Python爬虫(一):爬虫伪装
1 简介
对于一些有一定规模或盈利性质比较强的网站,几乎都会做一些防爬措施,防爬措施一般来说有两种:一种是做身份验证,直接把虫子挡在了门口,另一种是在网站设置各种反爬机制,让虫子知难而返。
2 伪装策略
我们知道即使是一些规模很小的网站通常也会对来访者的身份做一下检查,如验证请求 Headers,而对于那些上了一定规模的网站就更不用说了。因此,为了让我们的爬虫能够成功爬取所需数据信息,我们需要让爬虫进行伪装,简单来说就是让爬虫的行为变得像普通用户访问一样。
2.1 Request Headers问题
为了演示我使用百度搜索 163邮箱

使用 F12 工具看一下请求信息
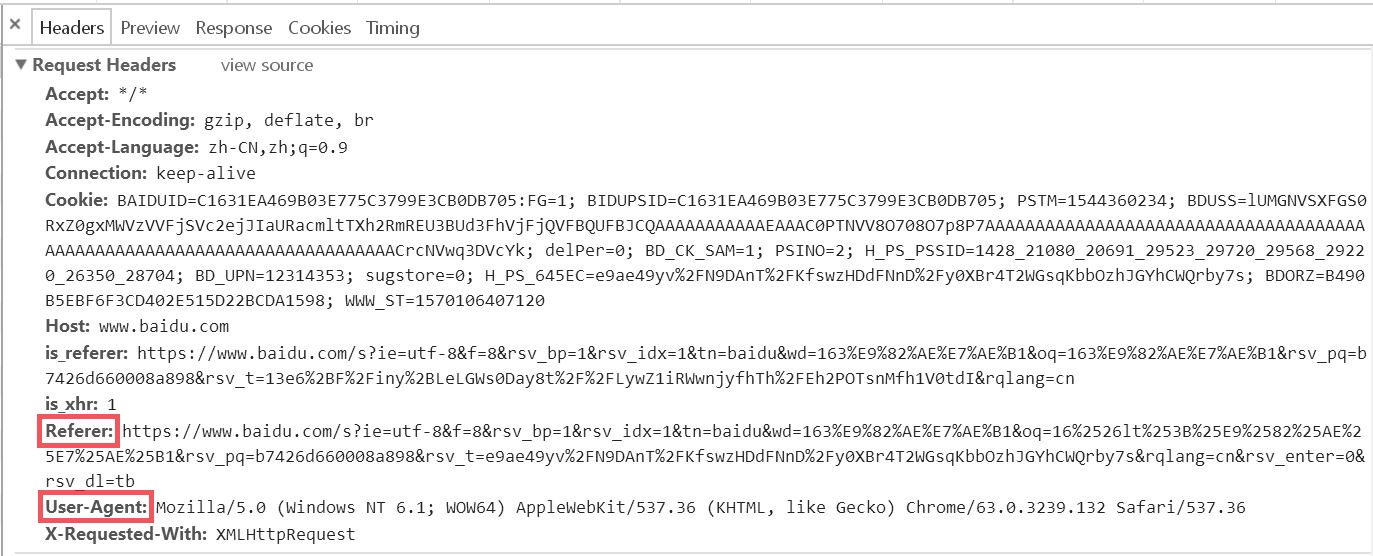
在上图中,我们可以看到 Request Headers 中包含 Referer 和 User-Agent 两个属性信息,Referer 的作用是告诉服务器该网页是从哪个页面链接过来的,User-Agent 中文是用户代理,它是一个特殊字符串头,作用是让服务器能够识别用户使用的操作系统、CPU 类型、浏览器等信息。通常的处理策略是:1)对于要检查 Referer 的网站就加上;2)对于每个 request 都添加 User-Agent。
2.2 IP限制问题
有时我们可能会对一些网站进行长期或大规模的爬取,而我们在爬取时基本不会变换 IP,有的网站可能会监控一个 IP 的访问频率和次数,一但超过这个阈值,就可能认作是爬虫,从而对其进行了屏蔽,对于这种情况,我们要采取间歇性访问的策略。
通常我们爬取是不会变换 IP 的,但有时可能会有一些特殊情况,要长时间不间断对某网站进行爬取,这时我们就可能需要采用 IP 代理的方式,但这种方式一般会增加我们开销,也就是可能要多花钱。
3 总结
有些时候我们进行爬取时 Request Headers 什么的已经做好了伪装,却并未得到如愿以偿的结果,可能会出现如下几种情况:得到的信息不完整、得到不相关的信息、得不到信息,这种情况我们就需要研究网站的防爬机制,对其进行详细分析了。常见的几种我列一下:
1)不规则信息:网址上会有一些没有规则的一长串信息,这种情况通常采用 selenium(模拟浏览器,效率会低一些) 解决;
2)动态校验码:比如根据时间及一些其他自定义规则生成,这种情况我们就需要找到其规则进行破解了;
3)动态交互:需要与页面进行交互才能通过验证,可以采用 selenium 解决;
4)分批次异步加载:这种情况获取的信息可能不完整,可以采用 selenium 解决。
Python爬虫(一):爬虫伪装的更多相关文章
- Python做简单爬虫(urllib.request怎么抓取https以及伪装浏览器访问的方法)
一:抓取简单的页面: 用Python来做爬虫抓取网站这个功能很强大,今天试着抓取了一下百度的首页,很成功,来看一下步骤吧 首先需要准备工具: 1.python:自己比较喜欢用新的东西,所以用的是Pyt ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python学习网络爬虫--转
原文地址:https://github.com/lining0806/PythonSpiderNotes Python学习网络爬虫主要分3个大的版块:抓取,分析,存储 另外,比较常用的爬虫框架Scra ...
- Python基础及爬虫入门
