python转换html到pdf文件
1.安装wkhtmltopdf
Windows平台直接在 http://wkhtmltopdf.org/downloads.html 下载稳定版的 wkhtmltopdf 进行安装,安装完成之后把该程序的执行路径加入到系统环境 $PATH 变量中,否则 pdfkit 找不到 wkhtmltopdf 就出现错误 “No wkhtmltopdf executable found”
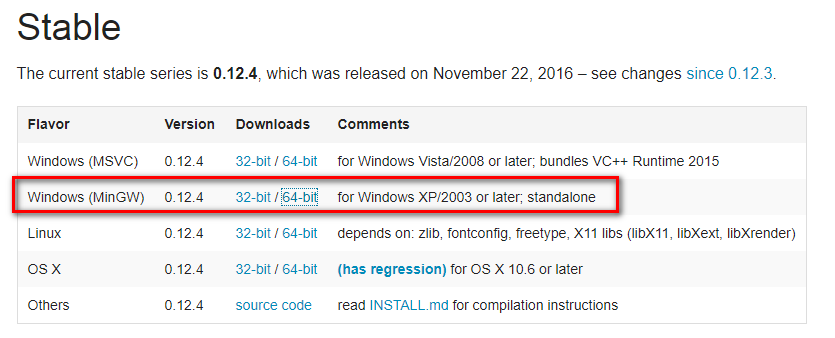
2.安装pdfkit
直接pip install pdfkit
pdfkit 是 wkhtmltopdf 的Python封装包
import pdfkit
# 有下面3中途径生产pdf
pdfkit.from_url('http://google.com', 'out.pdf')
pdfkit.from_file('test.html', 'out.pdf')
pdfkit.from_string('Hello!', 'out.pdf')
3.合并pdf,使用PyPDF2
直接pip install PyPDF2
from PyPDF2 import PdfFileMerger
merger = PdfFileMerger()
input1 = open("1.pdf", "rb")
input2 = open("2.pdf", "rb")
merger.append(input1)
merger.append(input2)
# 写入到输出pdf文档中
output = open("hql_all.pdf", "wb")
merger.write(output)
4.综合示例:
# coding=utf-8
import os
import re
import time
import logging
import pdfkit
import requests
from bs4 import BeautifulSoup
from PyPDF2 import PdfFileMerger html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html> """ def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")[0]
# 标题
title = soup.find('h4').get_text() # 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "(<img .*?src=\")(.*?)(\")" def func(m):
if not m.group(3).startswith("http"):
rtn = m.group(1) + "http://www.liaoxuefeng.com" + m.group(2) + m.group(3)
return rtn
else:
return m.group(1)+m.group(2)+m.group(3)
html = re.compile(pattern).sub(func, html)
html = html_template.format(content=html)
html = html.encode("utf-8")
with open(name, 'wb') as f:
f.write(html)
return name except Exception as e: logging.error("解析错误", exc_info=True) def get_url_list():
"""
获取所有URL目录列表
:return:
"""
response = requests.get("http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000")
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls def save_pdf(htmls, file_name):
"""
把所有html文件保存到pdf文件
:param htmls: html文件列表
:param file_name: pdf文件名
:return:
"""
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'outline-depth': 10,
}
pdfkit.from_file(htmls, file_name, options=options) def main():
start = time.time()
file_name = u"liaoxuefeng_Python3_tutorial"
urls = get_url_list()
for index, url in enumerate(urls):
parse_url_to_html(url, str(index) + ".html")
htmls =[]
pdfs =[]
for i in range(0,124):
htmls.append(str(i)+'.html')
pdfs.append(file_name+str(i)+'.pdf') save_pdf(str(i)+'.html', file_name+str(i)+'.pdf') print u"转换完成第"+str(i)+'个html' merger = PdfFileMerger()
for pdf in pdfs:
merger.append(open(pdf,'rb'))
print u"合并完成第"+str(i)+'个pdf'+pdf output = open(u"廖雪峰Python_all.pdf", "wb")
merger.write(output) print u"输出PDF成功!" for html in htmls:
os.remove(html)
print u"删除临时文件"+html for pdf in pdfs:
os.remove(pdf)
print u"删除临时文件"+pdf total_time = time.time() - start
print(u"总共耗时:%f 秒" % total_time) if __name__ == '__main__':
main()
python转换html到pdf文件的更多相关文章
- 深入学习Python解析并解密PDF文件内容的方法
前面学习了解析PDF文档,并写入文档的知识,那篇文章的名字为深入学习Python解析并读取PDF文件内容的方法. 链接如下:https://www.cnblogs.com/wj-1314/p/9429 ...
