centos7搭建hadoop3.*.*系列
最近搭建这个hadoop踩过不少坑,先是配置JDK搞错路径(普通用户和root用户下的路径不同),再就是hadoop版本不同导致的启动错误,网上找到的是hadoop2.*.*的版本,但是我安装的hadoop3.*.*的版本,环境配置有部分不同。希望大家不要重蹈覆辙!
下载hadoop安装包
安装配置
1.配置主机名:
将文件中原有的主机名删除,添加你自己的主机名,保存并退出。
vi /etc/hostname
2.配置hosts文件:
在文件最后增加机器的IP地址和刚才配好的主机名,保存并退出。
vi /etc/hosts
3.生成SSH密钥:执行以下命令,然后一直回车。来生成SSH密钥。生成的密钥文件会存放在/root/.ssh/目录下。前提是你用的root帐号登录并且生成的ssh密钥。
ssh-keygen
4.配置机器免密登录:执行以下命令、将刚才生成好的SSH密钥发送指定的机器上,来实现机器免密登录。
ssh-copy-id root@主机名
5.上传和解压下载好的Hadoop安装包,上传可以直接从xshell拖进目录
tar -zxvf hadoop-3.1.2.tar.gz(我这里写的是我的包名)
6.配置hadoop-env.sh文件:这个文件里写的是hadoop的环境变量,主要修改hadoop的JAVA_HOME、HADOOP_HOME和HADOOP_CONF_DIR 路径,修改完成后保存退出。
cd hadoop-3.1.2/etc/hadoop/
vi hadoop-env.sh
7.修改core-site.xml文件:使用vi core-site.xml打开文件,增加以下配置参数。
<configuration>
<!--用来指定 hdfs 的老大,namenode 的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://主机名:9870</value>
</property>
<!--用来指定 hadoop 运行时产生临时文件的存放目录,如果不配置默认使用/tmp目录存在安全隐患 -->
<property>
<name>hadoop.tmp.dir</name>
<value>hadoop的路径/tmp</value>
</property>
</configuration>
8.修改hdfs-site.xml:使用vi hdfs-site.xml打开文件,增加以下配置参数。
<!--指定 hdfs 保存数据副本的数量,包括自己,默认值是 -->
<!--如果是伪分布模式,此值是 -->
<property>
<name>dfs.replication</name>
<value></value>
</property>
<!--设置 hdfs 的操作权限,false 表示任何用户都可以在 hdfs 上操作文件-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property> <property>
<name>dfs.http.address</name>
<value>0.0.0.0:</value>
</property>
9.修改mapred-site.xml:使用vi mapred-site.xml,增加以下配置参数。(hadoop3.*里面直接修改这个文件,在hadoop2.*里mapred-site.xml这个文件初始时是没有的,有的是模板文件,mapred-site.xml.template,所以需要拷贝一份,并重命名为 mapred-site.xml )
<property>
<!--指定 mapreduce 运行在 yarn 上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
10.修改 yarn-site.xml:使用vi yarn-site.xml打开文件,增加以下配置参数。
<property>
<!--指定 yarn 的老大 resoucemanager 的地址-->
<name>yarn.resourcemanager.hostname</name>
<value>主机名</value>
</property>
<property>
<!--NodeManager 获取数据的方式-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
11.配置 slaves 文件:使用vi slaves打开文件,增加以下配置参数。
hostname #写主机名
12.配置Hadoop的环境变量:使用vi /etc/profile打开文件,增加以下配置参数。保存退出后,使用source /etc/profile命令来使配置立即生效。
#配置hadoop的环境变量
export HADOOP_HOME=hadoop的路径
export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
13.格式化namenode:使用以下命令进行格式化hadoop的namenode。出现successfully代表成功。
hadoop namenode -format
14.hadoop3.*版本的话,此时启动还会报错
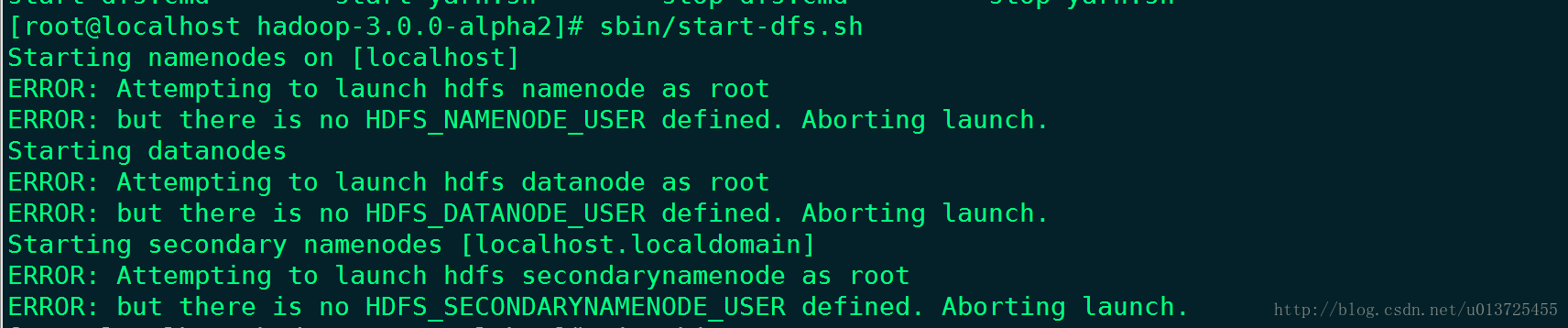
是因为缺少用户定义造成的,所以在hadoop目录下分别编辑开始和关闭脚本
vim sbin/start-dfs.sh
vim sbin/stop-dfs.sh
在靠上面的空白处添加内容:
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=hdfs
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
vim sbin/start-yarn.sh
vim sbin/stop-yarn.sh
在靠上面的空白处添加内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
15.启动hadoop:使用start-all.sh命令启动hadoop。启动完成后,通过jps命令查看进程节点。如果出现六个节点和地址说明成功启动。
centos7搭建hadoop3.*.*系列的更多相关文章
- CentOS7搭建Hadoop-3.3.0集群手记
前提 这篇文章是基于Linux系统CentOS7搭建Hadoop-3.3.0分布式集群的详细手记. 基本概念 Hadoop中的HDFS和YARN都是主从架构,主从架构会有一主多从和多主多从两种架构,这 ...