**写在前面**我们在学习任何一门技术的时候,往往都会看很多技术博客,很多程序员也会写自己的技术博客.但是我想写的这些不是纯技术博客,我暂时也没有这个能力写出 Python 或者爬虫相关的技术博客来. ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
随机推荐
- 用故事解析setTimeout和setInterval(内含js单线程和任务队列)
区别: setTimeout(fn,t): 延迟调用,超过了时间就调用回调函数,返回一个id,使用clearTimeout(id)取消执行. 注意:取消了里面的回调函数就不执行了哦,而不是取消的时候就 ...
- JVM中class文件探索与解析
一直想成为一名优秀的架构师的我,转眼已经工作快两年了,对于java内核了解甚少,闲来时间,看看JVM,吧自己的一些研究写下来供大家参考,有不对的地方请指正. 废话不多说,一起来看看JVM中类文件是如何 ...
- [python]代码中包含中文,提示:SyntaxError: Non-ASCII character '\xcd'
解决方法: 把文件编码方式改为gbk即可.在代码开头写上: # coding=gbk
- HDU dp递推 母牛的故事 *
母牛的故事 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...
- 环境变量_JAVA_LAUNCHER_DEBUG,它能给你更多的JVM信息
关于环境: 本文中的实战都是在docker容器中进行的,容器的出处请参照<在docker上编译openjdk8>一文,里面详细的说明了如何构造镜像和启动容器. 在上一篇文章<修改,编 ...
- Mysql高手系列 - 第7篇:玩转select条件查询,避免踩坑
这是Mysql系列第7篇. 环境:mysql5.7.25,cmd命令中进行演示. 电商中:我们想查看某个用户所有的订单,或者想查看某个用户在某个时间段内所有的订单,此时我们需要对订单表数据进行筛选,按 ...
- Java连载29-方法执行内存分析、方法重载
一.JVM包含三个内存区:栈内存.堆内存.方法区内存 二.注意点 (1)在MyEclipse中字体是红色的是一个类的名字,并且这个类除了我们自定义的类是JavaSE类库中自带的 (2)其实JavaSE ...
- 013 turtle程序语法元素分析
目录 一.概述 二.库引用与import 2.1 库引用 2.2 使用from和import保留字共同完成库引用 2.3 两种库引用方法比较 2.4 使用import和as保留字共同完成库引用 三.t ...
- 在Linux上安装nginx时遇到的问题,真的好坑啊!!!!
解决了两个小时愣是卡着没动,结果一请大神问题就迎刃而解,怪自己太粗心,一下午差点就被这个问题安排的明明白白,直接上问题: makeFile时的问题: checking for OS + Linux ...
- Could not delete D:/workspace/.metadata/.plugins/org.eclipse.wst.server.core/tmp1/wtpwebapps/platform/WEB-INF/lib
再把之前的maven工程删掉时,出现了如下错误: Could not delete D:/workspace/.metadata/.plugins/org.eclipse.wst.server.cor ...