在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片
最近看了吴恩达老师的深度学习课程,又看了python深度学习这本书,对深度学习有了大概的了解,但是在实战的时候,
还是会有一些细枝末节没有完全弄懂,这篇文章就用来总结一下用keras实现深度学习算法的时候一些我自己很容易搞错的点。
一、与序列文本有关
1.仅对序列文本进行one-hot编码
比如:使用路透社数据集(包含许多短新闻及其对应的主题,包括46个不同的主题,每个主题有至少10个样本)
from keras.datasets import reuters |
加载数据集时,参数new_words=10000表示将数据限定为前10000个最常出现的单词 有8982个训练样本和2246个测试样本 每个样本都是一个整数列表(表示单词的索引) |
word_index=reuters.get_word_index() |
将索引解码为新闻文本 这里举个例子将训练集的第一条样本取出来,将它解码为文本 |
import numpy as np |
编码数据 把每个样本sequence编码为长度为10000的向量 |
#方法一:自定义one-hot |
标签向量化有两种方法: 第一种是自定义的one-hot编码,将标签列表转换为整数张量 第二种是keras内置的方法 |
2.keras的Embedding层【Embedding层只能作为模型的第一层】
keras.layers.embeddings.Embedding( |
input_dim:字典长度,即输入数据最大下标+1 output_dim:代表全连接嵌入的维度 embeddings_initializer='uniform': embeddings_regularizer=None: embeddings_constraint=None: input_length=None: mask_zero:布尔值,确定是否将输入中的‘0’看作是应该被忽略的‘填充’ 输入 (samples,sequence_length)的2D张量 |
嵌入层将正整数(下标)转换为具有固定大小的向量,如[[4],[20]]->[[0.25,0.1],[0.6,-0.2]]
[[4],[20]]表示一句话由两个单词组成,第一个单词在词向量的位置为4,第二个单词位置为20
而位置为4的单词,对应的二维词向量就是[0.25,0.1];类似,位置为20的单词的词向量为[0.6,-0.2]
下面简单描述一下:
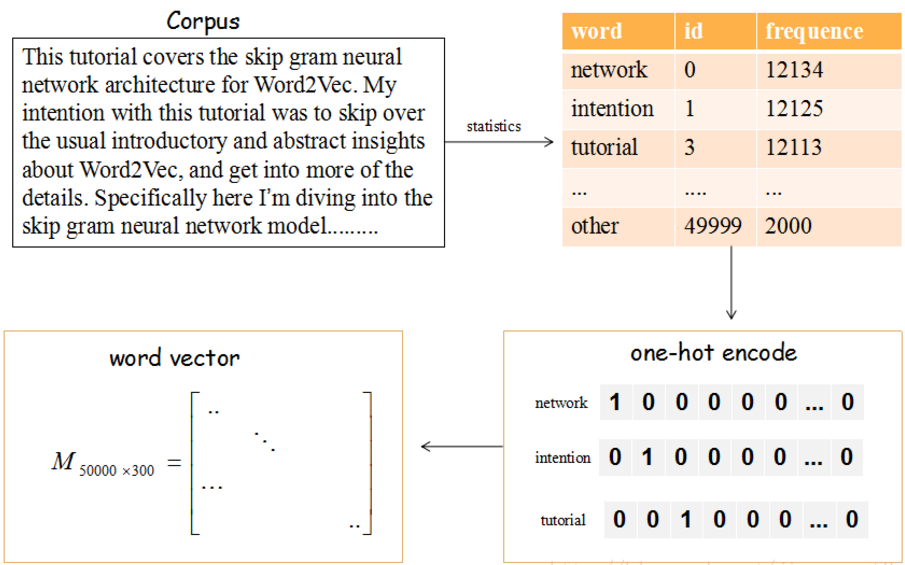
上图的流程是把文章的单词使用词向量来表示。
(1)提取文章所有的单词,把其按其出现的次数降序(这里只取前50000个),比如单词‘network’出现的次数最多,编号ID为0,依次类推…
(2)每个编号ID都可以使用50000维的二进制(one-hot)表示
(3)最后,我们会生产一个矩阵M,行大小为词的个数50000,列大小为词向量的维度(通常取128或300),比如矩阵的第一行就是编号ID=0,即network对应的词向量。
那这个矩阵M怎么获得呢?在Skip-Gram 模型中,我们会随机初始化它,然后使用神经网络来训练这个权重矩阵
3.在Keras模型中使用预训练的词向量
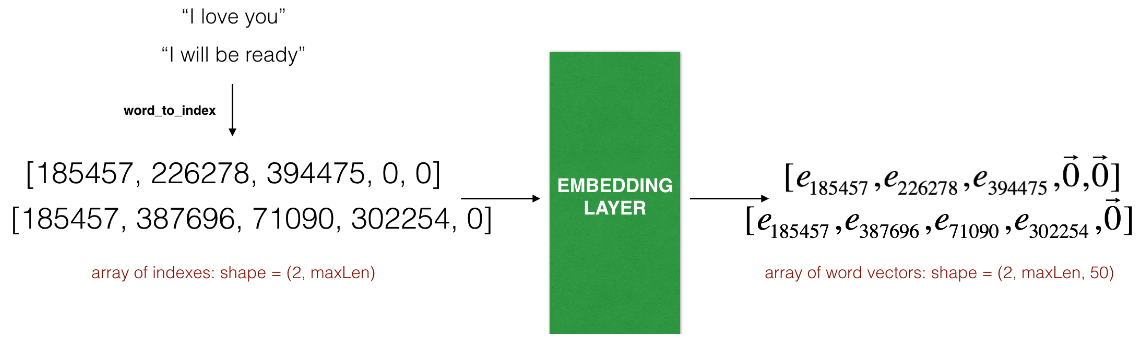
这个例子展示了两个样本通过embedding层,两个样本都经过了`max_len=5`的填充处理,
最终的维度就变成了`(2, max_len, 5)`,这是因为使用了50维的词嵌入。
首先拿到一段文本,要想通过该文本完成分类或其他的任务,就必须要把这个文本转成词向量的形式。
