10 并发编程-(线程)-GIL全局解释器锁&死锁与递归锁
一、GIL全局解释器锁
1、引子
在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。
就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。>有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。
所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
2、GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test.py,python aaa.py,python bbb.py会产生3个不同的python进程
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
3、GIL与Lock
机智的同学可能会问到这个问题:Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
首先,我们需要达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
然后,我们可以得出结论:保护不同的数据就应该加不同的锁。
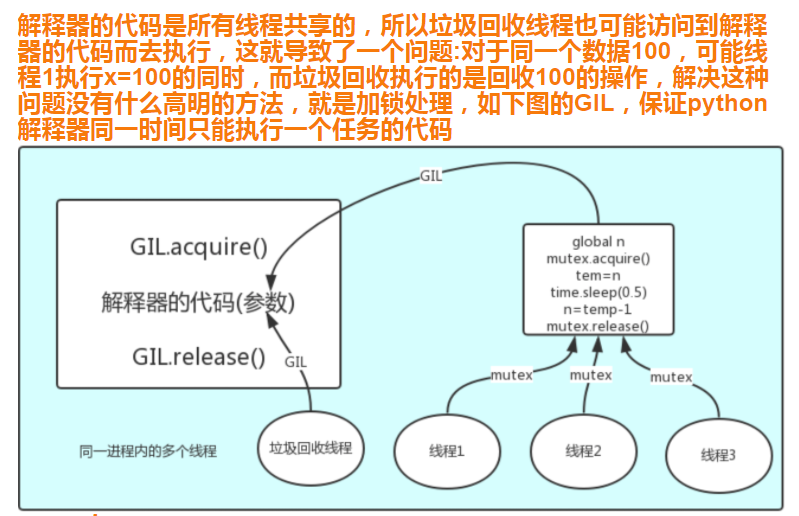
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock,如下图
1、100个线程去抢GIL锁,即抢执行权限
2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
4、GIL与多线程(计算密集型用 多进程 I/O密集型用 多线程)
应用:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
如果并发的多个任务是计算密集型:多进程效率高
from multiprocessing import Process
from threading import Thread
import os,time
def work():
res=0
for i in range(100000000):
res*=i if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(4):
p=Process(target=work) #耗时5s多
p=Thread(target=work) #耗时18s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
如果并发的多个任务是I/O密集型:多线程效率高
#如果并发的多个任务是I/O密集型:多线程效率高
from multiprocessing import Process
from threading import Thread
import threading
import os,time
def work():
time.sleep(2)#类似i/o
# print('===>') if __name__ == '__main__':
l=[]
print(os.cpu_count()) #本机为4核
start=time.time()
for i in range(400):
p=Process(target=work) #耗时14s多,大部分时间耗费在创建进程上,
#p=Thread(target=work) #耗时2s多
l.append(p)
p.start()
for p in l:
p.join()
stop=time.time()
print('run time is %s' %(stop-start))
二、死锁与递归锁
1、死锁现象
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。
此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
from threading import Thread,Lock
import time
mutexA=Lock()
mutexB=Lock() class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire()
print('\033[42m%s 拿到B锁\033[0m' %self.name)
mutexB.release() mutexA.release() def func2(self):
mutexB.acquire()
print('\033[43m%s 拿到B锁\033[0m' %self.name)
time.sleep(2) mutexA.acquire()
print('\033[44m%s 拿到A锁\033[0m' %self.name)
mutexA.release() mutexB.release() if __name__ == '__main__':
for i in range(10):
t=MyThread()
t.start()
执行效果 Thread-1 拿到A锁
Thread-1 拿到B锁
Thread-1 拿到B锁
Thread-2 拿到A锁 #出现死锁,整个程序阻塞住 Thread-1 拿到B锁后要去拿A锁,但A所在Thread-2手上
Thread-2 拿到A锁后要去拿B锁,但B锁在Thread-1手上
2、死锁的解决办法---递归锁
递归锁:可以连续acquire多次,每acquire一次计数器+1,只有计数为0时,才能被抢到
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。
直到一个线程所有的acquire都被release,其他的线程才能获得资源。
上面的例子如果使用RLock代替Lock,则不会发生死锁,二者的区别是:递归锁可以连续acquire多次,而互斥锁只能acquire一次
# 递归锁:可以连续acquire多次,每acquire一次计数器+1,只有计数为0时,才能被抢到acquire
from threading import Thread,RLock
import time mutexB=mutexA=RLock() class MyThread(Thread):
def run(self):
self.f1()
self.f2() def f1(self):
mutexA.acquire()
print('%s 拿到了A锁' %self.name) mutexB.acquire()
# 此时acquire 计数器为2
print('%s 拿到了B锁' %self.name)
mutexB.release() mutexA.release()
# 此时acquire计数器为0 这样其他的线程才可以抢锁 def f2(self):
mutexB.acquire()
print('%s 拿到了B锁' % self.name)
time.sleep(1) mutexA.acquire()
print('%s 拿到了A锁' % self.name)
mutexA.release() mutexB.release() if __name__ == '__main__':
for i in range(10):
t=MyThread()
t.start() Thread-1 拿到了A锁
Thread-1 拿到了B锁
Thread-1 拿到了B锁
Thread-1 拿到了A锁
Thread-2 拿到了A锁
Thread-2 拿到了B锁
Thread-2 拿到了B锁
Thread-2 拿到了A锁
Thread-4 拿到了A锁
Thread-4 拿到了B锁
Thread-4 拿到了B锁
Thread-4 拿到了A锁
Thread-6 拿到了A锁
Thread-6 拿到了B锁
Thread-6 拿到了B锁
Thread-6 拿到了A锁
Thread-8 拿到了A锁
Thread-8 拿到了B锁
Thread-8 拿到了B锁
Thread-8 拿到了A锁
Thread-10 拿到了A锁
Thread-10 拿到了B锁
Thread-10 拿到了B锁
Thread-10 拿到了A锁
Thread-5 拿到了A锁
Thread-5 拿到了B锁
Thread-5 拿到了B锁
Thread-5 拿到了A锁
Thread-9 拿到了A锁
Thread-9 拿到了B锁
Thread-9 拿到了B锁
Thread-9 拿到了A锁
Thread-7 拿到了A锁
Thread-7 拿到了B锁
Thread-7 拿到了B锁
Thread-7 拿到了A锁
Thread-3 拿到了A锁
Thread-3 拿到了B锁
Thread-3 拿到了B锁
Thread-3 拿到了A锁
10 并发编程-(线程)-GIL全局解释器锁&死锁与递归锁的更多相关文章
- python 并发编程 多线程 GIL全局解释器锁基本概念
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念. 就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码. ...
