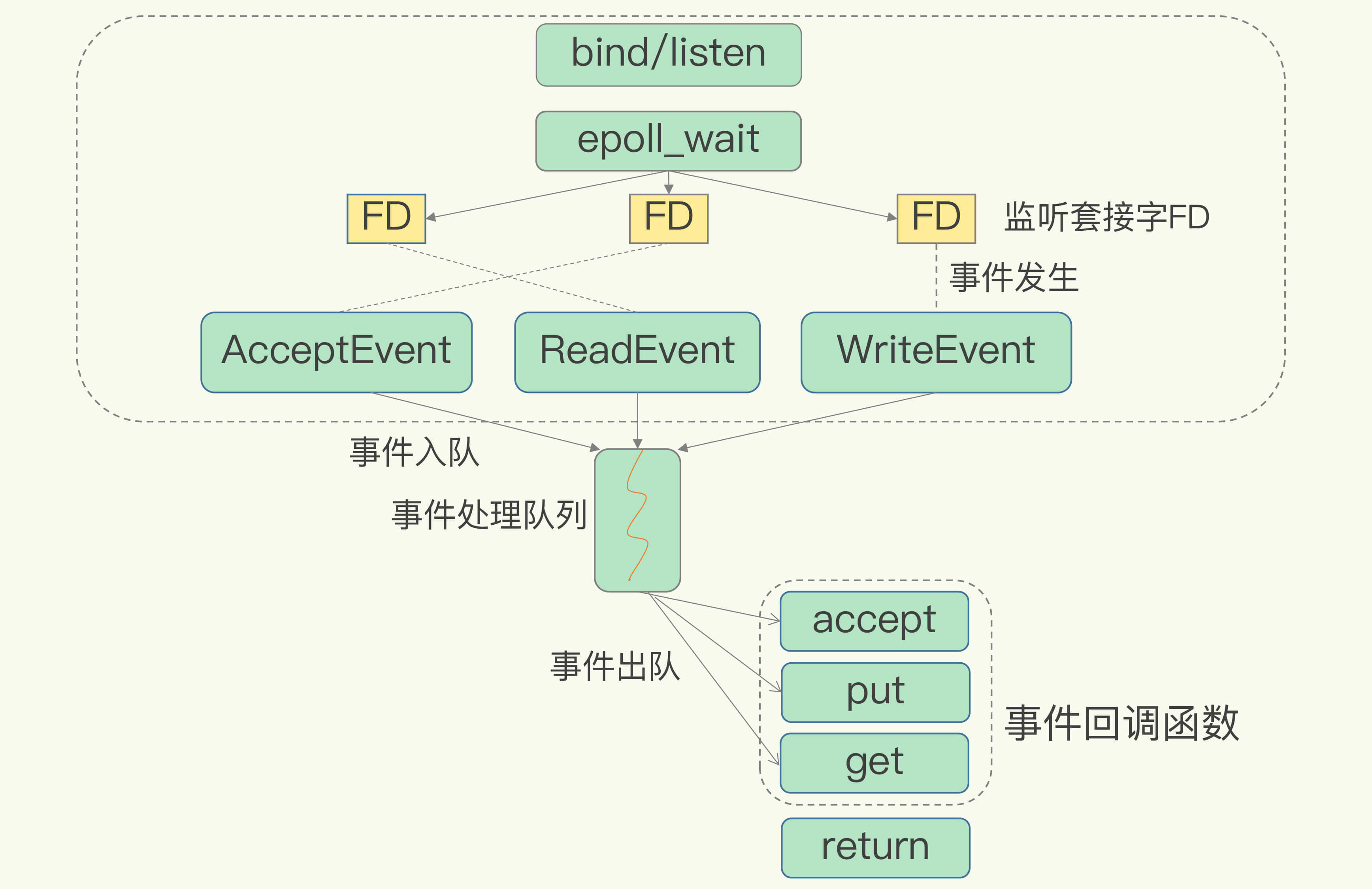
为了在请求到达时能通知到Redis线程,select/epoll提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
回调机制的工作流程:
- select/epoll一旦临听到FD上有请求到达,就会触发相应的事件,并放进一个事件队列中。
- Redis单线程对事件队列进行处理即可,无需一直轮询是否有请求发生,避免CPU资源浪费。
因为Redis一直在对事件队列进行处理,所以能及时响应客户端请求,提升Redis的响应性能。
不过,需要注意的是,在不同的操作系统上,多路复用机制也是适用的。
拓展
在“Redis基本IO模型”图中,有哪些潜在的性能瓶颈?
