seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化
一、线性关系数据可视化lmplot( )
表示对所统计的数据做散点图,并拟合一个一元线性回归关系。
lmplot(x, y, data, hue=None, col=None, row=None, palette=None,col_wrap=None, height=5, aspect=1,markers="o",
sharex=True,sharey=True, hue_order=None, col_order=None,row_order=None,legend=True, legend_out=True,
x_estimator=None, x_bins=None,x_ci="ci", scatter=True, fit_reg=True, ci=95, n_boot=1000,units=None, order=1,
logistic=False, lowess=False, robust=False,logx=False, x_partial=None, y_partial=None, truncate=False,x_jitter=None,
y_jitter=None, scatter_kws=None, line_kws=None, size=None)
- x和y 表示显示x和y的线性关系
- hue 表示对x按照hue进行分类,每个分类都在同一个图表显示
- hue_order 按照hue分类后,多分类的结果进行筛选和显示排序
- col和row 表示对hue的分类拆分为多个图表显示,或者对x按照col分类并拆分为多个横向的独立图表、或者对x按照row分类并拆分为多个竖直的独立图表
- col_order和row_order 按照col和row分类拆分后,多分类进行删选和显示排序
- col_wrap 每行显示的图表个数
- height 每个图表的高度(最后一个参数size即height,size正被height替代)
- aspect 每个图表的长宽比,默认为1即显示为正方形
- marker 点的形式,
- sharex和sharey 拆分为多个图表时是否共用x轴和y轴,默认共用
- x_jitter和y_jitter 给x轴和y轴随机增加噪点
#hue分类,col图表拆分
sns.lmplot(x="tip", y="total_bill",data=tips,hue='smoker',palette="Set1",ci = 80, markers = ['+','o']) #是否吸烟在同一个图表显示
sns.lmplot(x="tip", y="total_bill",data=tips,hue='day',col='day',sharex=True,markers='.') #按日期拆分为独立的图表

sns.lmplot(x="tip", y="total_bill",data=tips,col='time',row='sex',height=3) #行拆分和列拆分

二、时间线图lineplot()
时间线图用lineplot()表示,tsplot()正在被替代。
lineplot(x=None, y=None, hue=None, size=None, style=None, data=None, palette=None, hue_order=None, hue_norm=None,
sizes=None, size_order=None, size_norm=None,dashes=True, markers=None, style_order=None,units=None,
estimator="mean", ci=95, n_boot=1000,sort=True, err_style="band", err_kws=None,legend="brief", ax=None, **kwargs)
fmri = sns.load_dataset("fmri")
ax = sns.lineplot(x="timepoint", y="signal", data=fmri)
fmri.head()

三、热图heatmap()
热图只针对二维数据,用颜色的深浅表示大小,数值越小颜色越深。
heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False,annot=None, fmt=".2g",
annot_kws=None,linewidths=0, linecolor="white",cbar=True, cbar_kws=None, cbar_ax=None,
square=False, xticklabels="auto", yticklabels="auto",mask=None, ax=None, **kwargs)
- data 二维数据
- vmin和vmax 调色板的最小值和最大值
- annot 图中是否显示数值
- fmt 格式化数值
- linewidth和linecolor 格子线宽和颜色
- cbar 是否显示色带
- cbar_kws 色带的参数设置,字典形式,在cbar设置为True时才生效,例如{"orientation": "horizontal"}表示横向显示色带
- square 每个格子是否为正方形
rng = np.random.RandomState(1)
df = pd.DataFrame(rng.randint(1,10,(10,12)))
fig = plt.figure(figsize=(15,6))
ax1 = plt.subplot(121)
sns.heatmap(df,vmin=3,vmax=8,linewidth=0.2,square=True)
ax2 = plt.subplot(122)
sns.heatmap(df,annot=True,square=False,cbar_kws={"orientation": "horizontal"})

