高性能MySQL count(1)与count(*)的差别
-------------------------------------------------------------------------------------------------第一篇-------------------------------------------------------------------------------------------------------------------
sql调优,主要是考虑降低:consistent gets和physical reads的数量。
count(1)与count(*)比较:
如果你的数据表没有主键,那么count(1)比count(*)快
如果有主键的话,那主键(联合主键)作为count的条件也比count(*)要快
如果你的表只有一个字段的话那count(*)就是最快的啦
count(*) count(1) 两者比较。主要还是要count(1)所相对应的数据字段。
如果count(1)是聚索引,id,那肯定是count(1)快。但是差的很小的。
因为count(*),自动会优化指定到那一个字段。所以没必要去count(?),用count(*),sql会帮你完成优化的
count详解:
count(1)跟count(主键)一样,只扫描主键。
count(*)跟count(非主键):
count(*)将返回表格中所有存在的行的总数包括值为null的行,然而count(列名)将返回表格中除去null以外的所有行的总数(有默认值的列也会被计入).
distinct 列名,得到的结果将是除去值为null和重复数据后的结果
count(主键) 不一定比count(其余索引) 快:
索引是一种B+树的结构,以块为单位进行存储。假设块大小是1K,主键索引大小为4B,有一个字段A的索引大小为2B。
同样一个块,能存放256个主键索引,但是能存放512个字段A的索引。
假设总数据是2K条,意味着主键索引占用了8个块,而A字段索引占用了4个块,统计时用主键索引需要经历的块多,IO次数多。效率也比A字段索引慢。
总结
1.如果在开发中确实需要用到count()聚合,那么优先考虑count(*),因为mysql数据库本身对于count(*)做了特别的优化处理。
有主键或联合主键的情况下,count(*)略比count(1)快一些。
没有主键的情况下count(1)比count(*)快一些。
如果表只有一个字段,则count(*)是最快的。
2.使用count()聚合函数后,最好不要跟where age = 1;这样的条件,会导致不走索引,降低查询效率。除非该字段已经建立了索引。使用count()聚合函数后,若有where条件,且where条件的字段未建立索引,则查询不会走索引,直接扫描了全表。
3.count(字段),非主键字段,这样的使用方式最好不要出现。因为它不会走索引.
--------------------------------------------------------------------------------第二篇----------------------------------------------------------------------------------------------------------------
首先,以我们最常见的两种数据库表引擎MyISAM和Innodb来讲。
MyISAM
MyISAM在统计表的总行数的时候会很快,但是有个大前提,不能加有任何WHERE条件。这是因为:MyISAM对于表的行数做了优化,具体做法是有一个变量存储了表的行数,如果查询条件没有WHERE条件则是查询表中一共有多少条数据,MyISAM可以做到迅速返回,所以也解释了如果加WHERE条件,则该优化就不起作用了。细心的同学会发现,innodb的表也有这么一个存储了表行数的变量,但是很遗憾这个值是一个估计值,没有什么实际意义。
Innodb
在该引擎下,COUNT(1)和COUNT(*)哪个快呢?结论是:这俩在高版本的MySQL(5.5及以后,5.1的没有考证)是没有什么区别的,也就没有COUN(1)会比COUNT(*)更快这一说了。
WHY?这就要从COUNT()函数的具体含义说起了。”