先对训练集进行按行切分(或者,已经有一个所有句子的列表了),然后找到单词数最大的那行作为max_len,这个待会要输入模型中的
对于没达到max_len的句子,可以通过把句子给扩充为max_len长度
import keras.preprocessing.sequence import pad_sequences
pad_sequences(sequences,maxlen=max_len)
然后得到每行单词对应的词向量,现在所有行的维度应该是(行数,单词数最多的那行对应的单词个数,每个单词词向量的维度)
模型的输入是(一批多少序列batch,输入长度input_length) word index单词索引不超过999,词向量的个数上限值1000
输出是(None,10,64) None表示batch的维度(个数),64是每个单词的词向量的维度
model = Sequential()
model.add(Embedding(1000, 64, input_length=10))
input_array = np.random.randint(1000, size=(32, 10))#32句话,每句话10个单词
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
assert output_array.shape == (32, 10, 64) #32句话,每句话10个单词,每个单词有64维的词向量
4. 当多个循环层堆叠时,前面所有循环层中间层都需要返回完整的输出序列,最后一层仅返回最终输出
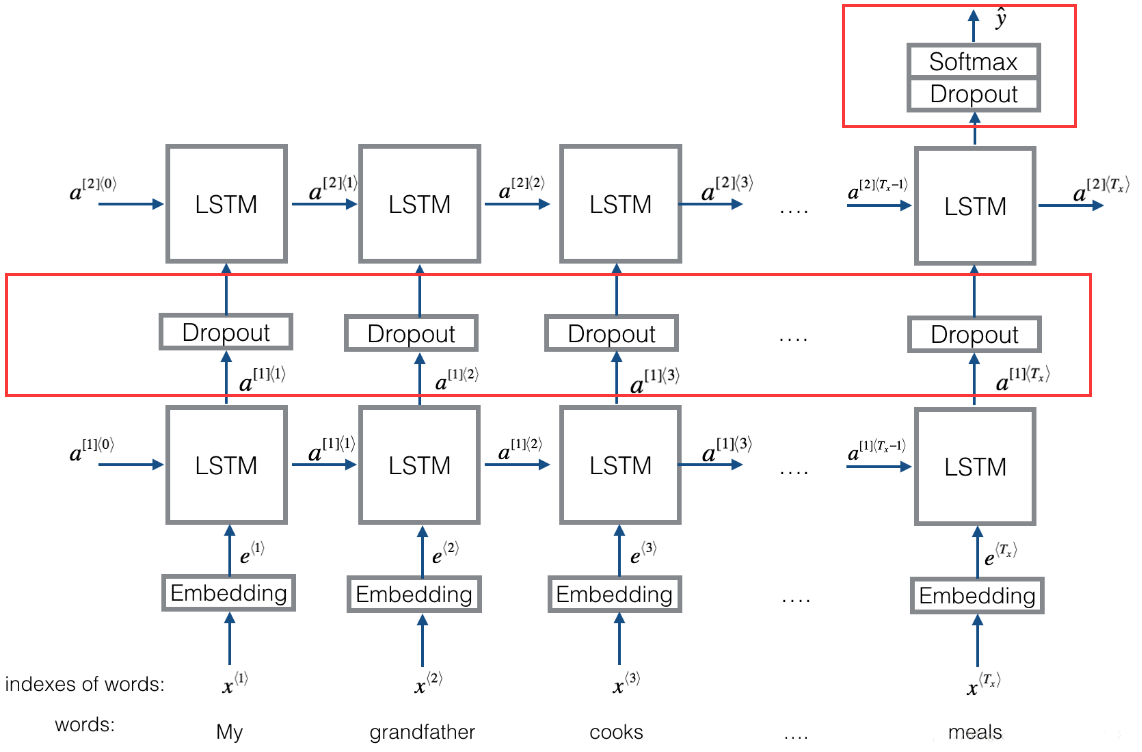
二、与图片数据有关
1.处理一张输入图像,改成模型规定输入格式才能输入模型中
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input,decode_predictions
import numpy as np img_path = '图片的路径'
img = image.load_img(img_path,target_size=(224,224)) #224 224是模型要求输入大小 x = image.img_to_array(image)#将图片转换为(224,224,3)的float32格式的numpy数组 x = np.expand_dims(x,axis=0)#添加一个维度,将数组转换为(1,224,224,3)形状的批量,
#因为keras模型是以batch作为输入的,所以一张图片就相当于batch=1 x = preprocess_input(x)#对批量进行预处理(按通道进行颜色标准化) preds = model.predict(x)
2.输入图像的张量,显示图片
注意:这里图像的张量,取值可能不是[0,255]区间内的整数,需要对这个张量进行后处理,将其转换为可显示的图像
def deprocess_image(x):
x -= x.mean() #对张量做标准化,使其均值为0,标准差为0.1
x /= (x.std() + 1e-5)
x *= 0.1 x += 0.5
x = np.clip(x,0,1) #将x裁切(clip)到[0,1]区间 x *= 255
x = np.clip(x,0,255).astype('uint8') #将x转换为RGB数组
return x #执行下面这句话就能看到图片了
#例:image的大小为(150,150,3)
plt.imshow(deprocess_image(image))
3.我们拿到的训练数据一般不是同一个大小的,需要将图像全部调整成指定大小的
from keras.preprocessing.image import ImageDataGenerator train_datagen = ImageDataGenerator(rescale = 1./255) #将所有图像乘以1/255缩放