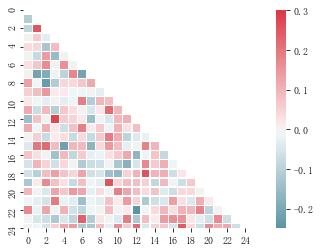
生成半边热图,mask参数
rs = np.random.RandomState(33)
d = pd.DataFrame(rs.normal(size=(100, 26)))
corr = d.corr() #求解相关性矩阵表格,26*26的一个正方数据 mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 设置一个“上三角形”蒙版 cmap = sns.diverging_palette(220, 10, as_cmap=True)# 设置调色盘 sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,square=True, linewidths=0.2)
四、结构化图表可视化
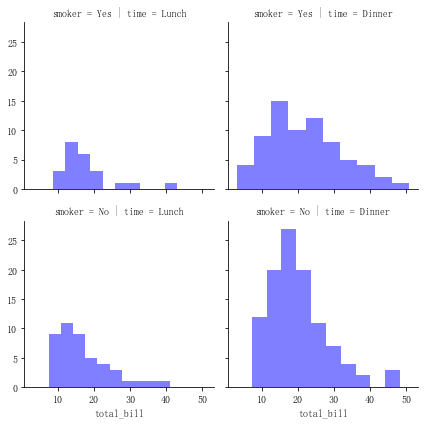
tips = sns.load_dataset("tips") # 导入数据
g = sns.FacetGrid(tips, col="time", row="smoker")# 创建一个绘图表格区域,列按time分类、行按smoker分类
g.map(plt.hist, "total_bill",alpha = 0.5,color = 'b',bins = 10) # 以total_bill字段数据分别做直方图统计
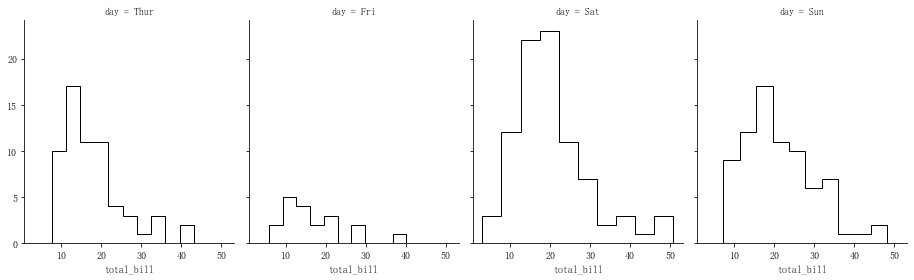
g = sns.FacetGrid(tips, col="day",
height=4, # 图表大小
aspect=.8) # 图表长宽比 g.map(plt.hist, "total_bill", bins=10,
histtype = 'step', #'bar', 'barstacked', 'step', 'stepfilled'
color = 'k')
#散点图
g = sns.FacetGrid(tips, col="time", row="smoker") g.map(plt.scatter,
"total_bill", "tip", # share{x,y} → 设置x、y数据
edgecolor="w", s = 40, linewidth = 1) # 设置点大小,描边宽度及颜色

g = sns.FacetGrid(tips, col="time", hue="smoker") # 创建一个绘图表格区域,列按col分类,按hue分类 g.map(plt.scatter,
"total_bill", "tip", # share{x,y} → 设置x、y数据
edgecolor="w", s = 40, linewidth = 1) # 设置点大小,描边宽度及颜色
g.add_legend()

attend = sns.load_dataset("attention")
print(attend.head())
g = sns.FacetGrid(attend, col="subject", col_wrap=5,# 设置每行的图表数量
size=1.5)
g.map(plt.plot, "solutions", "score", marker="o",color = 'gray',linewidth = 2)# 绘制图表矩阵
g.set(xlim = (0,4),ylim = (0,10),xticks = [0,1,2,3,4], yticks = [0,2,4,6,8,10]) # 设置x,y轴刻度

