mycat分布式mysql中间件(自增主键)
一、全局序列号
全局序列号是MyCAT提供的一个新功能,为了实现分库分表情况下,表的主键是全局唯一,而默认的MySQL的自增长主键无法满足这个要求。全局序列号的语法符合标准SQL规范,其格式为:
next value for MYCATSEQ_XXX
MYCATSEQ_XXX 是序列号的名字,MyCAT自动创建新的序列号,免去了开发的复杂度,另外,MyCAT也提供了一个全局的序列号,名称为:MYCATSEQ_GLOBAL
注意,MYCATSEQ_必须大写才能正确识别。
MyCAT温馨提示:实践中,建议每个表用自己的序列号,序列号的命名建议为MYCATSEQ _tableName_ID_SEQ。
SQL中使用说明
自定义序列号的标识为:MYCATSEQ_XXX ,其中XXX为具体定义的sequence的名称,应用举例如下:
使用默认的全局sequence :
insert into tb1(id,name) values(next value for MYCATSEQ_GLOBAL,'micmiu.com');
使用自定义的 sequence :
insert into tb2(id,name) values(next value for MYCATSEQ_MY1,'micmiu.com');
获取最新的值
Select next value for MYCATSEQ_xxx
全局序列号可通过多种方式提供
1)本地文件
2) 数据库方式:
3)本地时间戳算法:
1)本地文件
1. 配置server.xml
<property name="sequnceHandlerType">0</property>
2. 配置sequence_conf.properties
#default global sequence
GLOBAL.HISIDS=
GLOBAL.MINID=10001
GLOBAL.MAXID=20000
GLOBAL.CURID=10000
# self define sequence
COMPANY.HISIDS=
COMPANY.MINID=1001
COMPANY.MAXID=2000
COMPANY.CURID=1000
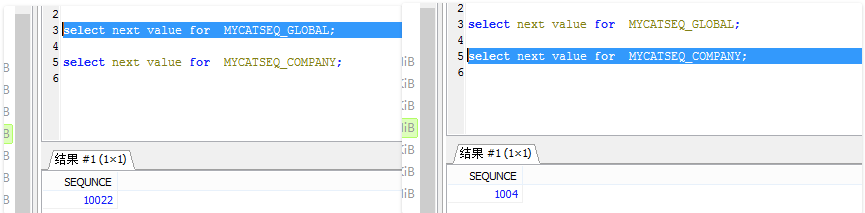
使用示例: insert into table1(id,name) values(next value for MYCATSEQ_GLOBAL,‘test’);
缺点:当 MyCAT 重新发布后,配置文件中的 sequence 会恢复到初始值。
优点:本地加载,读取速度较快。
2) 数据库方式:
1. 配置server.xml
<property name="sequnceHandlerType">1</property>
2. 配置sequence_db_conf.properties
#sequence stored in datanode
GLOBAL=dn1
MYST=dn1
3.数据库本地创建脚本:
DROP TABLE IF EXISTS MYCAT_SEQUENCE;
CREATE TABLE MYCAT_SEQUENCE ( name VARCHAR(50) NOT NULL, current_value INT NOT NULL, increment INT NOT NULL DEFAULT 100, PRIMARY KEY (name) ) ENGINE=InnoDB;
-- ----------------------------
-- Function structure for `mycat_seq_currval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_currval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_currval`(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
DECLARE retval VARCHAR(64);
SET retval="-999999999,null";
SELECT concat(CAST(current_value AS CHAR),",",CAST(increment AS CHAR) ) INTO retval FROM MYCAT_SEQUENCE WHERE name = seq_name;
RETURN retval ;
END
;;
DELIMITER ;
-- ----------------------------
-- Function structure for `mycat_seq_nextval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_nextval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_nextval`(seq_name VARCHAR(50)) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = current_value + increment WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
-- ----------------------------
-- Function structure for `mycat_seq_setval`
-- ----------------------------
DROP FUNCTION IF EXISTS `mycat_seq_setval`;
DELIMITER ;;
CREATE DEFINER=`root`@`%` FUNCTION `mycat_seq_setval`(seq_name VARCHAR(50), value INTEGER) RETURNS varchar(64) CHARSET latin1
DETERMINISTIC
BEGIN
UPDATE MYCAT_SEQUENCE
SET current_value = value
WHERE name = seq_name;
RETURN mycat_seq_currval(seq_name);
END
;;
DELIMITER ;
INSERT INTO MYCAT_SEQUENCE VALUES ('GLOBAL', 0, 100);
SELECT MYCAT_SEQ_SETVAL('GLOBAL', 1);
SELECT MYCAT_SEQ_CURRVAL('GLOBAL');
SELECT MYCAT_SEQ_NEXTVAL('GLOBAL');
4.插入序列数据:
INSERT INTO MYCAT_SEQUENCE VALUES ('GLOBAL', 0, 100);
INSERT INTO MYCAT_SEQUENCE VALUES ('GLOBAL', 0, 100);
脚本下载:/attached/file/20150323/20150323175900_382.txt
说明:
• 在某个分区(dataNode)数据库上创建序列号相关的表格和函数,SQL脚本在doc目录下的sequnce-sql.txt中,需要在数据库上而非Mycat上执行。
• Mycat_home/conf/quence_db_conf.properties 中记录了sequnce所存放的db对应的配置信息。