test_datagen = ImageDataGenerator(rescale = 1./255) train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),#将所有图像的大小调整为(255,255)
batch_size = 20,
class_mode = 'binary, #这里目标是二分类,所以用二进制标签
)
三、常见的误差与精确性指标
误差
- mean_squared_error / mse 均方误差,常用的目标函数,公式为((y_pred-y_true)**2).mean()
- mean_absolute_error / mae 绝对值均差,公式为(|y_pred-y_true|).mean()
- mean_absolute_percentage_error / mape公式为:(|(y_true - y_pred) / clip((|y_true|),epsilon, infinite)|).mean(axis=-1) * 100,和mae的区别就是,累加的是(预测值与实际值的差)除以(剔除不介于epsilon和infinite之间的实际值),然后求均值。
- mean_squared_logarithmic_error / msle公式为: (log(clip(y_pred, epsilon, infinite)+1)- log(clip(y_true, epsilon,infinite)+1.))^2.mean(axis=-1),这个就是加入了log对数,剔除不介于epsilon和infinite之间的预测值与实际值之后,然后取对数,作差,平方,累加求均值。
- squared_hinge 公式为:(max(1-y_true*y_pred,0))^2.mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的平方的累加均值。
- hinge 公式为:(max(1-y_true*y_pred,0)).mean(axis=-1),取1减去预测值与实际值乘积的结果与0比相对大的值的的累加均值。
- binary_crossentropy: 常说的逻辑回归, 就是常用的交叉熵函数
- categorical_crossentropy: 多分类的逻辑, 交叉熵函数的一种变形吧,没看太明白
精确性
- binary_accuracy: 对二分类问题,计算在所有预测值上的平均正确率
- categorical_accuracy:对多分类问题,计算再所有预测值上的平均正确率
- sparse_categorical_accuracy:与
categorical_accuracy相同,在对稀疏的目标值预测时有用 - top_k_categorical_accracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
- sparse_top_k_categorical_accuracy:与top_k_categorical_accracy作用相同,但适用于稀疏情况
参考文献
一文详解 Word2vec 之 Skip-Gram 模型(结构篇)
在Keras模型中one-hot编码,Embedding层,使用预训练的词向量/处理图片的更多相关文章
- PyTorch在NLP任务中使用预训练词向量
在使用pytorch或tensorflow等神经网络框架进行nlp任务的处理时,可以通过对应的Embedding层做词向量的处理,更多的时候,使用预训练好的词向量会带来更优的性能.下面分别介绍使用ge ...
