[MySQL 5.6] MySQL 5.6 group commit 性能测试及内部实现流程
[MySQL 5.6] MySQL 5.6 group commit 性能测试及内部实现流程
尽管Mariadb以及Facebook在long long time ago就fix掉了这个臭名昭著的问题,但官方直到 MySQL5.6 版本才Fix掉,本文主要关注三点:
1.MySQL 5.6的性能如何
2.在5.6中Group commit的三阶段实现流程
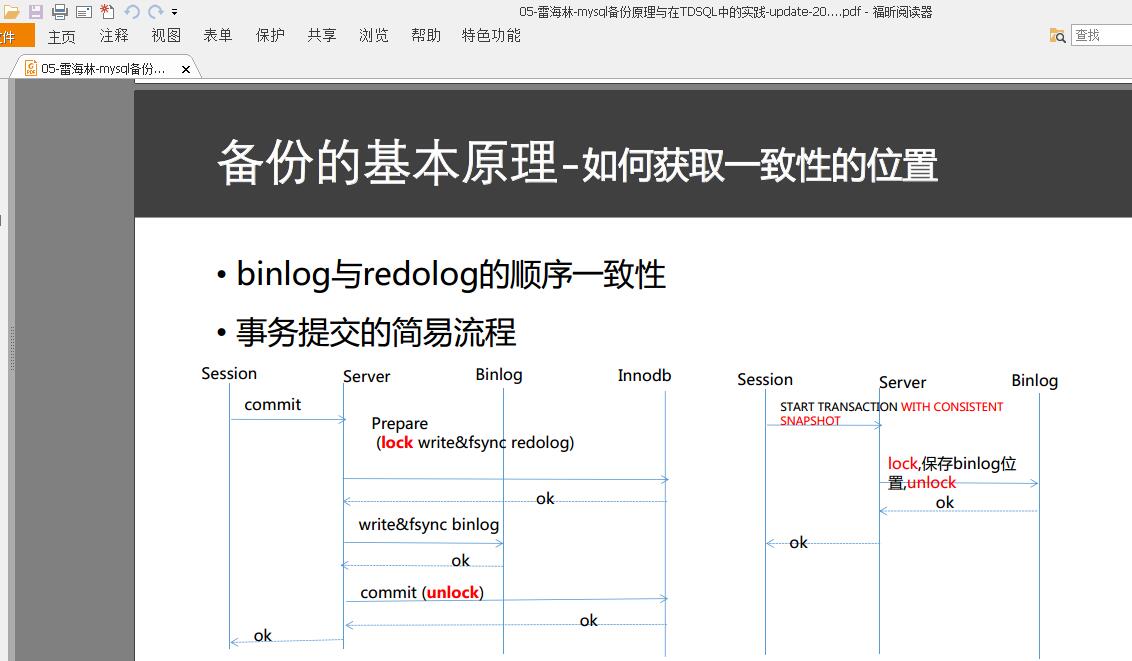
binlog和innodb提交过程,内部xa事务,先写redo log再写binlog,任何一个环节失败,都会回滚事务,保证binlog和redo log一致
http://www.cnblogs.com/MYSQLZOUQI/p/5431472.html
从库比主库多数据 ,主库挂了,写binlog成功从库也应用了binlog,主库起来后回滚数据导致从库比主库多数据 ,原因就是先写redo log再写binlog
http://www.cnblogs.com/MYSQLZOUQI/p/5596590.html
新参数
MySQL 5.6提供了两个参数来控制binlog group commit:
单位为微妙,用于从flush队列中取事务的超时时间,这主要是防止并发事务过高,导致某些事务的RT上升。
可以阅读函数MYSQL_BIN_LOG::process_flush_stage_queue 来理解其功能
当设置为0时,事务可能以和binlog不相同的顺序被提交,从下面的测试也可以看出,这会稍微提升点性能,但并不是特别明显.