- Centos7 搭建 hadoop3.1.1 集群教程
配置环境要求: Centos7 jdk 8 Vmware 14 pro hadoop 3.1.1 Hadoop下载 安装4台虚拟机,如图所示 克隆之后需要更改网卡选项,ip,mac地址,uuid 重启 ...
- centos7 搭建GlusterFS
centos7 搭建GlusterFS 转载http://zhaijunming5.blog.51cto.com/10668883/1704535 实验需求:4台机器安装GlusterFS组成一个集群 ...
- Centos7搭建FTP服务器
从网上搜索了好多搭建Centos7搭建服务器的教程都没有成功唯独这个,利用Windows资源管理器连接测试成功. 一.通过yum安装vsftpd yum install -y vsftpd 二.修改v ...
- CentOS7 搭建 SVN 服务器
CentOS7 搭建 SVN 服务器 介绍SVN: SVN是Subversion的简称,是一个开放源代码的版本控制系统,相较于RCS.CVS,它采用了分支管理系统,它的设计目标就是取代CVS.互联网上 ...
- centos7搭建ELK Cluster集群日志分析平台(四):Fliebeat-简单测试
续之前安装好的ELK集群 各主机:es-1 ~ es-3 :192.168.1.21/22/23 logstash: 192.168.1.24 kibana: 192.168.1.25 测试机:cli ...
- centos7搭建ELK Cluster集群日志分析平台(三):Kibana
续 centos7搭建ELK Cluster集群日志分析平台(一) 续 centos7搭建ELK Cluster集群日志分析平台(二) 已经安装好elasticsearch 5.4集群和logst ...
- centos7搭建ELK Cluster集群日志分析平台(二):Logstash
续 centos7搭建ELK Cluster集群日志分析平台(一) 已经安装完Elasticsearch 5.4 集群. 安装Logstash步骤 . 安装Java 8 官方说明:需要安装Java ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
随机推荐
- SQL server 2014使用导出数据为Excel
1.打开SQL server 2014,连接至数据库引擎 2.在要导出的数据库上右击,选择"任务->导出数据" 3.数据源选择"SQL Server Native ...
- Linux C 网络编程——多线程的聊天室实现(服务器端)
服务器端的主要功能: 实现多用户群体聊天功能(此程序最多设定为10人,可进行更改),每个人所发送的消息其他用户均可以收到.用户可以随意的加入或退出(推出以字符串"bye"实现),服 ...
- some (1)
每次在写博客的时候,都是自己觉得在工作中非常重要的东西,写东西的时候,也是一个思考的过程.好的东西不光帮助别人,也使自己有进一步的理解.
- 洛谷 P3811 题解
题面 利用暴力快速幂O(nlogn)会TLE掉: 所以对于求1~n的所有逆元要用递推公式: #include <bits/stdc++.h> using namespace std; ]; ...
- ubuntu搭建环境
1.终端输入 sudo apt- add-apt-repository ppa:ondrej/php sudo add-apt-repository ppa:ondrej/php sudo apt ...
- 深入理解Apache Kafka
一.介绍 Kafka在世界享有盛名,大部分互联网公司都在使用它,那么它到底是什么呢? Kafka由LinkedIn公司于2011年推出,自那时起功能逐步迭代,目前演变成一个完整的平台级产品,它允许您冗 ...
- Kafka学习(四)-------- Kafka核心之Producer
通过https://www.cnblogs.com/tree1123/p/11243668.html 已经对consumer有了一定的了解.producer比consumer要简单一些. 一.旧版本p ...
- Python学习系列(三)Python 入门语法规则1
一.注释 ''' 多行注释 ''' #单行注释 ''' #example1.1 测试程序 时间:4/17/2017 i1=input("请输入用户名:") i2=input ...
- 解决 Android 中出现依赖多个版本支持库的问题
在 app 的 build.gradle 中引入依赖时发现如下错误: All com.android.support libraries must use the exact same version ...
- mui的app页面使用layui填充数据
在mui的开发中有个坑,mui.plusReady在web上使用时是不会起作用的,只能在app上才行,所以推荐自己测试时使用mui.ready去写加载时的方法. 前端请求的返回格式为json,所以在后 ...