5.innodb B+tree索引
索引基础
索引是数据结构
1、图例
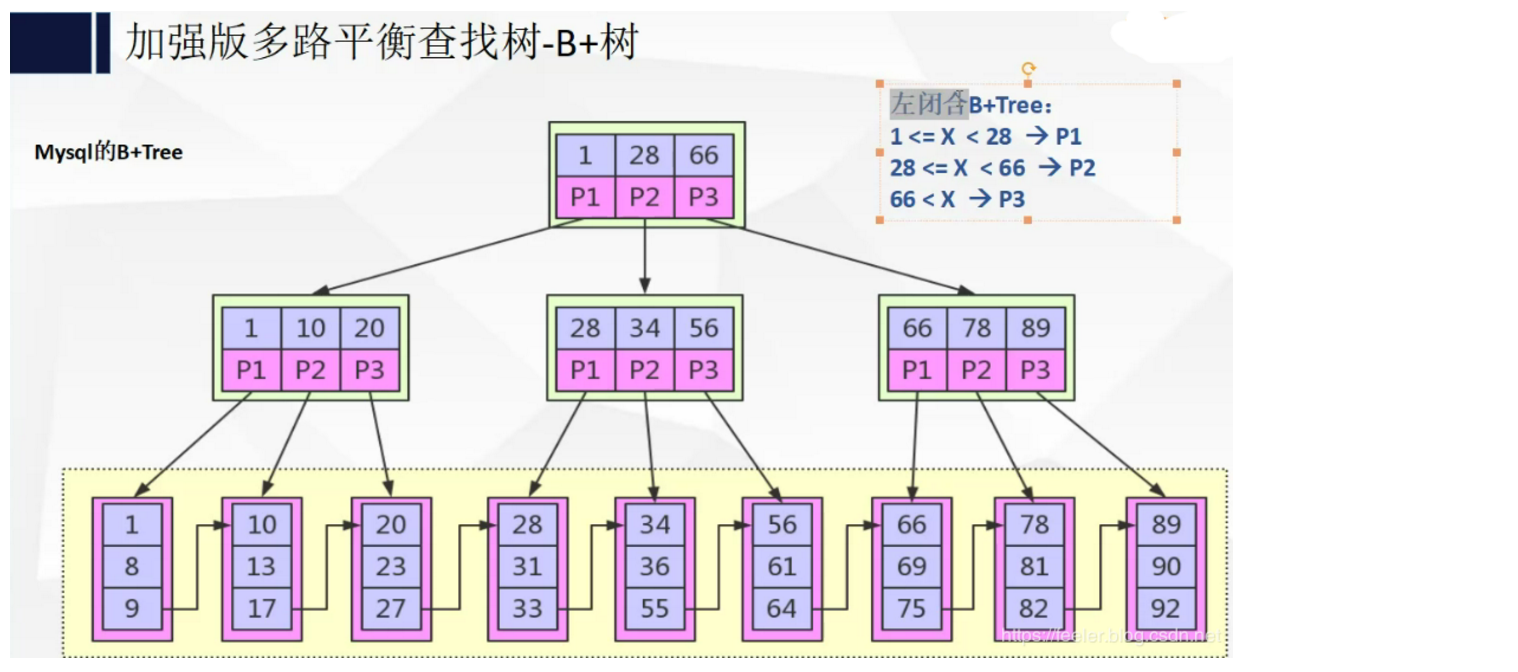
2、B+tree
- 特征
1、非叶子节点不保存数据,只用来索引,数据都保存在叶子节点
2、查询任何一条数据,查询的索引深度都是一样的
3、 B+ 树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的,所有叶子节点形成有序链表,方便范围查询
4、所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素
5、B+树索引并不能根据键值找到具体的行数据,B+树索引只能找到行数据所在的页,然后通过把页读到内存,再在内存中查找到行数据
3、聚集索引 和 辅助索引
聚集索引是按表的主键顺序构造的B+树,叶子节点存放的为整张表的行记录数据,每张表只能有一个聚集索引
辅助索引也叫非聚集索引,叶子节点除了键值以外还包含了一个bookmark,就是相对应行数据的聚集索引键,然后通过主键索引来找到一个完整的行数据。这个再根据聚集索引查找数据的过程,我们称为回表
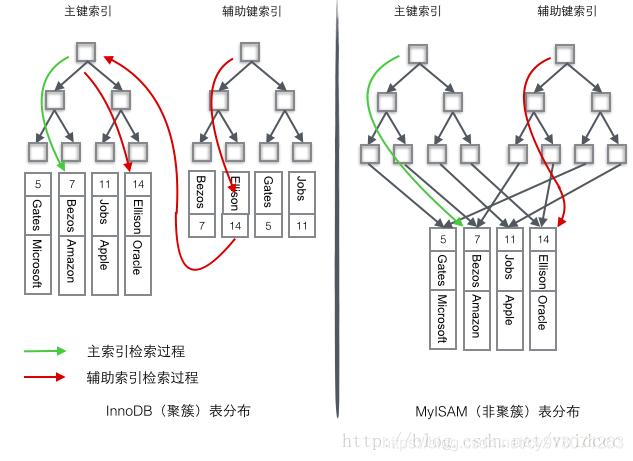
我们重点关注聚簇索引,看上去InnoDB的效率明显要低于MyISAM,因为每次使用辅助索引检索都要经过两次B+树查找,而MyISAM的非聚集索引使用辅助键查询只需要一次就能找到一整行的元组数据。这不是多此一举吗?
