XtraBackup 备份原理
来着淘宝技术:
http://mysql.taobao.org/monthly/2016/03/07/
https://github.com/alibaba/AliSQL
前言
Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MySQL 数据库物理热备的备份工具,支持 MySQl(Oracle)、Percona Server 和 MariaDB,并且全部开源,真可谓是业界良心。我们 RDS MySQL 的物理备份就是基于这个工具做的。
项目的 blueprint 和 bug 讨论放在 Launchpad,代码之前也放在 Launchpad,现在已经迁移到 Github 啦,项目更新发布非常快,感兴趣的可以关注 :-)
本文会介绍下备份工具的工作原理,希望对大家有所帮助。
工具集
软件包安装完后一共有4个可执行文件,如下:
usr
├── bin
│ ├── innobackupex
│ ├── xbcrypt
│ ├── xbstream
│ └── xtrabackup
其中最主要的是 innobackupex 和 xtrabackup,前者是一个 perl 脚本,后者是 C/C++ 编译的二进制。
xtrabackup 是用来备份 InnoDB 表的,不能备份非 InnoDB 表,和 mysqld server 没有交互;innobackupex 脚本用来备份非 InnoDB 表,同时会调用 xtrabackup 命令来备份 InnoDB 表,还会和 mysqld server 发送命令进行交互,如加读锁(FTWRL)、获取位点(SHOW SLAVE STATUS)等。简单来说,innobackupex 在 xtrabackup 之上做了一层封装。
一般情况下,我们是希望能备份 MyISAM 表的,虽然我们可能自己不用 MyISAM 表,但是 mysql 库下的系统表是 MyISAM 的,因此备份基本都通过 innobackupex 命令进行;另外一个原因是我们可能需要保存位点信息。
另外2个工具相对小众些,xbcrypt 是加解密用的;xbstream 类似于tar,是 Percona 自己实现的一种支持并发写的流文件格式。两都在备份和解压时都会用到(如果备份用了加密和并发)。
本文的介绍的主角是 innobackupex 和 xtrabackup。
原理
通信方式
2个工具之间的交互和协调是通过控制文件的创建和删除来实现的,主要文件有:
- xtrabackup_suspended_1
- xtrabackup_suspended_2
- xtrabackup_log_copied
举个栗子,我们来看备份时 xtrabackup_suspended_2 是怎么来协调2个工具进程的
innobackupex在启动xtrabackup进程后,会一直等xtrabackup备份完 InnoDB 文件,方式就是等待 xtrabackup_suspended_2 这个文件被创建出来;xtrabackup在备完 InnoDB 数据后,就在指定目录下创建出这个文件,然后等这个文件被innobackupex删除;innobackupex检测到文件 xtrabackup_suspended_2 被创建出来后,就继续往下走;innobackupex在备份完非 InnoDB 表后,删除 xtrabackup_suspended_2 这个文件,这样就通知xtrabackup可以继续了,然后等 xtrabackup_log_copied 被创建;xtrabackup检测到 xtrabackup_suspended_2 文件删除后,就可以继续往下了。