COUNT()有两个非常不同的作用:它可以统计某个列值的数量,也可以统计行数。在统计列值时要求列值是非空的(不统计NULL)。如果在COUNT()的括号中定了列或者列表达式,则统计的就是这个表达式有值的结果数。......COUNT()的另一个作用是统计结果集的行数。当MySQL确认括号内的表达式值不可能为空时,实际上就是在统计行数。最简单的就是当我们使用COUNT(*)的时候,这种情况下通配符*并不像我们猜想的那样扩展成所有的列,实际上,他会忽略所有列而直接统计所有的行数“——《高性能MySQL》。
通常,我们将第一个字段(一般是ID)作为主键,那么这个时候COUNT(1)实际统计的就是行数(此处表达有误,详见文章结尾),因为主键肯定是非NULL的。问题是Innodb是通过主键索引来统计行数的吗?结论是:如果该表只有一个主键索引,没有任何二级索引的情况下,那么COUNT(*)和COUNT(1)都是通过通过主键索引来统计行数的。如果该表有二级索引,则COUNT(1)和COUNT(*)都会通过占用空间最小的字段的二级索引进行统计,也就是说虽然COUNT(1)指定了第一列(此处表达有误,详见文章结尾)但是innodb不会真的去统计主键索引(一般为第一个字段的索引)。
实验
第一步
新建一张基于Innodb的表,只有一个ID主键,并插入5w的测试数据,建表语句如下:
CREATE TABLE `tb_news` (
`id` bigint(21) NOT NULL AUTO_INCREMENT,
`title` varchar(50) NOT NULL,
`content` mediumtext NOT NULL,
`count_ass` char(1) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=50001 DEFAULT CHARSET=utf8
这个时候执行COUNT(1)和COUNT(*)可以看到解释器的结果如下(两者一致,所以就只截了一张图),可以看到,两者都用了主键索引进行行数的统计:
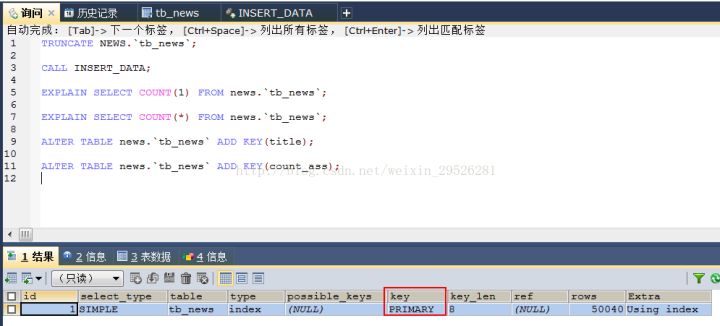
第二步
新建一个二级索引title,之后在分别看一下COUNT(1)和COUNT(*)的解释器结果(两者依然完全一致),这时已经用二级索引进行统计而非主键索引:
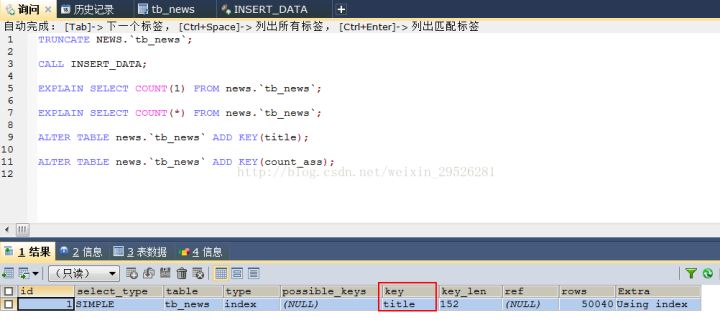
第三步
在我们之前特地预留的一个小字段count_ass字段建一个索引,到这一步目前表中有三个索引:一个主键索引,两个二级索引。
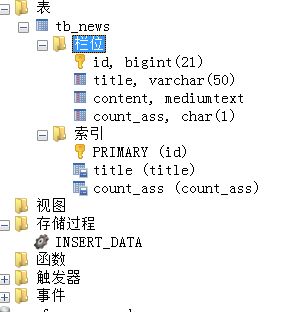
这时候我们再看一下COUNT(1)和COUNT(*)会通过哪个索引来统计行数(两者还是一致)。

原理
目前基于磁盘的数据库或者搜索引擎(比如Lucene)的性能瓶颈主要都是在IO阶段,相比于CPU和RAM,IO操作实在太慢了,所以这类系统的优化方向也都都是类似的——尽一切可能减少IO的次数(所以很多用ES的程序在性能优化到极限的时候选择直接上SSD)。这里统计行数的操作,查询优化器的优化方向就是选择能够让IO次数最少的索引,也就是基于占用空间最小的字段所建的索引(每次IO读取的数据量是固定的,索引占用的空间越小所需的IO次数也就越少)。而Innodb的主键索引是聚簇索引(包含了KEY,除了KEY之外的其他字段值,事务ID和MVCC回滚指针)所以主键索引一定会比二级索引(包含KEY和对应的主键ID)大,也就是说在有二级索引的情况下,一般COUNT()都不会通过主键索引来统计行数,在有多个二级索引的情况下选择占用空间最小的。
如果说有张Innodb的表只有主键索引,而且记录还比较大(比如30K),则统计行的操作会非常慢,因为IO次数会很多(这里就不做实验截图了,有兴趣可以自己试一下)。
一个优化方案就是预先建一个小字段并建二级索引专门用来统计行数,极端情况下这种优化速度提高上千倍也是正常的。
结论
结论就是对于COUNT(1)和COUNT(*)执行优化器的优化是完全一样的,并没有COUNT(1)会比COUNT(*)快这个说法
高性能MySQL count(1)与count(*)的差别的更多相关文章
- php学习之道:mysql SELECT FOUND_ROWS()与COUNT(*)使用方法差别
在mysql中 FOUND_ROWS()与COUNT(*)都能够统计记录.假设都一样为什么会有两个这种函数呢.以下我来介绍SELECT FOUND_ROWS()与COUNT(*)使用方法差别 SELE ...
