spring boot:使用mybatis访问多个mysql数据源/查看Hikari连接池的统计信息(spring boot 2.3.1)
一,为什么要访问多个mysql数据源?
实际的生产环境中,我们的数据并不会总放在一个数据库,
例如:业务数据库:存放了用户/商品/订单
统计数据库:按年、月、日的针对用户、商品、订单的统计表
因为统计库中的数据是对业务库中数据的提取和挖掘,
但与业务的运行没有直接关系,所以我们会分开存放,
把它们放到两个库中。
但有时我们会有访问两个库中数据的需求,这时就需要访问两个或以上数据源
说明:刘宏缔的架构森林是一个专注架构的博客,地址:https://www.cnblogs.com/architectforest
对应的源码可以访问这里获取: https://github.com/liuhongdi/
说明:作者:刘宏缔 邮箱: 371125307@qq.com
二,演示项目的相关信息
1,项目地址:
https://github.com/liuhongdi/multimysql
2,项目原理
我们需要访问两个数据库,一个名字:store,
一个名字:tiku
然后在一个方法中获取到两个库中指定数据表的数据
3,项目结构,如图:
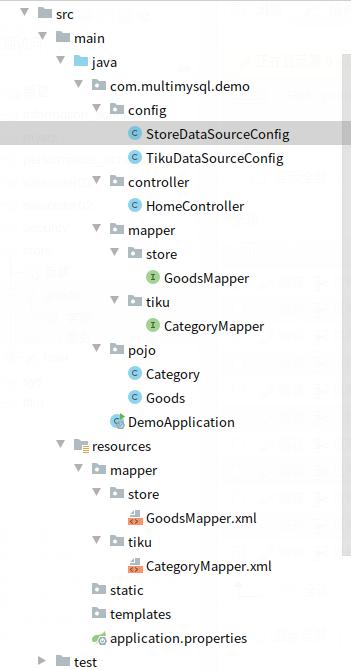
三,配置文件说明
1,application.properties
#mysql
spring.datasource.store.url=jdbc:mysql://127.0.0.1:3306/store?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
spring.datasource.store.username=root
spring.datasource.store.password=lhddemo
spring.datasource.store.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.store.maximum-pool-size=12
spring.datasource.store.minimum-idle=10
spring.datasource.store.idle-timeout=500000
spring.datasource.store.max-lifetime=540000 spring.datasource.tiku.url=jdbc:mysql://localhost:3306/tiku?useUnicode=true&characterEncoding=utf-8&useSSL=FALSE&serverTimezone=Asia/Shanghai
spring.datasource.tiku.username=root
spring.datasource.tiku.password=lhddemo
spring.datasource.tiku.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.tiku.maximum-pool-size=12
spring.datasource.tiku.minimum-idle=10
spring.datasource.tiku.idle-timeout=500000
spring.datasource.tiku.max-lifetime=540000
说明:我们需要访问两个数据库:store,tiku
注意max-lifetime的设置:这个值是连接池中一个连接的生命时间长度,
设置应该低于mysql配置文件中的wait-timeout值的设置,
idle-timeout是指空闲的连接的超时时间,应该不大于max-lifetime的值
maximum-pool-size是池中连接的数据,默认值是10,我们设置为12,保留默认值也没问题
2,两个数据表的结构:
store.goods
CREATE TABLE `goods` (
`goodsId` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`goodsName` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT 'name',
`subject` varchar(200) NOT NULL DEFAULT '' COMMENT '标题',
`price` decimal(15,2) NOT NULL DEFAULT '0.00' COMMENT '价格',
`stock` int(11) NOT NULL DEFAULT '0' COMMENT 'stock',
PRIMARY KEY (`goodsId`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表'
tiku.category
CREATE TABLE `category` (
`category_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`category_name` varchar(100) NOT NULL DEFAULT '' COMMENT '分类名称',
PRIMARY KEY (`category_id`),
UNIQUE KEY `category_name` (`category_name`)
) ENGINE=InnoDB AUTO_INCREMENT=0 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='分类'
四,java代码说明
1,StoreDataSourceConfig.java
@Configuration
//得到mapper
@MapperScan(basePackages = StoreDataSourceConfig.PACKAGE, sqlSessionFactoryRef = "storeSqlSessionFactory")
public class StoreDataSourceConfig {
// 指定mapper 目录,与其他数据源隔离
static final String PACKAGE = "com.multimysql.demo.mapper.store";
static final String MAPPER_LOCATION = "classpath:mapper/store/*.xml"; @Value("${spring.datasource.store.url}")
private String url; @Value("${spring.datasource.store.username}")
private String username; @Value("${spring.datasource.store.password}")