是不是感觉有点不可思议,通过文件是否存在来控制进程,这种方式非常的不靠谱,因为非常容易被外部干扰,比如文件被别人误删掉,或者2个正在跑的备份控制文件误放在同一个目录下,就等着备份乱掉吧,但是 Percona 就是这么干的。
之所以这么搞,估计主要是因为 perl 和 C 二进制2个进程,没有既好用又方便的通信方式,搞个协议啥的太麻烦了。但是官方也觉得这种方式不靠谱,11年就搞了个 blueprint 要用C重写 innobackupex,终于在2.3 版本实现了,innobackupex 功能全部集成到 xtrabackup 里面,只有一个 binary,另外为了使用上的兼容考虑,innobackupex作为 xtrabackup 的一个软链。对于二次开发来说,2.3 摆脱了之前2个进程协作的负担,架构上明显要好于之前版本。考虑到 perl + C 这种架构的长期存在,大多数读者朋友也基本用的2.3之前版本,本文的介绍也是基于老的架构(2.2版本),但是原理和2.3是一样的,只是实现上的差别。
备份过程
整个备份过程如下图:
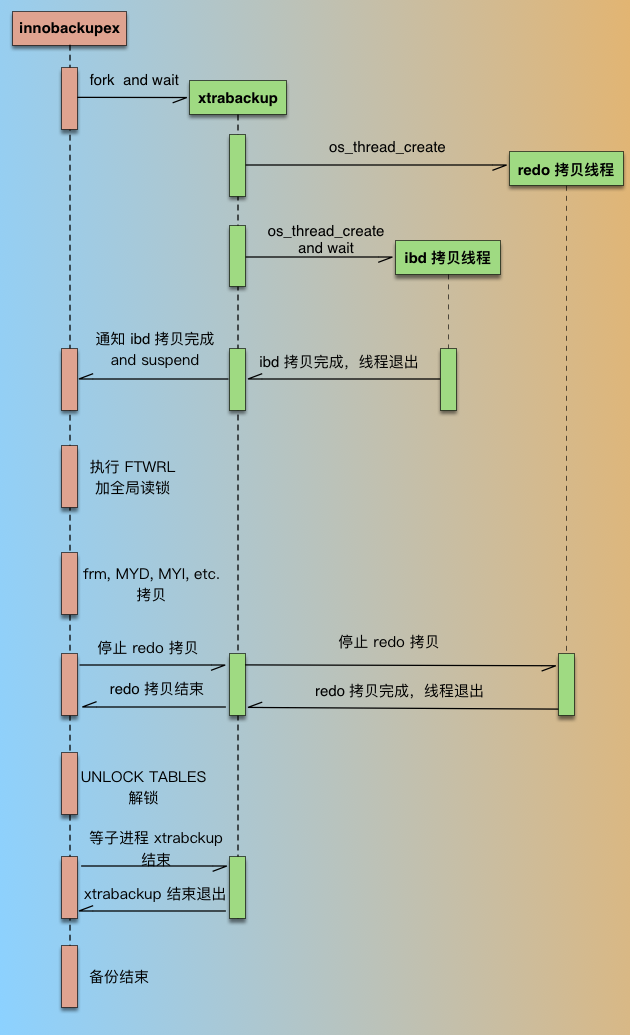
PXB 备份过程
innobackupex在启动后,会先 fork 一个进程,启动xtrabackup进程,然后就等待xtrabackup备份完 ibd 数据文件;xtrabackup在备份 InnoDB 相关数据时,是有2种线程的,1种是 redo 拷贝线程,负责拷贝 redo 文件,1种是 ibd 拷贝线程,负责拷贝 ibd 文件;redo 拷贝线程只有一个,在 ibd 拷贝线程之前启动,在 ibd 线程结束后结束。xtrabackup进程开始执行后,先启动 redo 拷贝线程,从最新的 checkpoint 点开始顺序拷贝 redo 日志;然后再启动 ibd 数据拷贝线程,在xtrabackup拷贝 ibd 过程中,innobackupex进程一直处于等待状态(等待文件被创建)。xtrabackup拷贝完成idb后,通知innobackupex(通过创建文件),同时自己进入等待(redo 线程仍然继续拷贝);innobackupex收到xtrabackup通知后,执行FLUSH TABLES WITH READ LOCK(FTWRL),取得一致性位点,然后开始备份非 InnoDB 文件(包括 frm、MYD、MYI、CSV、opt、par等)。拷贝非 InnoDB 文件过程中,因为数据库处于全局只读状态,如果在业务的主库备份的话,要特别小心,非 InnoDB 表(主要是MyISAM)比较多的话整库只读时间就会比较长,这个影响一定要评估到。- 当
innobackupex拷贝完所有非 InnoDB 表文件后,通知xtrabackup(通过删文件) ,同时自己进入等待(等待另一个文件被创建); xtrabackup收到innobackupex备份完非 InnoDB 通知后,就停止 redo 拷贝线程,然后通知innobackupexredo log 拷贝完成(通过创建文件);innobackupex收到 redo 备份完成通知后,就开始解锁,执行UNLOCK TABLES;- 最后