聚簇索引的优势在哪?
- 由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,而不用再通过存储的地址再去硬盘中查询一次数据行,如果按照主键Id来组织数据,获得数据更快。
- 辅助索引使用主键作为"指针" 而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时辅助索引的维护工作,使用主键值当作指针会让辅助索引占用更多的空间,换来的好处是InnoDB在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置(实现中通过16K的Page来定位,详细可以看计算机操作系统分页管理相关章节)会随着数据库里数据的修改而发生变化(B+树节点分裂以及Page的分裂),使用InnoDB就可以保证不管这个主键B+树(聚集索引)的节点如何变化,辅助索引树(非聚集索引)都不受影响。
- 聚集索引的数据都是按顺序存放的,所以如果查询条件是主键,使用主键索引,那么聚集索引会非常快,因为相同范围段的数据都是连续存放在一起的。即聚集索引表记录的物理排列顺序与索引的逻辑排列顺序一致,优点是查询速度快,一旦符合条件的第一个索引值的纪录被找到,具有连续索引值的记录也一定物理的紧跟其后。聚集索引的主键索引的叶子节点中直接存储行数据,又因为B+树的叶子节点之间都会用过指针相连,所以直接就能很快将这个范围内的数据全部获取。但是非聚集索引的主键索引虽然在逻辑上相同范围的叶子节点是顺序存储在一起的,但是真实的行数据是在硬盘中散列存储的,要想获取数据还需要将存储在叶子节点中的地址取出,根据地址再去硬盘中获取数据,效率就慢了很多。这个是聚集索引的主键索引的优势,也是第一条优势的具体体现。根据局部性原理,这也会提高检索效率。
- 局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中。
聚集索引的劣势有哪些?
- 聚集索引的缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引的顺序一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。插入数据时速度要慢(时间花费在“物理存储的排序”上,也就是首先要找到位置然后插入)。而非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致,聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式(这个指针可能是真实的物理地址,也可能是对应的主键值,这根据不同的存储引擎对它实现是不同的)。非聚集索引比聚集索引层次多,添加记录不会引起数据顺序的重组。
总的来说,聚集索引查询数据速度快,插入数据速度慢;非聚集索引反之。他们各自优缺点就是相反的。所以非聚集索引的优缺点看上面聚集索引的优缺点就够了。
4、优缺点
优点:
1、index是帮助MySQL高效获取数据的数据结构
2、降低IO使用率
3、降低CPU使用率(排序)
4、数据即索引,索引即数据
缺点:
1、索引要占用存储空间
2、索引不是所有情况均适用:
a、少量数据
b、频繁更新的字段
c、很少使用的字段
3、降低增删改的效率,增删改的同时还有对索引进行维护
5、语法
创建索引
1、create [unique] index index_name on tablename(colunm[,col,…])
2、alter table tabname add [unique] index index_name(colunm[,col,…]])
删除索引
1、alter table tabname drop index index_name
2、drop index index_name on tabname
6、索引类型
- 单值索引
- 多值索引
- 唯一索引
5.innodb B+tree索引的更多相关文章
- MYSQL的B+Tree索引树高度如何计算
前一段被问到一个平时没有关注到有关于MYSQL索引相关的问题点,被问到一个表有3000万记录,假如有一列占8位字节的字段,根据这一列建索引的话索引树的高度是多少? 这一问当时就被问蒙了,平时这也只关注 ...
- mysql--->B+tree索引的设计原理
1.什么是数据库的索引 每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不 ...