#sequence stored in datanode
GLOBAL=dn1
COMPANY=dn1
CUSTOMER=dn1
• 在sequnce表中,插入相应的sequnce记录,并确定其初始值,以及增长步长,步长建议一个合适的范围,比如50-500,需要在数据库上而非Mycat上执行。
INSERT INTO MYCAT_SEQUENCE VALUES ('GLOBAL', 0, 100);
• 修改sequnce的当前值为某个新值,需要在数据库上而非Mycat上执行。
SELECT mycat_seq_curval('GLOBAL');
提示:步长选择多大,取决与你数据插入的TPS,假如是每秒1000个,则步长为1000×60=6万,也不是很大,即60秒会重新从数据库读取下一批次的序列号值。
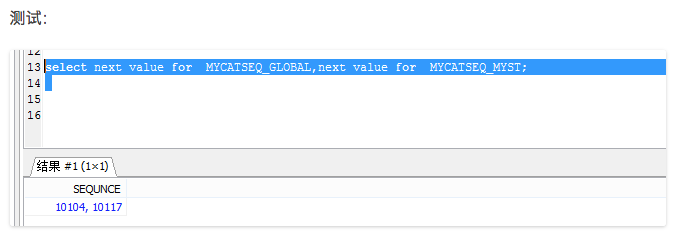
3)本地时间戳算法:
ID= 64位二进制 (42(毫秒)+5(机器ID)+5(业务编码)+12(重复累加)
换算成十进制为18位数的long类型,每毫秒可以并发12位二进制的累加。
使用方式:
a. 配置server.xml
<property name="sequnceHandlerType">2</property>
b. 在mycat下配置:sequence_time_conf.properties
WORKID=0-31 任意整数
DATAACENTERID=0-31 任意整数
多个个mycat节点下每个mycat配置的 WORKID,DATAACENTERID不同,组成唯一标识,总共支持32*32=1024种组合。
ID示例:56763083475511
自增主键配置:
从MyCAT 1.3开始,支持自增长主键,依赖于全局序列号机制,建议采用数据库方式的全局序列号,并正确设置步长,以免影响实际性能。
首先要开启数据库方式的全局序列号,对于需要定义自增长主键的表,建立对应的全局序列号,与table名称同名大写,
如customer序列名为CUSTOMER,然后再 schema.xml 中对customer表的table元素增加属性autoIncrement值为true.
<table name=”CUSTOMER” autoIncrement=”true”>
执行insert into customer (name,company_id,sharding_id) values ('test',2,10000);查看效果,
暂不支持主键为null如:insert into customer (id,name,company_id,sharding_id) values (null,'test',2,10000);
应用如何获得自增主键:
MyCAT自增字段和返回生成的主键ID的经验分享
说明:
1、mysql本身对非自增长主键,使用last_insert_id()是不会返回结果的,只会返回0.
2、mysql只会对定义自增长主键,可以用last_insert_id()返回主键值。
mycat目前提供了自增长主键功能,但是如果对应的mysql节点上数据表,没有定义auto_increment,
那么在mycat层调用last_insert_id()也是不会返回结果的。
正确使用方式如下:
1、mysql定义自增主键
CREATE TABLE `tt2` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT, //必须是自增的
`nm` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MYISAM AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
2、mycat定义自增
[root@test conf]# vim schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- random sharding using mod sharind rule -->
<!-- autoIncrement="true" 属性-->
<table name="tt2" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3,dn4,dn5" rule="mod-long" />
<table name="mycat_sequence" primaryKey="name" dataNode="dn1"/>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<dataNode name="dn4" dataHost="localhost1" database="db4" />
<dataNode name="dn5" dataHost="localhost1" database="db5" />
<dataHost name="localhost1" maxCon="1000" minCon="20" balance="0" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="127.0.0.1:3366" user="root" password="123456">
</writeHost>
</dataHost>
</mycat:schema>
3、mycat对应sequence_db_conf.properties增加相应设置;
4、mycat的对应mycat_sequence增加对应记录。
5、链接mycat,测试结果如下:
127.0.0.1/root:[TESTDB> insert into tt2(nm) values (99);
Query OK, 1 row affected (0.14 sec)
127.0.0.1/root:[TESTDB> select last_insert_id();
+------------------+
| LAST_INSERT_ID() |
+------------------+
| 101 |
+------------------+
1 row in set (0.01 sec)
关于批量插入使用:
如果没有用mycat 的全局序列号,是普通的批量插入 :
insert(a,b,c) values(x,x,x),(x,x,x);
如果用了全局序列号必须加注解:
/*!mycat:catlet=demo.catlets.BatchInsertSequence */insert(a,b,c) values(x,x,x),(x,x,x);
是sharding key 必须包含在列枚举中,特别是主键是自增的时候必须显示调用:
/*!mycat:catlet=demo.catlets.BatchInsertSequence */insert(id,a,b,c) values(,next value for MYCATSEQ_ID,x,x,x),(next value for MYCATSEQ_ID,x,x,x);
mycat分布式mysql中间件(自增主键)的更多相关文章
- MYSQL获取自增主键【4种方法】
通常我们在应用中对mysql执行了insert操作后,需要获取插入记录的自增主键.本文将介绍java环境下的4种方法获取insert后的记录主键auto_increment的值: 通过JDBC2.0提 ...