seaborn线性关系数据可视化:时间线图|热图|结构化图表可视化的更多相关文章
- Python图表数据可视化Seaborn:4. 结构化图表可视化
1.基本设置 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns ...
- 只能用于文本与图像数据?No!看TabTransformer对结构化业务数据精准建模
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 TensorFlow 实战系列:https://www.showmeai ...
- 基于HTML5实现3D热图Heatmap应用
Heatmap热图通过众多数据点信息,汇聚成直观可视化颜色效果,热图已广泛被应用于气象预报.医疗成像.机房温度监控等行业,甚至应用于竞技体育领域的数据分析. http://www.hightopo.c ...
- 基于HTML5实现的Heatmap热图3D应用
Heatmap热图通过众多数据点信息,汇聚成直观可视化颜色效果,热图已广泛被应用于气象预报.医疗成像.机房温度监控等行业,甚至应用于竞技体育领域的数据分析. 已有众多文章分享了生成Heatmap热图原 ...
- 扩增子图表解读3热图:差异菌、OTU及功能
热图是使用颜色来展示数值矩阵的图形.通常还会结合行.列的聚类分析,以表达实验数据多方面的结果. 热图在生物学领域应用广泛,尤其在高通量测序的结果展示中很流行,如样品-基因表达,样品-OTU相对丰度矩 ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
- 结构化数据、半结构化数据、非结构化数据——Hadoop处理非结构化数据
刚开始接触Hadoop ,指南中说Hadoop处理非结构化数据,学习数据库的时候,老师总提结构化数据,就是一张二维表,那非结构化数据是什么呢?难道是文本那样的文件?经过上网搜索,感觉这个帖子不错 网址 ...
- MySQL 5.7:非结构化数据存储的新选择
本文转载自:http://www.innomysql.net/article/23959.html (只作转载, 不代表本站和博主同意文中观点或证实文中信息) 工作10余年,没有一个版本能像MySQL ...
- Python图表数据可视化Seaborn:3. 线性关系数据| 时间线图表| 热图
1. 线性关系数据可视化 lmplot( ) import numpy as np import pandas as pd import matplotlib.pyplot as plt import ...
随机推荐
- Oauth2.0认证流程
- 浏览器缓存_HTTP强缓存和协商缓存
浏览器缓存 浏览器缓存是浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本地磁盘加载文档. 所以根据上面的特点,浏览器缓存有下面的优点: 减少冗余的数据传 ...
- 「疫期集训day1」无言
正式集训第一天,感觉没啥特别大的感受,无非是奥赛时间延长了,效率提高了,身外事少了 当然不止这些 感受1:有些曾经被恶的题现在仍然在恶心,例如昨天的farmcraft,今天的整数划分(和着多边形一块调 ...
- 11.unity3d 摄像机快速定位到Scene视角
选中Camera,比如Main Camera摄像机,在菜单选择GameObject->Align With View就可以了.如下图所示,参照前三步操作,第4步是最终效果.
- 一文梳理Web存储,从cookie,WebStorage到IndexedDB
前言 HTTP是无状态的协议,网络早期最大的问题之一是如何管理状态.服务器无法知道两个请求是否来自同一个浏览器.cookie应运而生,开始出现在各大网站,然而随着前端应用复杂度的提高,Cookie 也 ...
- day75 bbs项目☞后台管理+修改头像
目录 一.后台管理之添加文章 二.修改用户头像 bbs项目总结 一.后台管理之添加文章 添加文章有两个需要注意的问题: 文章的简介切取,应该想办法获取到当前文章的文本内容后再截取字符 XSS攻击,由于 ...
- CSS(六)- 内容布局 - Flexbox
Flexbox是CSS3提供的用于布局的一套新属性,是为了应对行内块.浮动和表格格式产生的问题而生的.其包含针对容器(弹性容器,flex container)和针对其直接子元素(弹性项,flex it ...
- python positional argument follows keyword argument
关键字参数必须跟随在位置参数后面! 因为python函数在解析参数时, 是按照顺序来的, 位置参数是必须先满足, 才能考虑其他可变参数.
- scrapy 基础组件专题(九):scrapy-redis 源码分析
下面我们来看看,scrapy-redis的每一个源代码文件都实现了什么功能,最后如何实现分布式的爬虫系统: connection.py 连接得配置文件 defaults.py 默认得配置文件 dupe ...
- java 面向对象(三):类结构 属性
类的设计中,两个重要结构之一:属性 对比:属性 vs 局部变量 1.相同点: * 1.1 定义变量的格式:数据类型 变量名 = 变量值 * 1.2 先声明,后使用 * 1.3 变量都其对应的作用域 2 ...