- Mysql B-Tree和B+Tree索引
Mysql B-Tree和B+树索引 Mysql加快数据查找使用B-Tree数据结构存储索引数据,InnoDB存储引擎实际使用B+Tree.下面首先介绍下B-Tree和B+Tree的区别: 一.B树和 ...
- MySQL InnoDB表和索引之聚簇索引与第二索引
MySQL InnoDB表和索引之聚簇索引与第二索引 By:授客QQ:1033553122 每个InnoDB表都有一个称之为聚簇索引(clustered index)的特殊索引,存储记录行数据.通常, ...
- 论 数据库 B Tree 索引 在 固态硬盘 上 的 离散存储
传统的做法 , 数据库 的 B Tree 索引 在 磁盘上是 顺序存储 的 , 这是考虑到 磁盘 机械读写 的 特性 . 实际上 , B Tree 是一个 树形结构 , 可以采用 链式 存储 , 就是 ...
- Mysql的B+ Tree索引
为什么要使用索引? 最简单的方式实现数据查询:全表扫描,即将整张表的数据全部或者分批次加载进内存,由于存储的最小单位是块或者页,它们是由多行数据组成,然后逐块逐块或者逐页逐页地查找,这样查找的速度非常 ...
- MYSQL之B+TREE索引原理
1.什么是索引? 索引:加速查询的数据结构. 2.索引常见数据结构 顺序查找: 最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕. 二叉树查找:(binary tree search): O( ...
- 为什么使用B+Tree索引?
什么是索引? 索引是一种数据结构,具体表现在查找算法上. 索引目的 提高查询效率 [类比字典和借书] 如果要查"mysql"这个单词,我们肯定需要定位到m字母,然后从下往下找到y字 ...
- MySQL innodb的组合索引各个列中的长度不能超过767,
MySQL索引的索引长度问题 MySQL的每个单表中所创建的索引长度是有限制的,且对不同存储引擎下的表有不同的限制. 在MyISAM表中,创建组合索引时,创建的索引长度不能超过1000,注意这里索 ...
随机推荐
- 2019-2020 ICPC Asia Hong Kong Regional Contest J. Junior Mathematician 题解(数位dp)
题目链接 题目大意 要你在[l,r]中找到有多少个数满足\(x\equiv f(x)(mod\; m)\) \(f(x)=\sum_{i=1}^{k-1} \sum_{j=i+1}^{k}d(x,i) ...
- Linux初学学习笔记 -----正则表达式和通配符
简单来说通配符是用来匹配文件名和目录而正则表达式是用来匹配文本内容的 常用的通配符 *:匹配任意多个字符 下面的是以p为开头的目录里面的文件 ?:匹配任意一个字符 [-]:匹配括号内出现的任意一个字符 ...
- MAT内存分析工具安装指南(MAT)
https://blog.csdn.net/mahl1990/article/details/79298616
- C#(一)基础篇—类型与变量
于今日起学习巩固C#基础 2020-12-01 本随笔用于个人回忆理解,记录当天学习过程,内容多从书中整理与自我学习了解,如有问题麻烦指正 以后有时间会单独分版块叙述 不管什么语言,都从一个Hello ...
- 第10.10节 Python使用__init__.py自动加载包下内容
在前面章节老猿介绍了包下模块及子包的加载的各种方式,并说明包的加载首先是自动加载包下的__init__.py文件.在<第10.6节 Python包的概念>中介绍了__init__.py文件 ...
- 第14.11节 Python中使用BeautifulSoup解析http报文:使用查找方法快速定位内容
一. 引言 在<第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问>介绍了BeautifulSoup对象的主要属性,通过这些属性可以访 ...
- Docker 安装-在centos7下安装Docker(二)
参考docker安装的方式: http://www.runoob.com/docker/centos-docker-install.html Docker中文官网安装步骤:https://docs.d ...
- java后端开发学习路线
思维导图(欢迎克隆):https://www.processon.com/mindmap/5f563cd31e08531762c4e32b 主要包括:编程基础.研发工具.应用框架.运维知识(主要学会配 ...
- 虚拟IP原理及使用
一.前言 高可用性 HA(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性.HA 系统是目前企业防止核心 ...
- FHQ简要笔记
前言 原文写于 XJ 集训day2 2020.1.19. 现在想想那时候连模板都还没写,只是刚刚理解就在那里瞎yy--之前果然还是太幼稚了. 今天刷训练指南发现全是 Treap 和 Splay ,不想 ...