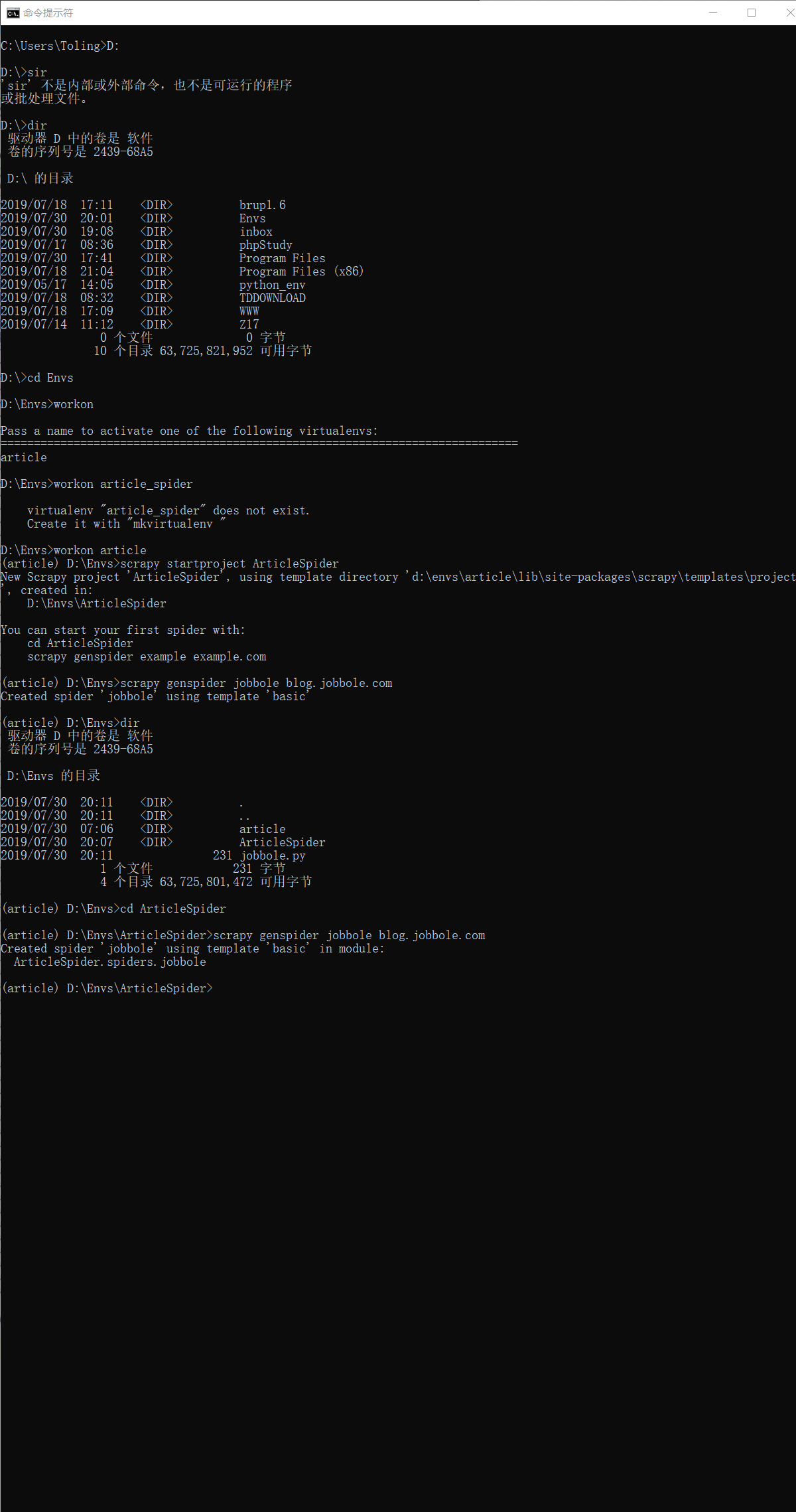
爬虫环境搭建及 scrapy 启动
创建虚拟环境
C:\Users\Toling>mkvirtualenv article
这个是普通的创建虚拟环境,但是实际开发中可能会使用python2或python3所以我们需要指定开发的环境
Microsoft Windows [版本 10.0.17134.885]
(c) Microsoft Corporation。保留所有权利。 C:\Users\Toling>mkvirtualenv --python3=C:\Users\Toling\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Python 3.7\python.exe article 格式:mkvirtualenv --python=py路径\python.exe 环境名称
安装scrapy架构
常规安装: pip install scrapy
更换豆瓣源:pip install -i https://pypi.douban.com/simple/ scrapy
注意掉坑,如果出现报错:
以下是我个人在安装scrapy时遇见的问题及我的解决方法
(1)运行命令
pip install Scrapy
在执行到“Collecting Twisted>=13.1.0 (from Scrapy)”时报错:Exception:Traceback (most recent call last).....