- python网络编程--线程GIL(全局解释器锁)
一:什么是GIL 在CPython,全局解释器锁,或GIL,是一个互斥体防止多个本地线程执行同时修改同一个代码.这把锁是必要的主要是因为当前的内存管理不是线程安全的.(然而,由于GIL存在,其他特性已 ...
- 53_并发编程-线程-GIL锁
一.GIL - 全局解释器锁 有了GIL的存在,同一时刻同一进程中只有一个线程被执行:由于线程不能使用cpu多核,可以开多个进程实现线程的并发,因为每个进程都会含有一个线程,每个进程都有自己的GI ...
- GIL全局解释器锁-死锁与递归锁-信号量-event事件
一.全局解释器锁GIL: 官方的解释:掌握概念为主 """ In CPython, the global interpreter lock, or GIL, is a m ...
- 同步锁 死锁与递归锁 信号量 线程queue event事件
二个需要注意的点: 1 线程抢的是GIL锁,GIL锁相当于执行权限,拿到执行权限后才能拿到互斥锁Lock,其他线程也可以抢到GIL,但如果发现Lock任然没有被释放则阻塞,即便是拿到执行权限GIL也要 ...
- Thread类的其他方法,同步锁,死锁与递归锁,信号量,事件,条件,定时器,队列,Python标准模块--concurrent.futures
参考博客: https://www.cnblogs.com/xiao987334176/p/9046028.html 线程简述 什么是线程?线程是cpu调度的最小单位进程是资源分配的最小单位 进程和线 ...
- python 全栈开发,Day42(Thread类的其他方法,同步锁,死锁与递归锁,信号量,事件,条件,定时器,队列,Python标准模块--concurrent.futures)
昨日内容回顾 线程什么是线程?线程是cpu调度的最小单位进程是资源分配的最小单位 进程和线程是什么关系? 线程是在进程中的 一个执行单位 多进程 本质上开启的这个进程里就有一个线程 多线程 单纯的在当 ...
- python并发编程之线程(创建线程,锁(死锁现象,递归锁),GIL锁)
什么是线程 进程:资源分配单位 线程:cpu执行单位(实体),每一个py文件中就是一个进程,一个进程中至少有一个线程 线程的两种创建方式: 一 from threading import Thread ...
- 线程全局修改、死锁、递归锁、信号量、GIL以及多进程和多线程的比较
线程全局修改 x = 100 def func1(): global x print(x) changex() print(x) def changex(): global x x = 50 func ...
随机推荐
- linux同一台机子上用多个git 账号
Step 1 - Create a New SSH KeyWe need to generate a unique SSH key for our second GitHub account. ssh ...
- Jupyter和IPython
Jupyter内核就是IPython(Interactive Python):你看到的按tab键能够自动提示/补齐都是IPython实现的. IPython其实不只限于IPython,其实你看到的ID ...
- 深入理解ASP.NET MVC(2)
系列目录 请求是如何进入MVC框架的(inbound) 当一个URL请求到来时,系统调用一个注册的IHttpModules:UrlRoutingModule,它将完成如下工作: 一.在RouteTab ...
- 【python】实例-判断用户输入数字的类型
num=input("please input the num: ") print "the number your input is: "+str(num) ...
- DCNN相关算法资料
https://blog.csdn.net/hjimce/article/details/49955149 讲的很详细
- 【Spring学习笔记-MVC-9】SpringMVC数据格式化之日期转换@DateTimeFormat
作者:ssslinppp 1. 摘要 本文主要讲解Spring mvc数据格式化的具体步骤: 并讲解前台日期格式如何转换为java对象: 在之前的文章<[Spring学习笔记-MVC ...
- 关于String str =new String("abc")和 String str = "abc"的比较--转
原文地址:https://www.cnblogs.com/OnlyCT/p/5433410.html String是一个非常常用的类,应该深入的去了解String 如: String str =new ...
- python 用到的函数记录
1. ctime() 获取当前的时间 2. import random random.randint(0,99) 随机产生0到99之间的数值 (包含0和99) (整数!!) 3. 往列表添加数值 l ...
- 廖雪峰Java1-2程序基础-5浮点数运算
1.浮点数运算的特点 很多浮点数无法精确表示 计算有误差 整型可以自动提升到浮点型 如0.1用二进制表示会是一个无限循环的小数.计算机不可能在有限内存中表示一个无限小数.因此浮点数不能精确表示.也造成 ...
- Linux 期中架构 PHP
环境 PHP安装前准备 先将需要的软件包如下位置放置.另外需要有WWW用户 参照nginx 满足以上条件后执行安装脚本 PHP安装脚本: #!/bin/bash #install PHP #au ...