private String password; @Value("${spring.datasource.store.driver-class-name}")
private String driverClass; @Value("${spring.datasource.store.maximum-pool-size}")
private int maximumPoolSize; @Value("${spring.datasource.store.minimum-idle}")
private int minimumIdle; @Value("${spring.datasource.store.idle-timeout}")
private long idleTimeout; @Value("${spring.datasource.store.max-lifetime}")
private long maxLifetime; //得到datasource
@Bean(name = "storeDataSource")
@Primary
public DataSource storeDataSource() {
HikariDataSource dataSource=new HikariDataSource();
dataSource.setJdbcUrl(url);
dataSource.setUsername(username);
dataSource.setPassword(password);
dataSource.setDriverClassName(driverClass);
dataSource.setMaximumPoolSize(maximumPoolSize);
dataSource.setMinimumIdle(minimumIdle);
dataSource.setIdleTimeout(idleTimeout);
dataSource.setMaxLifetime(maxLifetime);
return dataSource;
} //得到TransactionManager
@Bean(name = "storeTransactionManager")
@Primary
public DataSourceTransactionManager storeTransactionManager() {
return new DataSourceTransactionManager(storeDataSource());
} //得到SqlSessionFactory
@Bean(name = "storeSqlSessionFactory")
@Primary
public SqlSessionFactory storeSqlSessionFactory(@Qualifier("storeDataSource") DataSource storeDataSource)
throws Exception {
final SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(storeDataSource);
sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources(StoreDataSourceConfig.MAPPER_LOCATION));
return sessionFactory.getObject();
}
}
生成到store数据库的数据源,
注意指定了mapper文件的路径,
两个不同数据源的mapper分别放到了不同的目录下,避免有冲突
2,TikuDataSourceConfig.java,
为节省篇幅,不再贴出代码,大家可以在github上自取
3,HomeController.java
@Controller
@RequestMapping("/home")
public class HomeController { @Resource
private GoodsMapper goodsMapper; @Resource
private CategoryMapper categoryMapper; @Resource
private HikariDataSource storeDataSource; @Resource
private HikariDataSource tikuDataSource; //商品详情 参数:商品id
@GetMapping("/goodsone")
@ResponseBody
public String goodsOne(@RequestParam(value="goodsid",required = true,defaultValue = "0") Long goodsId) throws SQLException {
System.out.println("------goodsInfo begin");
Goods goods = goodsMapper.selectOneGoods(goodsId);
Category category=categoryMapper.selectOneCategory("4");
return "goods:"+goods.toString()+";category:"+category.toString();
} //显示统计信息
@GetMapping("/stats")
@ResponseBody
public Object stats() throws SQLException { Connection connection = storeDataSource.getConnection();
connection.close();
HikariPoolMXBean storePool = storeDataSource.getHikariPoolMXBean();
int active = storePool.getActiveConnections();
int total = storePool.getTotalConnections();
int idle = storePool.getIdleConnections();
int theadsAwaitting = storePool.getThreadsAwaitingConnection();
int maximumPoolsize = storeDataSource.getMaximumPoolSize();
int minimumIdle = storeDataSource.getMinimumIdle();
String poolName = storeDataSource.getPoolName();
long connTimeout = storeDataSource.getConnectionTimeout();