innobackupex和xtrabackup进程各自完成收尾工作,如资源的释放、写备份元数据信息等,innobackupex等待xtrabackup子进程结束后退出。
在上面描述的文件拷贝,都是备份进程直接通过操作系统读取数据文件的,只在执行 SQL 命令时和数据库有交互,基本不影响数据库的运行,在备份非 InnoDB 时会有一段时间只读(如果没有MyISAM表的话,只读时间在几秒左右),在备份 InnoDB 数据文件时,对数据库完全没有影响,是真正的热备。
InnoDB 和非 InnoDB 文件的备份都是通过拷贝文件来做的,但是实现的方式不同,前者是以page为粒度做的(xtrabackup),后者是 cp 或者 tar 命令(innobackupex),xtrabackup 在读取每个page时会校验 checksum 值,保证数据块是一致的,而 innobackupex 在 cp MyISAM 文件时已经做了flush(FTWRL),磁盘上的文件也是完整的,所以最终备份集里的数据文件都是写入完整的。
增量备份
PXB 是支持增量备份的,但是只能对 InnoDB 做增量,InnoDB 每个 page 有个 LSN 号,LSN 是全局递增的,page 被更改时会记录当前的 LSN 号,page中的 LSN 越大,说明当前page越新(最近被更新)。每次备份会记录当前备份到的LSN(xtrabackup_checkpoints 文件中),增量备份就是只拷贝LSN大于上次备份的page,比上次备份小的跳过,每个 ibd 文件最终备份出来的是增量 delta 文件。
MyISAM 是没有增量的机制的,每次增量备份都是全部拷贝的。
增量备份过程和全量备份一样,只是在 ibd 文件拷贝上有不同。
恢复过程
如果看恢复备份集的日志,会发现和 mysqld 启动时非常相似,其实备份集的恢复就是类似 mysqld crash后,做一次 crash recover。
恢复的目的是把备份集中的数据恢复到一个一致性位点,所谓一致就是指原数据库某一时间点各引擎数据的状态,比如 MyISAM 中的数据对应的是 15:00 时间点的,InnoDB 中的数据对应的是 15:20 的,这种状态的数据就是不一致的。PXB 备份集对应的一致点,就是备份时FTWRL的时间点,恢复出来的数据,就对应原数据库FTWRL时的状态。
因为备份时 FTWRL 后,数据库是处于只读的,非 InnoDB 数据是在持有全局读锁情况下拷贝的,所以非 InnoDB 数据本身就对应 FTWRL 时间点;InnoDB 的 ibd 文件拷贝是在 FTWRL 前做的,拷贝出来的不同 ibd 文件最后更新时间点是不一样的,这种状态的 ibd 文件是不能直接用的,但是 redo log 是从备份开始一直持续拷贝的,最后的 redo 日志点是在持有 FTWRL 后取得的,所以最终通过 redo 应用后的 ibd 数据时间点也是和 FTWRL 一致的。
所以恢复过程只涉及 InnoDB 文件的恢复,非 InnoDB 数据是不动的。备份恢复完成后,就可以把数据文件拷贝到对应的目录,然后通过mysqld来启动了。
XtraBackup 备份原理的更多相关文章
- mysqldump和xtrabackup备份原理实现说明
背景: MySQL数据库备份分为逻辑备份和物理备份两大类,犹豫到底用那种备份方式的时候先了解下它们的差异: 逻辑备份的特点是:直接生成SQL语句,在恢复的时候执行备份的SQL语句实现数据库数据的重现. ...