- 深入学习python解析并读取PDF文件内容的方法
这篇文章主要学习了python解析并读取PDF文件内容的方法,包括对学习库的应用,python2.7和python3.6中python解析PDF文件内容库的更新,包括对pdfminer库的详细解释和应 ...
- 利用Python将多个PDF文件合并
from PyPDF2 import PdfFileMerger import os files = os.listdir()#列出目录中的所有文件 merger = PdfFileMerger() ...
- 办公室文员必备python神器,将PDF文件表格转换成excel表格!
[阅读全文] 第三方库说明 # PDF读取第三方库 import pdfplumber # DataFrame 数据结果处理 import pandas as pd 初始化DataFrame数据对象 ...
- python从TXT创建PDF文件——reportlab
使用reportlab创建PDF文件电子书一般都是txt格式的,某些电子阅读器不能读取txt的文档,如DPT-RP1.因此本文从使用python实现txt到pdf的转换,并且支持生成目录,目录能够生成 ...
- 【转】Python 深入浅出 - PyPDF2 处理 PDF 文件
实际应用中,可能会涉及处理 pdf 文件,PyPDF2 就是这样一个库,使用它可以轻松的处理 pdf 文件,它提供了读,割,合并,文件转换等多种操作. 文档地址:http://pythonhosted ...
- 利用python第三方库提取PDF文件的表格内容
小爬最近接到一个棘手任务:需要提取手机话费电子发票PDF文件中的数据.接到这个任务的第一时间,小爬决定搜集各个地区各个时间段的电子发票文件,看看其中的差异点.粗略统计下来,PDF文件的表格框架是统一的 ...
- 【转】Python编程: 多个PDF文件合并以及网页上自动下载PDF文件
1. 多个PDF文件合并1.1 需求描述有时候,我们下载了多个PDF文件, 但希望能把它们合并成一个PDF文件.例如:你下载的数个PDF文件资料或者电子发票,你可以使用python程序合并成一个PDF ...
- Python实现多个pdf文件合并
背景 由于工作原因,经常需要将多个pdf文件合并后打印,有时候上网找免费合并工具比较麻烦(公司内网不能访问公网),于是决定搞个小工具. 具体实现 需要安装 PyPDF2 pip install PyP ...
随机推荐
- Spring Mvc如何通过注解的方式设置视图解析器的优先级
<bean id="jspViewResolver" class="org.springframework.web.servlet.view.InternalRes ...
- ios成长之每日一遍(day 8)
这几天都有一些任务要跟, 把ios的学习拉后, 看看要抓紧咯, 看看轮到的学习的是UITableView. BIDAppDelegate.h #import <UIKit/UIKit.h> ...
- c#录音和放音,超简单!不用DirectX
最近在做android与C#录音并互相通信的小东西.但是卡在C#录音这儿了.找了好久,说的都是DirectX,可是我总是安装不上,这才找到了这个简单的录音方法.当然,如果你想要录得好并且处理音频,那还 ...
- 使用Logstash创建ES映射模版并进行数据默认的动态映射规则
本文配置为 ELK 即(Elasticsearch.Logstash.Kibana)5.5.1. Elasticsearch 能够自动检测字段的类型并进行映射,例如引号内的字段映射为 String,不 ...
- Chocolatey 简介(软件自动化管理工具)
一.Chocolatey 管理Windows软件的明智方法 1.建立在技术的无人值守安装和PowerShell.建立在技术的无人值守安装和PowerShell. 2.轻松管理Windows软件的所有方 ...
- Anaconda需要添加的环境变量
F:\Anaconda3 F:\Anaconda3\Scripts F:\Anaconda3\Library\bin
- Unicode和UTF-8之间的关系
作者: 阮一峰 日期: 2007年10月28日 今天中午,我突然想搞清楚Unicode和UTF-8之间的关系,于是就开始在网上查资料. 结果,这个问题比我想象的复杂,从午饭后一直看到晚上9点,才算初步 ...
- MD5加密算法中的加盐值 ,和彩虹表攻击 防止彩虹表撞库
一.什么是彩虹表? 彩虹表(Rainbow Tables)就是一个庞大的.针对各种可能的字母组合预先计算好的哈希值的集合,不一定是针对MD5算法的,各种算法的都有,有了它可以快速的破解各类密码.越是复 ...
- 给Spring的placeholder设置默认值
问题:使用Spring时,可以方便地通过placeholder的形式${key}将key对应的properities定义value,注入到Bean中.但是如果在properities文件中,没有对ke ...
- frp官方中文文档
frp 是一个可用于内网穿透的高性能的反向代理应用,支持 tcp, udp, http, https 协议. 目录 frp 的作用 开发状态 架构 使用示例 通过 ssh 访问公司内网机器 通过自定义 ...