long idleTimeout = storeDataSource.getIdleTimeout();
long maxLifetime = storeDataSource.getMaxLifetime(); String status = "store pool:<br/>";
status += "poolName:" + poolName+"<br/>";
status += "active:" + active+"<br/>";
status += "total:" + total+"<br/>";
status += "idle:" + idle+"<br/>";
status += "theadsAwaitting:" + theadsAwaitting+"<br/>";
status += "maximumPoolsize:" + maximumPoolsize+"<br/>";
status += "minimumIdle:" + minimumIdle+"<br/>";
status += "connTimeout:" + connTimeout+"<br/>";
status += "idleTimeout:" + idleTimeout+"<br/>";
status += "maxLifetime:" + maxLifetime+"<br/>"; Connection tikuConnection = tikuDataSource.getConnection();
tikuConnection.close();
HikariPoolMXBean tikuPool = tikuDataSource.getHikariPoolMXBean();
int active2 = tikuPool.getActiveConnections();
int total2 = tikuPool.getTotalConnections();
int idle2 = tikuPool.getIdleConnections();
int theadsAwaitting2 = tikuPool.getThreadsAwaitingConnection();
int maximumPoolsize2 = tikuDataSource.getMaximumPoolSize();
int minimumIdle2 = tikuDataSource.getMinimumIdle();
String poolName2 = tikuDataSource.getPoolName();
long connTimeout2 = tikuDataSource.getConnectionTimeout();
long idleTimeout2 = tikuDataSource.getIdleTimeout();
long maxLifetime2 = tikuDataSource.getMaxLifetime(); status += "tiku pool:<br/>";
status += "poolName:" + poolName2+"<br/>";
status += "active:" + active2+"<br/>";
status += "total:" + total2+"<br/>";
status += "idle:" + idle2+"<br/>";
status += "theadsAwaitting:" + theadsAwaitting2+"<br/>";
status += "maximumPoolsize:" + maximumPoolsize2+"<br/>";
status += "minimumIdle:" + minimumIdle2+"<br/>";
status += "connTimeout:" + connTimeout2+"<br/>";
status += "idleTimeout:" + idleTimeout2+"<br/>";
status += "maxLifetime:" + maxLifetime2+"<br/>"; return status;
}
说明:goodsOne方法:返回store.goods表中的商品信息和tiku.category表中的分类信息
stats方法:打印两个Hikari连接池的信息
4,其他的 类文件和mapper文件,请访问github获取
五,效果测试
1,访问商品信息地址:
http://127.0.0.1:8080/home/goodsone?goodsid=3
返回:
goods: Goods:goodsId=3 goodsName=100分电动牙刷 subject=好用到让你爱上刷牙 price=59.00 stock=15
category: Goods:category_id=4 category_name=bash
2,访问统计地址:
http://127.0.0.1:8080/home/stats
返回:
store pool:
poolName:HikariPool-1
active:0
total:10
idle:10
theadsAwaitting:0
maximumPoolsize:12
minimumIdle:10
connTimeout:30000
idleTimeout:500000
maxLifetime:540000
tiku pool:
poolName:HikariPool-2
active:0
total:10
idle:10
theadsAwaitting:0
maximumPoolsize:12
minimumIdle:10
connTimeout:30000
idleTimeout:500000
maxLifetime:540000
六,查看spring boot的版本
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.3.1.RELEASE)
spring boot:使用mybatis访问多个mysql数据源/查看Hikari连接池的统计信息(spring boot 2.3.1)的更多相关文章
- spring boot:使mybatis访问多个druid数据源(spring boot 2.3.2)
一,为什么要使用多个数据源? 1,什么情况下需要使用多个数据源? 当我们需要访问不同的数据库时,则需要配置配置多个数据源, 例如:电商的业务数据库(包括用户/商品/订单等) 和统 ...
- 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_3-1.整合Mybatis访问数据库和阿里巴巴数据源
笔记 1.整合Mybatis访问数据库和阿里巴巴数据源 简介:整合mysql 加入mybatis依赖,和加入alibaba druid数据源 1.加入依赖(可以用 http://start.s ...
