用深度学习做命名实体识别(七)-CRF介绍
还记得之前介绍过的命名实体识别系列文章吗,可以从句子中提取出人名、地址、公司等实体字段,当时只是简单提到了BERT+CRF模型,BERT已经在上一篇文章中介绍过了,本文将对CRF做一个基本的介绍。本文尽可能不涉及复杂晦涩的数学公式,目的只是快速了解CRF的基本概念以及其在命名实体识别等自然语言处理领域的作用。
什么是CRF?
CRF,全称 Conditional Random Fields,中文名:条件随机场。是给定一组输入序列的条件下,另一组输出序列的条件概率分布模型。
什么时候可以用CRF?
当输出序列的每一个的状态,需要考虑到相邻token的状态的时候。举两个例子:
1、假设有一堆小明日常生活的照片,可能的状态有吃饭、洗澡、刷牙等,大部分情况,我们是能够识别出小明的状态的,但是如果你看到一张小明露出牙齿的照片,在没有相邻的小明的状态为条件的情况下,是很难判断他是在吃饭还是刷牙的。这时,就可以用crf。
2、假设有一句话,这里假设是英文,我们要判断每个词的词性,那么对于一些词来说,如果不知道相邻词的词性的情况下,是很难准确判断每个词的词性的。这时,也可以用crf。
什么是随机场?
我们先来说什么是随机场。
The collection of random variables is called a stochastic process.A stochastic process that is indexed by a spatial variable is called a random field.
随机变量的集合称为随机过程。由一个空间变量索引的随机过程,称为随机场。
也就是说,一组随机变量按照某种概率分布随机赋值到某个空间的一组位置上时,这些赋予了随机变量的位置就是一个随机场。比如上面的例子中,小明的一系列照片分别是什么状态组成了一组位置,我们从一组随机变量{吃饭、洗澡、刷牙}中取值,随机变量遵循某种概率分布,随机赋给一组照片的某一张的输出位置,并完成这组照片的所有输出位置的状态赋值后,这些状态和所在的位置全体称为随机场。
为什么叫条件随机场?
回答这个问题需要先来看看什么是马尔可夫随机场,如果一个位置的赋值只和与它相邻的位置的值有关,与和它不相邻的位置的值无关,那么这个随机场就是一个马尔可夫随机场。这个假设用在小明和词性标注的例子中都是合适的,因为我们通过前一张照片就可以判断当前露牙的照片是刷牙还是吃饭,根据前一个词的词性就可以判断当前词的词性是否符合语法。
马尔可夫模型是根据隐含变量(词性)生成可观测状态(词),而条件随机场是根据观测状态(词)判别隐含变量(词性)。或者说条件随机场是给定了观测状态(输入序列)集合这个先验条件的马尔科夫随机场。上面例子中的给定的小明照片,给定的英文句子,这些都是随机场的先验条件。
CRF的数学描述
设X与Y是随机变量,P(Y|X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔科夫随机场,则称条件概率分布P(Y|X)是条件随机场。在实际的应用中,比如上面的两个例子,我们一般都要求X和Y有相同的结构,如下:
X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn)
比如词性标注,我们要求输出的词性序列和输入的句子中的每个词是一一对应的。
X和Y有相同的结构的CRF就构成了线性链条件随机场(Linear chain Conditional Random Fields,简称 linear-CRF)。
上面的例子中没有提到命名实体识别,但其实命名实体识别的原理和上面的例子是一样的,也是用到了linear-CRF,后面会提到。
CRF如何提取特征?
CRF中有两类特征函数,分别是状态特征和转移特征,状态特征用当前节点(某个输出位置可能的状态中的某个状态称为一个节点)的状态分数表示,转移特征用上一个节点到当前节点的转移分数表示。其损失函数定义如下:
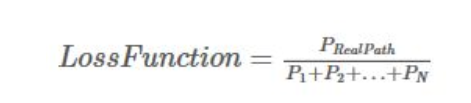
CRF损失函数的计算,需要用到真实路径分数(包括状态分数和转移分数),其他所有可能的路径的分数(包括状态分数和转移分数)。这里的路径用词性来举例就是一句话对应的词性序列,真实路径表示真实的词性序列,其他可能的路径表示其他的词性序列。
这里的分数就是指softmax之前的概率,或称为未规范化的概率。softmax的作用就是将一组数值转换成一组0-1之间的数值,这些数值的和为1,这样就可以表示概率了。
对于词性标注来说,给定一句话和其对应的词性序列,那么其似然性的计算公式(CRF的参数化公式)如下,图片出自条件随机场CRF:
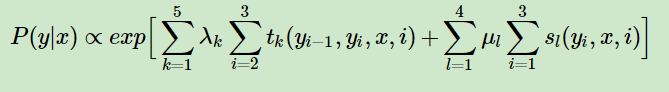
- l表示某个词上定义的状态特征的个数,k表示转移特征的个数,i表示词在句子中的位置。
- tk和sl分别是转移特征函数和状态特征函数。
- λk和μl分别是转移特征函数和状态特征函数的权重系数,通过最大似然估计可以得到。
- 上面提到的状态分数和转移分数都是非规范化的对数概率,所以概率计算都是加法,这里加上一个exp是为了将对数概率转为正常概率。实际计算时还会除以一个规范化因子Z(x),其实就是一个softmax过程。
在只有CRF的情况下,上面说的2类特征函数都是人工设定好的。通俗的说就是人工设定了观测序列的特征。
人为设定状态特征模板,比如设定“某个词是名词”等。
人为设定转移特征模板,比如设定“某个词是名词时,上一个词是形容词”等。
给定一句话的时候,就根据上面设定的特征模板来计算这句话的特征分数,计算的时候,如果这句话符合特征模板中的特征规则,则那个特征规则的值就为1,否则就为0。
实体识别的表现取决于2种特征模板设定的好坏。
所以如果我们能使用深度神经网络的方式,特征就可以由模型自己学习得到,这就是使用BERT+CRF的原因。
命名实体识别中的BERT和CRF是怎么配合的?