- Mysql对自增主键ID进行重新排序
Mysql数据库表的自增主键ID号经过一段时间的添加与删除之后乱了,需要重新排列. 原理:删除原有的自增ID,重新建立新的自增ID. 1,删除原有主键: ALTER TABLE `table_name ...
- MYSQL获取自增主键【4种方法】(转)
转自:http://blog.csdn.net/ultrani/article/details/9351573 作者已经写的非常好了,我不废话了,直接转载收藏: 通常我们在应用中对mysql执行了in ...
- mysql 获取自增主键
MyBatis 3.2.6插入时候获取自增主键方法有二 以MySQL5.5为例: 方法1: <insert id="insert" parameterType="P ...
- mybatis用mysql数据库自增主键,插入一条记录返回新增记录的自增主键ID
今天在敲代码的时候遇到一个问题,就是往数据库里插入一条记录后需要返回这个新增记录的ID(自增主键), 公司框架用的是mybatis的通用Mapper接口,里面的插入方法貌似是不能把新纪录的ID回填到对 ...
- mysql建立自增主键的插入,及自动插入当前时间
MYSQL里用这两个字段,几乎都是必须的. 以前都是自动建立的,现在手把手建立的时候,就要找资料来搞定了. 参考URL: http://blog.csdn.net/Weicleer/article/d ...
- mysql 设置自增主键id的起始值
修改user表,主键自增从20000开始 alter table user AUTO_INCREMENT=20000;
- mycat分布式mysql中间件(数据库切分概述)[转]
mysql数据库切分 前言 通 过MySQLReplication功能所实现的扩展总是会受到数据库大小的限制,一旦数据库过于庞大,尤其是当写入过于频繁,很难由一台主机支撑的时 候,我们还是会面临到扩展 ...
- Mysql修改自增主键的起始值及查询自增主键的下一个值
MySQL [xxx_mall]> alter table shop_base_info AUTO_INCREMENT=11000;Query OK, 0 rows affected (0.0 ...
随机推荐
- python 采坑总结 调用键盘事件后导致键盘失灵的可能原因
在练习python封装键盘事件的时候,实现一个keyDown和keyUp的功能: @staticmethod def keyDown(keyName): #按下按键 ...
- CentOS安装mysql并配置远程访问
最近上班挺无聊,每天就是不停的重启重启重启,然后抓log.于是有事儿没事儿的看卡闲书,搞搞其他事情. 但是,公司笔记本装太多乱其八糟的东西也还是不太好. 于是,想到了我那个当VPN server的VP ...
- python的时间处理-time模块
time模块 时间的表示方法有三种: 时间戳:表示的是从1970年1月1日0点至今的秒数 格式化字符串表示:这种表示更习惯我们通常的读法,如2018-04-24 00:00:00 格式化元祖表示:是一 ...
- Python之os.path路径模块中的操作方法总结
#os.path模块主要集成了针对路径文件夹的操作功能,这里我们就来看一下Python中的os.path路径模块中的操作方法总结,需要的朋友可以参考下 解析路径路径解析依赖与os中定义的一些变量: o ...
- NFS Iptables放行服务端口
启动NFS会开启如下端口:1)portmapper 端口:111 udp/tcp:2)nfs/nfs_acl 端口:2049 udp/tcp:3)mountd 端口:"32768--6553 ...
- TimeUnit简析
TimeUnit是java.util.concurrent包下面的一个类,主要有两种功能: 1.提供可读性更好的线程暂停操作,通常用来替换Thread.sleep() 2.提供便捷方法用于把时间转换成 ...
- 安装使用composer基本流程
composer工作原理: 这里经过几个步骤:1.composer读取composer.json(这个文件手动建立,官网有格式),这个json是在当前执行composer目录的,如果目录下没有这个js ...
- Cron表达式详解和表达式的验证
本篇不算原创,因为主要内容来自网上的博客,所以给出我参考文章的链接. 本文cron表达式详解的大部分内容参考了[cron表达式详解]和Quartz使用总结.Cron表达式 这两篇文章. cron校验的 ...
- C#调用托管ocx、dll
前篇文章是调用非托管,比较复杂,这里是调用托管,很简单[所以在遇到非托管dll时可以通过二次封装成托管的方式,再通过这边文章来使用] 1.注意这是基于COM的ocx或者dll,所以用regsvr32先 ...
- 网络安全、Web安全、渗透测试之笔经面经总结(三)
本篇文章涉及的知识点有如下几方面: 1.什么是WebShell? 2.什么是网络钓鱼? 3.你获取网络安全知识途径有哪些? 4.什么是CC攻击? 5.Web服务器被入侵后,怎样进行排查? 6.dll文 ...