性能测试
老规矩,先测试看看性能
sysbench, 全内存操作,5个sbtest表,每个表1000000行数据
基本配置:
innodb_flush_log_at_trx_commit=1
table_open_cache_instances=5
metadata_locks_hash_instances = 32
metadata_locks_cache_size=2048
performance_schema_instrument = ‘%=on’
performance_schema=ON
innodb_lru_scan_depth=8192
innodb_purge_threads = 4
关闭Performance Schema consumer:
mysql> update setup_consumers set ENABLED = ‘NO’;
Query OK, 4 rows affected (0.02 sec)
Rows matched: 12 Changed: 4 Warnings: 0
sysbench/sysbench –debug=off –test=sysbench/tests/db/update_index.lua –oltp-tables-count=5 –oltp-point-selects=0 –oltp-table-size=1000000 –num-threads=1000 –max-requests=10000000000 –max-time=7200 –oltp-auto-inc=off –mysql-engine-trx=yes –mysql-table-engine=innodb –oltp-test-mod=complex –mysql-db=test –mysql-host=$HOST –mysql-port=3306 –mysql-user=xx run
update_index.lua
| threads | sync_binlog = 0 | sync_binlog = 1 | sync_binlog =1binlog_order_commits=0 |
| 1 | 900 | 610 | 620 |
| 20 | 13,800 | 7,000 | 7,400 |
| 60 | 20,000 | 14,500 | 16,000 |
| 120 | 25,100 | 21,054 | 23,000 |
| 200 | 27,900 | 25,400 | 27,800 |
| 400 | 33,100 | 30,700 | 31,300 |
| 600 | 32,800 | 31,500 | 29,326 |
| 1000 | 20,400 | 20,200 | 20,500 |
我的机器在压到1000个并发时,CPU已经几乎全部耗完。
可以看到,并发度越高,group commit的效果越好,在达到600以上并发时,设置sync_binlog=1或者0已经没有TPS的区别。
但问题是。我们的业务压力很少会达到这么高的压力,低负载下,设置sync_binlog=1依旧增加了单个线程的开销。
另外也观察到,设置binlog_max_flush_queue_time对TPS的影响并不明显。
实现原理
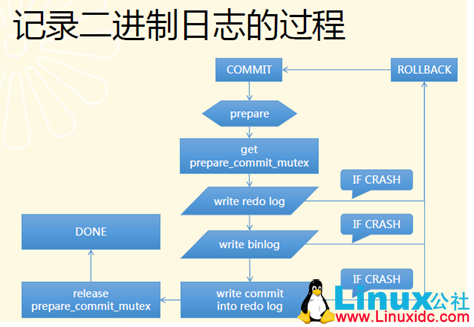
我们知道,binlog和innodb在5.1及以后的版本中采用类似两阶段提交的方式,关于group commit问题的前世今生,可以阅读MATS的博客,讲述的非常详细。嗯,评论也比较有意思。。。。。
以下集中在5.6中binlog如何做group commit。在5.6中,将binlog的commit阶段分为三个阶段:flush stage、sync stage以及commit stage。5.6的实现思路和Mariadb的思路类似,都是维护一个队列,第一个进入该队列的作为leader线程,否则作为follower线程。leader线程收集follower的事务,并负责做sync,follower线程等待leader通知操作完成。
这三个阶段中,每个阶段都会去维护一个队列:
Mutex_queue m_queue[STAGE_COUNTER];
不同session的THD使用the->next_to_commit来链接,实际上,在如下三个阶段,尽管维护了三个队列,但队列中所有的THD实际上都是通过next_to_commit连接起来了。
在binlog的XA_COMMIT阶段(MYSQL_BIN_LOG::commit),完成事务的最后一个xid事件后,,这时候会进入MYSQL_BIN_LOG::ordered_commit,开始3个阶段的流程:
###flush stage
change_stage(thd, Stage_manager::FLUSH_STAGE, thd, NULL, &LOCK_log)
|–>stage_manager.enroll_for(stage, queue, leave_mutex) //将当前线程加入到m_queue[FLUSH_STAGE]中,如果是队列的第一个线程,就被设置为leader,否则就是follower线程,线程会这其中睡眠,直到被leader唤醒(m_cond_done)
|–>leader线程持有LOCK_log锁,从change_state线程返回false.