原因:我当前的版本是pip 9.0.1,需要升级到9.0.3
运行命令:
python -m pip install --upgrade pip
(2)升级后再次执行
pip install Scrapy
报错:Command "python setup.py egg_info" failed with error code 1 in C:\Users\LUOXIA~1\AppData\Local\Temp\pip-build-5hi6welx\Twisted\Complete output from command python setup.py egg_info:
原因:setup.py的版本问题
运行命令:
pip install setuptools==33.1.1
(3)再次执行
pip install Scrapy
报错“Command ""c:\program files\python36\python.exe" -u -c "import setuptools, tokenize;__file__='C:\\Users\\LUOXIA~1\\AppData\\Local\\Temp\\pip-build-rdyp2fl9\\Twisted\\setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record C:\Users\LUOXIA~1\AppData\Local\Temp\pip-pge7_20d-record\install-record.txt --single-version-externally-managed --compile" failed with error code 1 in C:\Users\LUOXIA~1\AppData\Local\Temp\pip-build-rdyp2fl9\Twisted\”
解决方法:下载安装twisted对应版本的whl文件,比如:我的是Twisted-17.9.0-cp36-cp36m-win_amd64.whl,cp后面是python版本,amd64代表64位
下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
运行命令:
pip install F:\python\mytool\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
其中install 后面为下载的whl文件的完整路径名 技巧:可以打开文件所在目录然后点击导航栏,复制地址。然后重命名文件就可以复制文件名(记得打开拓展名)。
(4)安装完成后,再次运行:
pip install Scrapy
报错:Collecting pyasn1 (from service-identity->Scrapy)
Could not find a version that satisfies the requirement pyasn1 (from service-identity->Scrapy) (from versions: )
No matching distribution found for pyasn1 (from service-identity->Scrapy)
原因:缺少pyasn1
运行命令:
pip install pyasn1
pycharm中导入scrapy
操作过程:
爬虫环境搭建及 scrapy 启动的更多相关文章
- selenium+python爬虫环境搭建
前言: 准备使用selenium爬取网站数据,先搭建selenium+python爬虫环境搭建 系统环境: 64位win10系统,同时装python2.7和python3.6两个版本,IDE为pych ...
- Android 环境搭建资料及启动过程中问题汇总
一.环境搭建资料 推荐谷歌自己开发的Android Studio 工具可以从这个网址下载:http://tools.android-studio.org/,直接下载推荐的就行 二.安装 安装时最好指定 ...
- UVE开发环境搭建及项目启动
1.IDE安装visual studio code ,略: 2.node安装(node-v10.5.0-win-x64.zip),解压即可: 3.配置node环境变量,cmd 输入node -v.np ...
- 学习elasticsearch(一)linux环境搭建(2)——启动elasticsearch
在启动访问es的过程中遇到了各种的奇葩问题. 1.网上各种版本的启动方式让人眼花缭乱不知如何启动.简单粗暴——到es的bin目录下直接 执行 ./elasticsearch //显示启动,ctrl+c ...
- RPI学习--环境搭建_默认启动桌面/终端修改
参见:http://elinux.org/RPi_raspi-config 首次运行Raspbian会自动进入设置,往后也可以重新进入设置: $ sudo raspi-config 选项3 Enabl ...
- python3爬虫环境搭建
安装python3 sudo apt-get install python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev ...
- Ningx集群环境搭建
Ningx集群环境搭建 Nginx是什么? Nginx ("engine x") 是⼀个⾼性能的 HTTP 和 反向代理 服务器,也是⼀个 IMAP/ POP3/SMTP 代理服务 ...
- Centos7搭建Scrapy爬虫环境
写在前面 因为之前的爬虫环境一直是部署在我自己本地的电脑上的,最近,写了一个监控别人空间的爬虫,需要一直线上24小时运行,所有就打算云服务器上部署环境,也捣鼓了好一会才弄好,还是有一些坑,这里先记录一 ...
- linux下scrapy环境搭建
最近使用scrapy做数据挖掘,使用scrapy定时抓取数据并存入MongoDB,本文记录环境搭建过程以作备忘 OS:ubuntu 14.04 python:2.7.6 scrapy:1.0.5 D ...
随机推荐
- chrome如何查看cookie
以mac为例: 第一步:点击chrome的偏好设置 第二步:点击如下图所示的最下面的高级 第三步:点击内容设置,如下所示 第四步:点击cookie,就会出现查看所有cookie和网站数据
- iOS开发如何避免安全隐患
现在很多iOS的APP没有做任何的安全防范措施,导致存在很多安全隐患和事故,今天我们来聊聊iOS开发人员平时怎么做才更安全. 一.网络方面 用抓包工具可以抓取手机通信接口的数据.以Charles为例, ...
- Mybatisの常见面试题
Mybatis -面试问题 最近准备系统的学一下Mybatis,之前只有粗略的看了下,选了十个常见的面试题 1. #{}和${}的区别是什么? #{}是预编译处理,${}是字符串替换. Mybatis ...
- mac vim 配色
syntax on set nu set noic set t_Co=256 set tabstop=4 set nocompatible set shiftwidth=4 set softtabst ...
- Jsoup配合 htmlunit 爬取异步加载的网页
加入 jsoup 和 htmlunit 的依赖 <dependency> <groupId>org.jsoup</groupId> <artifactId&g ...
- CentOS 操作防火墙
1:查看防火状态 systemctl status firewalld 2:暂时关闭防火墙 systemctl stop firewalld 3:永久关闭防火墙 systemctl disable f ...
- java unicode补充字符带来的码点和代码单元问题
码点与代码单元 java string有两种判定字符的方式,一种是以码点,一种以代码单元,简单讲,码点就是真正的字符,代码单元是按大小即char型长度2个字节划分字符串. 所以length和chara ...
- shell_chmod与目录权限
此篇文档将讲解关于linux中文件权限常用命令chmod.为了达到一个比较好的效果,我会在需要的地方实际上机验证测试,并截图给朋友们看.我的linux机器装的是(opensuse-11.3),并且以文 ...
- 硬件笔记之Thinkpad T470P更换2K屏幕
0x00 前言 手上的Thinkpad T470P屏幕是1920x1080的屏幕,色域范围NTSC 45%,作为一块办公用屏是正常配置,但是考虑到色彩显示和色域范围,计划升级到2K屏幕. 2k屏幕参数 ...
- Stixel_World(single)学习笔记
1. 算法背景 Q: 如何有效处理数以百万的视差图数据(提供了每个像素的精确深度信息)? 以及如何在大量数据中找到所有相关的障碍物? 提出方法 “ stixel_world ”, It takes ...