由BERT学习序列的状态特征,从而得到一个状态分数,该分数直接输入到CRF层,省去了人工设置状态特征模板。
这里的状态特征是说序列某个位置可能对应的状态(命名实体识别中是指实体标注),
状态分数是每个可能的状态的softmax前的概率(又称非规范化概率,或者直接称作分数),
实体标注通常用BIO标注,B表示词的开始,I表示词的延续,O表示非实体词,比如下面的句子和其对应的实体标注(假设我们要识别的是人名和地点):
小 明 爱 北 京 的 天 安 门 。
B-Person I-Person O B-Location I-Location O B-Location I-Location I-Location O
也就是说BERT层学到了句子中每个字符最可能对应的实体标注是什么,这个过程是考虑到了每个字符左边和右边的上下文信息的,但是输出的最大分数对应的实体标注依然可能有误,不会100%正确的,出现B后面直接跟着B,后者标注以I开头了,都是有可能的,而降低这些明显不符规则的问题的情况的发生概率,就可以进一步提高BERT模型预测的准确性。此时就有人想到用CRF来解决这个问题。
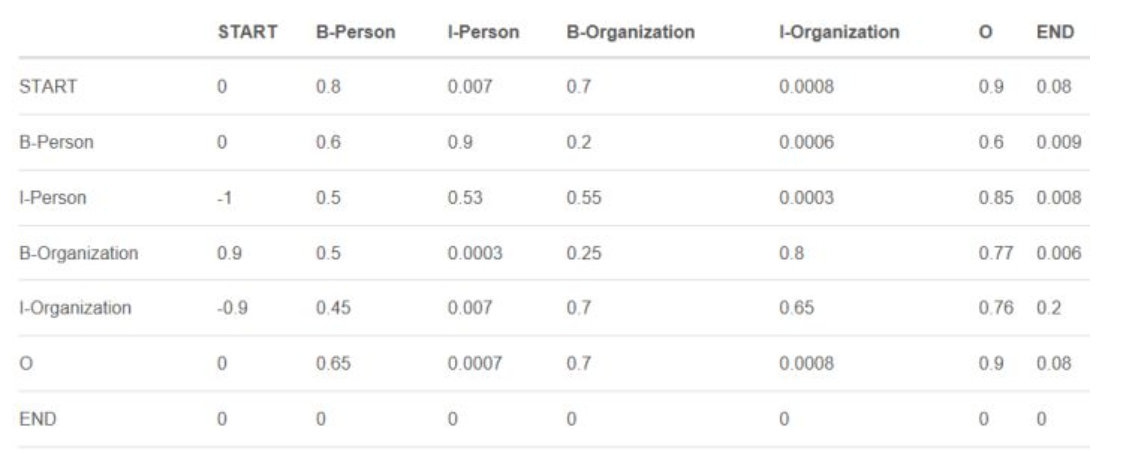
CRF算法中涉及到2种特征函数,一个是状态特征函数,计算状态分数,一个是转移特征函数,计算转移分数。前者只针对当前位置的字符可以被转换成哪些实体标注,后者关注的是当前位置和其相邻位置的字符可以有哪些实体标注的组合。BERT层已经将状态分数输出到CRF层了,所以CRF层还需要学习一个转移分数矩阵,该矩阵表示了所有标注状态之间的组合,比如我们这里有B-Person I-Person B-Location I-Location O 共5种状态,有时候还会在句子的开始和结束各加一个START 和 END标注,表示一个句子的开始和结束,那么此时就是7种状态了,那么2个状态(包括自己和自己)之间的组合就有7*7=49种,上面说的转移分数矩阵中的元素就是这49种组合的分数(或称作非规范化概率),表示了各个组合的可能性。这个矩阵一开始是随机初始化的,通过训练后慢慢会知道哪些组合更符合规则,哪些更不符合规则。从而为模型的预测带来类似如下的约束:
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
矩阵示意如下:
为什么不能通过人工来判断标注规则并编写好修正逻辑呢?