flush_error= process_flush_stage_queue(&total_bytes, &do_rotate, &wait_queue); //只有leader线程才会进入这个逻辑
|–>首先读取队列,直到队列为空,或者超时(超时时间是通过参数binlog_max_flush_queue_time来控制)为止,对读到的每个线程做flush_thread_caches,将binlog刷到cache中。注意在出队列的时候,可能还有新的session被append到队列中,设置超时的目的也正在于此
|–>如果是超时,这时候队列中还有session的话,就取出整个队列的头部线程,并将原队列置空(fetch_queue_for),然后对取出的session进行flush_thread_caches
|–>判断总的写入binlog的byte数是否超过max bin log size,如果超过了,就设置rotate标记
flush_error= flush_cache_to_file(&flush_end_pos);
|–>将I/O Cache中的内容写到文件中
signal_update() //通知dump线程有新的Binlog
###sync stage
change_stage(thd, Stage_manager::SYNC_STAGE, wait_queue, &LOCK_log, &LOCK_sync)
|–>stage_manager.enroll_for(stage, queue, leave_mutex) //当前线程加入到m_queue[SYNC_STAGE]队列中,释放lock_log锁;同样的如果是SYNC_STAGE队列的leader,则立刻返回,否则进行condition wait.
|–>leader线程加上Lock_sync锁
final_queue= stage_manager.fetch_queue_for(Stage_manager::SYNC_STAGE); //从SYNC_STAGE队列中取出来,并清空队列,主要用于commit阶段
std::pair<bool, bool> result= sync_binlog_file(false); //刷binlog 文件(如果设置了sync_binlog的话)
简单的理解就是,在flush stage阶段形成N批的组session,在SYNC阶段又会由这N批组产生出新的leader来负责做最耗时的sync操作
###commit stage
commit阶段受到参数binlog_order_commits限制
当binlog_order_commits关闭时,直接unlock LOCK_sync,由各个session自行进入Innodb commit阶段(随后调用的finish_commit(thd)),这样不会保证binlog和事务commit的顺序一致,如果你不关注innodb的ibdata中记录的binlog信息,那么可以关闭这个选项来稍微提高点性能
当打开binlog_order_commits时,才会进入commit stage,如下描述的
change_stage(thd, Stage_manager::COMMIT_STAGE,final_queue, &LOCK_sync, &LOCK_commit)
|–>进入新的COMMIT_STAGE队列,释放LOCK_sync锁,新的leader获取LOCK_commit锁,其他的session等待
THD *commit_queue= stage_manager.fetch_queue_for(Stage_manager::COMMIT_STAGE); //取出并清空COMMIT_STAGE队列
process_commit_stage_queue(thd, commit_queue, flush_error)
|–>这里会遍历所有的线程,然后调用ha_commit_low->innobase_commit进入innodb层依次提交
完成上述步骤后,解除LOCK_commit锁
stage_manager.signal_done(final_queue);
|–>将所有Pending的线程的标记置为false(thd->transaction.flags.pending= false)并做m_cond_done广播,唤醒pending的线程
(void) finish_commit(the); //如果binlog_order_commits设置为FALSE,就会进入这一步来提交存储引擎层事务; 另外还会更新grid信息
Innodb的group commit和mariadb的类似,都只有两次sync,即在prepare阶段sync,以及sync Binlog文件(双一配置),为了保证rotate时,所有前一个binlog的事件的redo log都被刷到磁盘,会在函数new_file_impl中调用如下代码段: if (DBUG_EVALUATE_IF(“expire_logs_always”, 0, 1) && (error= ha_flush_logs(NULL))) goto end;
ha_flush_logs 会调用存储引擎接口刷日志文件
参考文档
http://dimitrik.free.fr/blog/archives/2012/06/mysql-performance-binlog-group-commit-in-56.html
http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html
MySQL 5.6.10 source code
原创文章,转载请注明: 转载自Simple Life
[MySQL 5.6] MySQL 5.6 group commit 性能测试及内部实现流程的更多相关文章
- MySQL 组提交(group commit)
目录 前言 改进 原理 实现 参数 注意 前言 操作系统使用页面缓存来填补内存和磁盘访问的差距 对磁盘文件的写入会先写入道页面缓存中 由操作系统来决定何时将修改过的脏页刷新到磁盘 确保修改已经持久化到 ...