Redis单线程处理IO请求性能瓶颈主要包括2个方面:
1、任意一个请求在server中一旦发生耗时,都会影响整个server的性能 也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。
耗时的操作包括:
- 操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时
- 使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据
- 大量key集中过期:Redis的过期机制也是在主线程中执行的,大量key集中过期会导致处理一个请求时,耗时都在删除过期key,耗时变长
- 淘汰策略:溜达策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会 造成耗时变长。
- AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能
- 主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久
解决办法:
- 需要业务人员去规避
- Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响
2、并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
解决办法:
- Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能
- 当然,只针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的
参考资料
Redis基础篇(二)高性能IO模型的更多相关文章
- 03 高性能IO模型:采用多路复用机制的“单线程”Redis
本篇重点 三个问题: "Redis真的只有单线程吗?""为什么用单线程?""单线程为什么这么快?" "Redis真的只有单线程吗? ...
- 高性能IO模型浅析
高性能IO模型浅析 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking ...
- 高性能IO模型浅析(彩图解释)good
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking IO):默认创建的s ...
- 高性能IO模型浅析(转)
转自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 是我目前看到的解释IO模型最清晰的文章,当然啦,如果想要详细的进一步了解还是继续啃蓝宝书 ...
- 【珍藏】高性能IO模型浅析
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking IO):默认创建的s ...
- [转载] 高性能IO模型浅析
转载自http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(B ...
- 转 高性能IO模型浅析
高性能IO模型浅析 转自:http://www.cnblogs.com/fanzhidongyzby/p/4098546.html 服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: ( ...
- 【转载】高性能IO模型浅析
服务器端编程经常需要构造高性能的IO模型,常见的IO模型有四种: (1)同步阻塞IO(Blocking IO):即传统的IO模型. (2)同步非阻塞IO(Non-blocking IO):默认创建的s ...
- php基础篇-二维数组排序 array_multisort
原文:php基础篇-二维数组排序 array_multisort 对2维数组或者多维数组排序是常见的问题,在php中我们有个专门的多维数组排序函数,下面简单介绍下: array_multisort(a ...
随机推荐
- Java基础教程——List(列表)
集合概述 Java中的集合,指一系列存储数据的接口和类,可以解决复杂的数据存储问题. 导包:import java.util.*; 简化的集合框架图如下: List·列表 ArrayList List ...
- 朴素的模式匹配算法BF
1 #include <iostream> 2 using namespace std; 3 int BF(char S[], char T[]); 4 int main() 5 { 6 ...
- 公平lock和非公平lock的区别
可以看到区别在于,在lock时和tryAquire时,非公平锁不会去管队列中有没有线程在排队,直接尝试去获取锁,失败之后就和公平锁一样,乖乖去排队. 也就是说发生竞争的场景在于,尚未入队的线程之间和刚 ...
- Spring Security + JJWT 实现 JWT 认证和授权
关于 JJWT 的使用,可以参考之前的文章:JJWT 使用示例 一.鉴权过滤器 @Component public class JwtAuthenticationTokenFilter extends ...
- 第8.29节 使用MethodType将Python __setattr__定义的实例方法与实例绑定
一. 引言 在<第7.14节Python类中的实例方法解析>介绍了使用"实例对象名.方法名 = MethodType(函数, 对象)"将动态定义的方法与实例进行绑定 在 ...
- PyQt(Python+Qt)学习随笔:QListWidget插入项的insertItem方法
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 在QListWidget对象中,插入一个项的方法是调用insertItem方法,insertItem ...
- 第15.3节 PyCharm程序调试功能介绍
一. 代码调试 点击工具栏的调试按钮(如下图蓝色圈标记按钮)可以进行程序调试,可以在调试前先设置断点,断点设置就是在打开文件的行与前面的行号之间用鼠标单击进行设置和取消(如下图蓝色下划线上面的实体圆点 ...
- EF优缺点解析
原先用的是三层架构中ADO.NET做底层开发,纯手工sql语句拼装.后来遇到一个MVC+EF项目,体会到了EF的强大性. 它是微软封装好一种ADO.NET数据实体模型,将数据库结构以ORM模式映射到应 ...
- javascript中 fn() 和 return fn() 的区别
在js中用return和不用return,输出结果有的时候傻傻搞不清,之前在网上看到个例子挺经典,不过讲的不清楚,上例子: var i = 0; function fn(){ i++; if ...
- 题解-CF348E Pilgrims
题面 CF348E Pilgrims 有一棵 \(n\) 个点的 带权 树和 \(m\) 个关键点,要求杀了一个不关键的点,满足最多的关键点到离它最远的所有关键点的路径都被打断.求可以满足的最多关键点 ...