Spark如何进行动态资源分配
一、操作场景
对于Spark应用来说,资源是影响Spark应用执行效率的一个重要因素。当一个长期运行的服务,若分配给它多个Executor,可是却没有任何任务分配给它,而此时有其他的应用却资源紧张,这就造成了很大的资源浪费和资源不合理的调度。
动态资源调度就是为了解决这种场景,根据当前应用任务的负载情况,实时的增减Executor个数,从而实现动态分配资源,使整个Spark系统更加健康。
二、动态资源策略
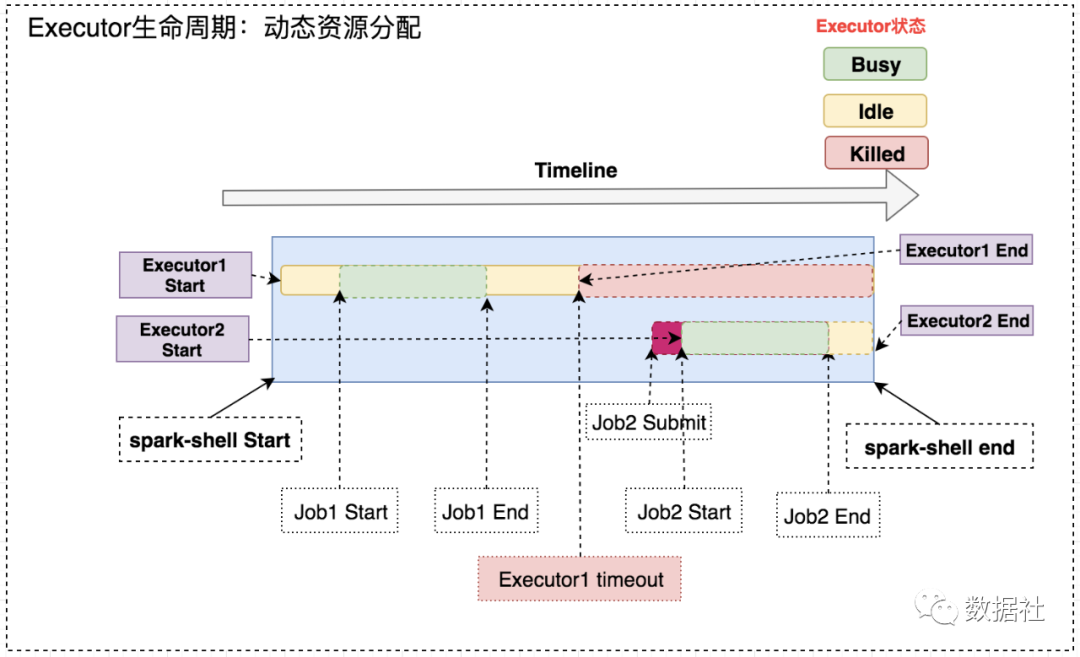
1、资源分配策略
开启动态分配策略后,application会在task因没有足够资源被挂起的时候去动态申请资源,这种情况意味着该application现有的executor无法满足所有task并行运行。spark一轮一轮的申请资源,当有task挂起或等待spark.dynamicAllocation.schedulerBacklogTimeout(默认1s)`时间的时候,会开始动态资源分配;之后会每隔spark.dynamicAllocation.sustainedSchedulerBacklogTimeout(默认1s)时间申请一次,直到申请到足够的资源。每次申请的资源量是指数增长的,即1,2,4,8等。
之所以采用指数增长,出于两方面考虑:其一,开始申请的少是考虑到可能application会马上得到满足;其次要成倍增加,是为了防止application需要很多资源,而该方式可以在很少次数的申请之后得到满足。
2、资源回收策略
当application的executor空闲时间超过spark.dynamicAllocation.executorIdleTimeout(默认60s)后,就会被回收。
三、操作步骤
1、yarn的配置
首先需要对YARN进行配置,使其支持Spark的Shuffle Service。
修改每台集群上的yarn-site.xml:
- 修改
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle,spark_shuffle</value>
</property>
- 增加
<property>
<name>yarn.nodemanager.aux-services.spark_shuffle.class</name>
<value>org.apache.spark.network.yarn.YarnShuffleService</value>
</property>
<property>
<name>spark.shuffle.service.port</name>
<value>7337</value>
</property>
将$SPARKHOME/lib/spark-X.X.X-yarn-shuffle.jar拷贝到每台NodeManager的${HADOOPHOME}/share/hadoop/yarn/lib/下, 重启所有修改配置的节点。
2、Spark的配置
配置$SPARK_HOME/conf/spark-defaults.conf,增加以下参数:
spark.shuffle.service.enabled true //启用External shuffle Service服务
spark.shuffle.service.port 7337 //Shuffle Service默认服务端口,必须和yarn-site中的一致
spark.dynamicAllocation.enabled true //开启动态资源分配
spark.dynamicAllocation.minExecutors 1 //每个Application最小分配的executor数
spark.dynamicAllocation.maxExecutors 30 //每个Application最大并发分配的executor数
spark.dynamicAllocation.schedulerBacklogTimeout 1s
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout 5s
四、启动
使用spark-sql On Yarn执行SQL,动态分配资源。以yarn-client模式启动ThriftServer:
cd $SPARK_HOME/sbin/
./start-thriftserver.sh \
--master yarn-client \
--conf spark.driver.memory=10G \
--conf spark.shuffle.service.enabled=true \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.dynamicAllocation.minExecutors=1 \
--conf spark.dynamicAllocation.maxExecutors=300 \
--conf spark.dynamicAllocation.sustainedSchedulerBacklogTimeout=5s
启动后,ThriftServer会在Yarn上作为一个长服务来运行。
Spark如何进行动态资源分配的更多相关文章
- spark on yarn 动态资源分配报错的解决:org.apache.hadoop.yarn.exceptions.InvalidAuxServiceException: The auxService:spark_shuffle does not exist
组件:cdh5.14.0 spark是自己编译的spark2.1.0-cdh5.14.0 第一步:确认spark-defaults.conf中添加了如下配置: spark.shuffle.servic ...