- [MySQL] Group Commit理解
简单的方法理解MySQL Group Commit原理 一个摆渡将乘客从A点传输到B点 MySQL 5.0 行为 在MySQL 5.0中,摆渡会在A点按顺序搭载乘客,并且传送到B点.A点和B点的来回行 ...
- MySQL组提交(group commit)
MySQL组提交(group commit) 前提: 以下讨论的前提 是设置MySQL的crash safe相关参数为双1: sync_binlog=1 innodb_flush_log_at_trx ...
- mysql 数据操作 单表查询 group by 分组 目录
mysql 数据操作 单表查询 group by 介绍 mysql 数据操作 单表查询 group by 聚合函数 mysql 数据操作 单表查询 group by 聚合函数 没有group by情况 ...
- mysql 数据操作 单表查询 group by 聚合函数
强调: 如果我们用unique的字段作为分组的依据,则每一条记录自成一组,这种分组没有意义 多条记录之间的某个字段值相同,该字段通常用来作为分组的依据 如果按照每个字段都是唯一的进行分组,意味着按照这 ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- Mysql数据库版本高低引起的group by问题
低版本的Mysql,group by限制性比较小,在进行group by时,select的对象可包含多个,但是换成高版本5.6以上好像,使用group by 以后,select的对象必须也已经被聚合, ...
- Group Commit of Binary Log
160222 09:19:26 mysqld_safe Starting mysqld daemon with databases from /data01/mysql 2016-02-22 09:1 ...
- [mysql使用(2)] mysql的一些语法与Oracle的差别
一.表空间 mysql的表空间有共享表空间和独占表空间,独占表空间,其实就是一张表一个表空间,其实也就是一张表一个数据文件,共享表空间似乎有点类似oracle的表空间,不同的表可以保存在同一个数据文件 ...
随机推荐
- 有了Auto Layout,为什么你还是害怕写UITabelView的自适应布局?
本文转载至 http://www.cnblogs.com/ios122/p/4832859.html Apple 算是最重视应用开发体验的公司了.从Xib到StoryBoard,从Auto Layou ...
- 用MyEclipse将Maven Dependencies中的jar包导出
1.右击pom.xml文件,选择Run As ——> Maven build… 2.在打开的页面中,如图输入“dependency:copy-dependencies”,后点击“Run”即可 ...
- 《转载》WIN10 64位系统 32位Python2.7 PIL安装
http://blog.csdn.net/kanamisama0/article/details/53960281 首先安装这个真的出了好多问题,之前装过一次PIL也失败了,就一直没管,今天刚好找了机 ...
- Foxmail邮箱最新应用指南 --如何使用「邮件标签」?
Foxmail邮箱最新应用指南--如何使用「邮件标签」? 最近看到很多的朋友收发电子邮件,现在我们帮助讲解下foxmail的标签功能,可以帮助我们整理我们的邮箱,让重要信息浮出水面. 1.鼠标右键邮件 ...
- Android studio Unable to start the daemon process
Unable to start the daemon process.This problem might be caused by incorrect configuration of the da ...
- Oracle 学习之exists
不相关子查询:子查询的查询条件不依赖于父查询的称为不相关子查询.相关子查询:子查询的查询条件依赖于外层父查询的某个属性值的称为相关子查询,带EXISTS 的子查询就是相关子查询EXISTS表示存在量词 ...
- echarts中关于自定义legend图例文字
formatter有两种形式: - 模板 - 回调函数 模板 使用字符串模板,模板变量为图例名称 {name} formatter: 'Legend {name}' 回调函数 formatter: f ...
- Sass预定义一些常用的样式
一.编写sass文件时, 目录不能有中文, 如: E:\\CPC手机, 会报错exception while processing events: incompatible character enc ...
- vue组件定义方式
一.全局组件 <div id="box"> {{msg}} <my-aaa></my-aaa> </div> var Home = ...
- STM32 ADC转换时间
STM32F103XX的ADC的采样时钟最快14MHz,最快采样率为1MHz. ADC时钟: 这个ADC时钟是从哪来的呢.我们看下面这个STM32的时钟结构图: 我们大多使用STM32的最快PCLK2 ...