- mysql中的count(primary_key)、count(1)、count(*)的区别
表结构如下: mysql> show create table user\G; *************************** 1. row ********************** ...
- MySQL学习笔记:count(1)、count(*)、count(字段)的区别
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT. 但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐.不信的话请 ...
- MYSQL的SQL_CALC_FOUND_ROWS 和count(*)
mysql的SQL_CALC_FOUND_ROWS 和 count(*) 在很多分页的程序中都这样写: SELECT COUNT(*) from `table` WHERE ......; 查出符合 ...
- mysql 5.7中 count(0) count(*) count(主键) count(非空字段)效率比较
mysql count(0) count(*) count(主键) count(非空字段) 效率比较 写代码的时候经理在背后说了一句count(0)的效率高于count(*) ,索性全部测试了一下 结 ...
- mysql技巧之select count的比较
在工作过程中,时不时会有开发咨询几种select count()的区别,我总会告诉他们使用select count(*) 就好.下文我会展示几种sql的执行计划来说明为啥是这样. 1.测试 ...
- MySQL · 引擎特性 · InnoDB COUNT(*) 优化(?)
http://mysql.taobao.org/monthly/2016/06/10/ 在5.7版本中,InnoDB实现了新的handler的records接口函数,当你需要表上的精确记录个数时,会直 ...
- mysql SELECT FOUND_ROWS()与COUNT(*)用法区别
在mysql中 FOUND_ROWS()与COUNT(*)都可以统计记录,如果都一样为什么会有两个这样的函数呢,下面我来介绍SELECT FOUND_ROWS()与COUNT(*)用法区别 SEL ...
- mysql合并 两个count语句一次性输出结果的方法
mysql合并 两个count语句一次性输出结果的方法 需求场景:经常要查看有两个表统计数,用SELECT COUNT(*) FROM hotcontents,SELECT COUNT(*) FROM ...
随机推荐
- Intellj IDEA 快捷键冲突
Intellij IDEA快捷键冲突 [问题描述]: ctr + alt + 方向键 与系统的快捷键冲突,按快捷键,屏幕方向发生改变. [解决办法]: ctr + alt + F12 调用出Intel ...
- python第二次作业-titanic数据库练习
一.读入titanic.xlsx文件,按照教材示例步骤,完成数据清洗. titanic数据集包含11个特征,分别是: Survived:0代表死亡,1代表存活Pclass:乘客所持票类,有三种值(1, ...
- shell基础概念, if+命令, shell中引用python, shell脚本的几种执行方式
说明: 虚拟机中shell_test目录用来练习shell, 其中有个test.log文件用来存放日志 #!/usr/bin/bash # shell文件开头, 用来指定该文件使用哪个解释器 ...
- 用vbs和ADSI管理Windows账户
ADSI (Active Directory Services Interface)是Microsoft新推出的一项技术,它统一了许多底层服务的编程接口,程序员可以使用一致的对象技术来访问这些底层服务 ...
- [Pytorch Bug] "EOFError: Ran out of input" When using Dataloader with num_workers=x
在Windows上使用Dataloader并设置num_workers为一个非零数字,enumerate取数据时会引发"EOFError: Ran out of input"的报错 ...
- 【STM32H7教程】第20章 STM32H7的GPIO应用之无源蜂鸣器
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第20章 STM32H7的GPIO应用之无源蜂鸣器 ...
- Windows 10 powershell 中文乱码解决方案
Windows 10 powershell 中文乱码解决方案 Intro 我装的系统是英文版的 win 10 操作系统,最近使用命令行测试接口,发现中文显示一直异常, 使用网上的各种解决方案都没有效果 ...
- 从新手小白到老手大白的成长之路第二弹-WPF之UI界面之Grid面板
废话不多说,接下来直接开始介绍WPF-UI界面-Grid面板 如图就是创建好了的一个WPF项目,整个界面被一个Window窗体包含起来,上面类似于什么什么网址什么的其实就相当于.net的命名空间,缺什 ...
- WPF/.net core WPF 系统托盘支持
WPF 原生不支持系统托盘图标,需要依靠其它方式处理. 1 使用 WinForm 的支持 WPF最小到系统托盘 - Arvin.Mei - 博客园 2 使用 wpf-notifyicon 库 hard ...
- python连接sqlserver工具类
上代码: # -*- coding:utf-8 -*- import pymssql import pandas as pd class MSSQL(object): def __init__(sel ...