- DB数据源之SpringBoot+MyBatis踏坑过程(五)手动使用Hikari连接池
DB数据源之SpringBoot+MyBatis踏坑过程(五)手动使用Hikari连接池 liuyuhang原创,未经允许禁止转载 系列目录连接 DB数据源之SpringBoot+Mybatis踏坑 ...
- Druid连接池及监控在spring中的配置
Druid连接池及监控在spring配置如下: <bean id="dataSource" class="com.alibaba.druid.pool.DruidD ...
- Spring学习总结(12)——Druid连接池及监控在spring配置
Druid连接池及监控在spring配置如下: <bean id="dataSource" class="com.alibaba.druid.pool.DruidD ...
- C3P0连接池在hibernate和spring中的配置
首先为什么要使用连接池及为什么要选择C3P0连接池,这里就不多说了,目前C3P0连接池还是比较方便.比较稳定的连接池,能与spring.hibernate等开源框架进行整合. 一.hibernate中 ...
- Spring boot教程mybatis访问MySQL的尝试
Windows 10家庭中文版,Eclipse,Java 1.8,spring boot 2.1.0,mybatis-spring-boot-starter 1.3.2,com.github.page ...
- 使用MyBatis集成阿里巴巴druid连接池(不使用spring)
在工作中发现mybatis默认的连接池POOLED,运行时间长了会报莫名其妙的连接失败错误.因此采用阿里巴巴的Druid数据源(码云链接 ,中文文档链接). mybatis更多数据源参考博客链接 . ...
- SpringBoot配置MySql数据库和Druid连接池
1.pom文件增加相关依赖 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connec ...
随机推荐
- Java枚举解读
Java枚举 枚举类概念的理解与定义 一个类的对象是有限个,确定的,我们称此为枚举类. 当需要定义和维护一组常量时,强烈建议使用枚举类. 如果一个枚举类中只有一个对象,则可以作为单例模式的实现方式. ...
- 本机ping不通虚拟机,但虚拟机可以ping通本机时怎么解决
在各自网络都连接的情况下,本机ping不通虚拟机,但虚拟机可以ping通本机时解决方案: 1.linux虚拟机中连接方式选择NAT模式 2.本地启动VMnet8,然后选择VMnet8的属性,手动输入和 ...
- unserialize3 攻防世界
序列化是将对象转换为便于保存的字符串, 而反序列化是将便于保存的字符串转换为字符串. _wakeup()魔法方法 如果直接传参给code会被__wakeup()函数再次序列化,所以要绕过他, 利用__ ...
- Robotframework自动化5-基础关键字介绍2
一:时间 1.获取当前时间 Get time 2.获取当月时间 ${yyyy} ${mm} ${day} Get Time year,month,day${time} Catenate SE ...
- 初等函数——指数函数(Exponential Function)
一般地,函数叫做指数函数,其中x是自变量,函数的定义域是R.
- 【小白学PyTorch】12 SENet详解及PyTorch实现
文章来自微信公众号[机器学习炼丹术].我是炼丹兄,有什么问题都可以来找我交流,近期建立了微信交流群,也在朋友圈抽奖赠书十多本了.我的微信是cyx645016617,欢迎各位朋友. 参考目录: @ 目录 ...
- golang "%p"学习记录随笔
对于获取slice的指针地址, 通过unsafe.Pointer 和 "%p"占位符两种方式得到的地址是不同的 s := make([]int, 1) t.Log(unsafe.P ...
- php反序列化浅谈
0x01 serialize()和unserialize() 先介绍下几个函数 serialize()是用于将类转换为一个字符串 unserialize()用于将字符串转换回一个类 serialize ...
- ERP与EHR系统的恩怨纠葛--开源软件诞生13
ERP中需要EHR的存在吗--第13篇 用日志记录"开源软件"的诞生 [点亮星标]----祈盼着一个鼓励 博主开源地址: 码云:https://gitee.com/redragon ...
- Latex博客转载
\[{e^{ix}=cosx+isinx} \] \[[博客地址](https://www.cnblogs.com/Sinte-Beuve/p/6160905.html) \]