- xtrabackup备份原理及流式备份应用
目录 xtrabackup备份原理及流式备份应用 0. 参考文献 1. xtrabackup 安装 2. xtrabackup 备份和恢复原理 2.1 备份阶段(backup) 2.2 准备阶段(pr ...
- Percona XtraBackup 备份原理说明【转】
本文来自:http://mysql.taobao.org/monthly/2016/03/07/ 前言 Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MyS ...
- MySQL · 物理备份 · Percona XtraBackup 备份原理
http://mysql.taobao.org/monthly/2016/03/07/ 前言 Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MySQL 数据 ...
- Percona XtraBackup 备份原理
前言 Percona XtraBackup(简称PXB)是 Percona 公司开发的一个用于 MySQL 数据库物理热备的备份工具,支持 MySQl(Oracle).Percona Server 和 ...
- xtrabackup备份原理
Percona XtraBackup工作原理 Percona XtraBackup是基于InnoDB的崩溃恢复功能.复制InnoDB数据文件,导致内部不一致的数据; 但随后它对文件执行崩溃恢复,使它们 ...
- mysqldump+mydumper+xtrabackup备份原理流程
mysqldump备份原理 备份的基本流程如下: 1.调用FTWRL(flush tables with read lock),全局禁止读写 2.开启快照读,获取此时的快照(仅对innodb表起作用) ...
- 从源码分析 XtraBackup 的备份原理
MySQL物理备份工具,常用的有两个:MySQL Enterprise Backup 和 XtraBackup. 前者常用于MySQL企业版,后者常用于MySQL社区版.Percona Server ...
- xtrabackup备份还原mariadb数据库
一.xtrabackup 简介 xtrabackup 是由percona公司开源免费的数据库热备软件,它能对InnoDB数据库和XtraDB存储引擎的数据库非阻塞地备份,对于myisam的备份同样需要 ...
随机推荐
- JQuery返回Json日期格式的問題
用JQuery Ajax返回一個Entity的Json數據時,如果Entity的屬性中有日期格式,那返回來的是一串字符串,如下圖所示: 在網上找了很久也沒有找到一個好的解決方案,最後自己寫一個java ...
- protobuf 协议 windows 下 C++ 环境搭建
1. 下载protobuf https://code.google.com/p/protobuf/downloads/list Protocol Buffers 2.5.0 full source - ...
- ansible的安装过程 和基本使用
之前安装了一遍,到最后安装成功的时候出现了这种问题: [root@localhost ~]# ansible webserver -m command -a 'uptime' ............ ...
- java web 程序---投票系统
1.这里会连接数据库--JDBC的学习实例 一共有3个页面. 2.第一个页面是一个form表单,第二个页面是处理数据,第三个页面是显示页面 vote.jsp <body bgcolor=&quo ...
- ASP.NET Web Pages:发布网站
ylbtech-.Net-ASP.NET Web Pages:发布网站 1.返回顶部 1. ASP.NET Web Pages - 发布网站 学习如何在不使用 WebMatrix 的情况下发布 Web ...
- [转]身份证从 15 >> 18
身份证号码的结构和表达形式 1.号码的结构 由十七位数字本体码和一位效验码组成.排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字效验码.2.地址码 表示编码对象常住 ...
- 1042 Shuffling Machine (20 分)
1042 Shuffling Machine (20 分) Shuffling is a procedure used to randomize a deck of playing cards. Be ...
- [UE4]把工程升级到最新版本
右键UE4工程文件,选择“Switch Unreal Engine version...” 确定后,再次双击打开工程升级到最新版本了.
- centos自带的dvd中的官方base源,丢失了可以复制下面的内容
/etc/yum.repos.d/CentOS-Base.repo文件中的内容,同样适用于centos6 [base]name=CentOS-$releasever - Basemirrorlist= ...
- unity3d中物体的控制
一.物体的循环移动和旋转 思路:通过对时间的计算,每隔一段时间让物体旋转,实现来回移动. float TranslateSpeed = 0.02f; float TranslateSpeedTime ...