- 记一次有关spark动态资源分配和消息总线的爬坑经历
问题: 线上的spark thriftserver运行一段时间以后,ui的executor页面上显示大量的active task,但是从job页面看,并没有任务在跑.此外,由于在yarn mode下, ...
- Spark动态资源分配-Dynamic Resource Allocation
微信搜索lxw1234bigdata | 邀请体验:数阅–数据管理.OLAP分析与可视化平台 | 赞助作者:赞助作者 Spark动态资源分配-Dynamic Resource Allocation S ...
- 利用动态资源分配优化Spark应用资源利用率
背景 在某地市开展项目的时候,发现数据采集,数据探索,预处理,数据统计,训练预测都需要很多资源,现场资源不够用. 目前该项目的资源3台旧的服务器,每台的资源 内存为128G,cores 为24 (co ...
- spark提交至yarn的的动态资源分配
1.为什么开启动态资源分配 ⽤户提交Spark应⽤到Yarn上时,可以通过spark-submit的num-executors参数显示地指定executor 个数,随后,ApplicationMast ...
- 「Spark从精通到重新入门(二)」Spark中不可不知的动态资源分配
前言 资源是影响 Spark 应用执行效率的一个重要因素.Spark 应用中真正执行 task 的组件是 Executor,可以通过spark.executor.instances 指定 Spark ...
- Spark Streaming资源动态申请和动态控制消费速率剖析
本期内容 : Spark Streaming资源动态分配 Spark Streaming动态控制消费速率 为什么需要动态处理 : Spark 属于粗粒度资源分配,也就是在默认情况下是先分配好资源然后再 ...
- Spark的动态资源分配
跑spark程序的时候,公司服务器需要排队等资源,参考一些设置,之前不知道,跑的很慢,懂得设置之后简直直接起飞. 简单粗暴上设置代码: def conf(self): conf = super(Tbt ...
- spark任务调度模式,动态资源分配
官网链接: http://spark.apache.org/docs/latest/job-scheduling.html 主要介绍: 1 application级调度方式 2 单个applicati ...
随机推荐
- [LeetCode]196. 删除重复的电子邮箱(delete)
题目 编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个. +----+------------------+ | Id | Email | ...
- 最好用的流程编辑器bpmn-js系列之基本使用
最好用的流程编辑器bpmn-js系列文章 BPMN(Business Process Modeling Notation)是由业务流程管理倡议组织BPMI(The Business Process M ...
- Vue iview可编辑表格的实现
创建table实例页 views/table.vue <template> <h1>table page</h1> </template> <sc ...
- springboot的文件路径,配置文件
生成springboot会指定一个包路径,启动的class文件在这个目录下,其他的controller等也要在这个目录的子目录下,不然会扫不到. 一般我们会维护两三个配置文件:生产环境,开发环境,测试 ...
- list、set、map的区别和联系
结构特点 List和Set是存储单列数据的集合,Map是存储键值对这样的双列数据的集合: List中存储的数据是有顺序的,并且值允许重复:Map中存储的数据是无序的,它的键是不允许重复的,但是值是允许 ...
- Spring学习(四)IOC详解
一.简介 概念:控制反转是一种通过描述(在 Java 中可以是 XML 或者注解)并通过第三方(Spring)去产生或获取特定对象的方式.(被动创建) 优势: ① 降低对象之间的耦合 ② 我们不需要理 ...
- 谈谈Netty内存管理
前言 正是Netty的易用性和高性能成就了Netty,让其能够如此流行. 而作为一款通信框架,首当其冲的便是对IO性能的高要求. 不少读者都知道Netty底层通过使用Direct Memory,减少了 ...
- Processing 状态量控制动画技巧
之前在CSDN上发表过: https://blog.csdn.net/fddxsyf123/article/details/62848357
- Java知识系统回顾整理01基础02面向对象01类和对象
一.面向对象实例--设计英雄这个类 LOL有很多英雄,比如盲僧,团战可以输,提莫必须死,盖伦,琴女 所有这些英雄,都有一些共同的状态 比如,他们都有名字,hp,护甲,移动速度等等 这样我们就可以设计一 ...
- 【题解】一本通例题 S-Nim
\(\color{purple}{Link}\) \(\text{Solution:}\) 这个题就是给\(Nim\)游戏做了一个限制. 考虑一下\(\text{SG}\)函数:给定的局面下对应的\( ...