- 神经网络中embedding层作用——本质就是word2vec,数据降维,同时可以很方便计算同义词(各个word之间的距离),底层实现是2-gram(词频)+神经网络
Embedding tflearn.layers.embedding_ops.embedding (incoming, input_dim, output_dim, validate_indices= ...
- pytorch中如何使用预训练词向量
不涉及具体代码,只是记录一下自己的疑惑. 我们知道对于在pytorch中,我们通过构建一个词向量矩阵对象.这个时候对象矩阵是随机初始化的,然后我们的输入是单词的数值表达,也就是一些索引.那么我们会根据 ...
- NLP直播-1 词向量与ELMo模型
翻车2次,试水2次,今天在B站终于成功直播了. 人气11万. 主要讲了语言模型.词向量的训练.ELMo模型(深度.双向的LSTM模型) 预训练与词向量 词向量的常见训练方法 深度学习与层次表示 LST ...
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史(转载)
转载 https://zhuanlan.zhihu.com/p/49271699 首发于深度学习前沿笔记 写文章 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 张 ...
- zz从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 Bert最近很火,应该是最近最火爆的AI进展,网上的评价很高,那么Bert值得这么高的评价吗?我个人判断是值得.那为什么 ...
- Keras模型拼装
在训练较大网络时, 往往想加载预训练的模型, 但若想在网络结构上做些添补, 可能出现问题一二... 一下是添补的几种情形, 此处以单输出回归任务为例: # 添在末尾: base_model = Inc ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- 预训练语言模型的前世今生 - 从Word Embedding到BERT
预训练语言模型的前世今生 - 从Word Embedding到BERT 本篇文章共 24619 个词,一个字一个字手码的不容易,转载请标明出处:预训练语言模型的前世今生 - 从Word Embeddi ...
随机推荐
- ant重新编译打包hadoop-core-1.2.1.jar时遇到的错
错误1. [root@MyDB01 hadoop]# ant -Dversion=1.2.1 examples 错误: 找不到或无法加载主类 org.apache.tools.ant.launch.L ...
- 23种设计模式之备忘录模式(Memento)
备忘录模式确保在不破坏封装的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态.备忘录模式提供了一种状态恢复的实现机制,使得用户可以方便地回到一个特定 ...
- centos7搭建ELK开源实时日志分析系统
Elasticsearch 是个开源分布式搜索引擎它的特点有分布式零配置自动发现索引自动分片索引副本机制 restful 风格接口多数据源自动搜索负载等. Logstash 是一个完全开源的工具他可以 ...
- Log4net配置之Winform项目
具体方法如下: 一.App.config配置 <?xml version="1.0" encoding="utf-8" ?> <configu ...
- Unity笔记 英保通 Unity新的动画系统Mecanim
Mecanim动画系统是Unity独一无二.强大灵活的人物动画系统.该系统赋予您的人类和非人类人物令人难以置信的自然流畅的动作,使它们栩栩如生.游戏中角色设计提高到了新的层次,在处理人类动画角色中可以 ...
- iOS - 处理计算精度要求很高的数据,floatValue,doubleValue等计算不精确问题
.问题描述:服务器返回的double类型9...94的数字时 .之前处理方式是 :(从内存.cpu计算来说double都是比较合适的,一般情况下都用double) goodsPrice.floatVa ...
- zookeeper 安装的三种模式
Zookeeper安装 zookeeper的安装分为三种模式:单机模式.集群模式和伪集群模式. 单机模式 首先,从Apache官网下载一个Zookeeper稳定版本,本次教程采用的是zookeeper ...
- Elasticsearch 不同的搜索类型之间的区别
1.match 轻量级搜索 GET /wymlib/_search { "query": { "match": { "title": ...
- Kendo UI使用小小记
之所以说小小记,是因为我根本没有好好用它,只是正好前些日子接触了一下,觉得还不错,随手记记~ 契机 我从加入现在这个公司以来,半专业的承担了很多前端相关的事情,用过不少前端框架,也为框架和原生的页面写 ...
- Centos7.2修改时区
设置时区同样, 在 CentOS 7 中, 引入了一个叫 timedatectl 的设置设置程序. 用法很简单: # timedatectl # 查看系统时间方面的各种状态 Local time: 四 ...