因为人工虽然能判断出预测的标注前后关系是否符合规则,但是无法知道如何对不符合规则的预测进行调整,比如我们知道句子的开头应该是“B-”或“O”,而不是“I-”,但是究竟是B-还是O呢?而且对于标注状态非常多的场景下,人工编写的工作量和逻辑是非常大且复杂的。
CRF损失函数的计算,需要用到真实路径分数(包括状态分数和转移分数),其他所有可能的路径的分数(包括状态分数和转移分数)。其中真实路径的状态分数是根据训练得到的BERT模型的输出计算出来的,转移分数是从CRF层提供的转移分数矩阵得到的。其他路径的状态分数和转移分数其实也是这样计算的。
最后我们来看下真实路径的计算原理,其实是使用了维特比算法。
维特比算法
概念:用相邻两个层的最优路径来组成最终从起始层到结束层的最优路径。最优路径是指从上一层的各个节点到达当前层的某个节点的所有路径中,概率最大 or 距离最短(或者其他理由,具体自行定义) 的路径。
核心理念:从上一层的各个节点到达当前层的某个节点的路径的概率最大,则该节点一定在最大路径上。因为后续再计算状态转移的时候,该节点到下一个某状态节点(或称为目标节点)的概率一定也是大于其他节点到下一个某状态节点的概率的,至于会到哪一个目标节点,只取决于当前节点到目标节点的转移分数以及目标节点的状态分数,但无论到哪个节点,当前节点在最优路径上这个判断是毋庸置疑的了。如下图:
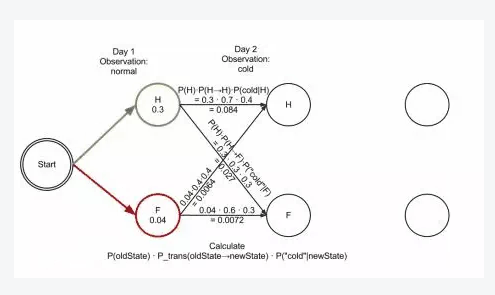
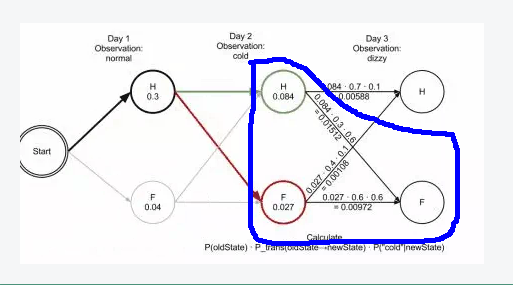
H,F之间的转移概率是固定的,包括H->H和F->F,都来自于转移分数矩阵,比如上图蓝色框中的0.084 * 0.3 * 0.6是来自H0.084节点,该节点是上一层计算得到的虽大概率的路径上的节点,你可能会想,如果这一层计算H->F的概率比F->F的概率小怎么办,维特比算法是不是就不是全局最优解了?其实这一层计算H->F的概率比F->F的概率小的情况不会出现,我们来看这一层(蓝色框)两个状态转移概率的计算:
- H->F 0.084 * 0.3 * 0.6
- F->F 0.027 * 0.6 * 0.6
由于最后一个数字表示到最后一层F节点的状态分数,所以都是0.6,那么比较的时候可以不考虑,于是得到下面的计算式子: - 0.084 * 0.3 第一个数字是上一层求出的分数,这个分数是所有路径中的最大值,这个最大值的计算:0.084=0.3 * 0.3 * 0.3
- 0.027 * 0.6 第一个数字是上一层求出的分数,这个分数的计算:0.027=0.04 * 0.6 * 0.3
根据上面的逻辑,得到下面的式子: - 0.084 * 0.3 = 0.3 * 0.3 * 0.3 * 0.3
- 0.027 * 0.6 = 0.04 * 0.6 * 0.3 * 0.6
这里的第一项的0.3和0.04分别表示上一层的H和F节点的状态分数,我们分别设为a和b,现在已知a * 0.3 * 0.3=0.084,b * 0.6 * 0.3=0.027,0.084>0.027,所以后面再来一次转移,也就是0.084 * 0.3也一定是大于0.027 * 0.6的,如果还有更多层的话,后面的计算还是一个乘以0.3,一个乘以0.6吗,当然是的,因为0.3是H转移到F的转移概率,0.6是F转移到F的转移概率,这个转移概率是固定的。
所以当前层状态分数最大的节点,一定在最优路径上,以此递推到最后一层后,反过来追溯每次记录下来的概率最大的节点,就可以得到一条最优的路径了。
上图的最优路径是:Start-H-H-F
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。
用深度学习做命名实体识别(七)-CRF介绍的更多相关文章
- 用深度学习做命名实体识别(六)-BERT介绍
什么是BERT? BERT,全称是Bidirectional Encoder Representations from Transformers.可以理解为一种以Transformers为主要框架的双 ...
- 用深度学习做命名实体识别(二):文本标注工具brat
本篇文章,将带你一步步的安装文本标注工具brat. brat是一个文本标注工具,可以标注实体,事件.关系.属性等,只支持在linux下安装,其使用需要webserver,官方给出的教程使用的是Apac ...
- NLP入门(五)用深度学习实现命名实体识别(NER)
前言 在文章:NLP入门(四)命名实体识别(NER)中,笔者介绍了两个实现命名实体识别的工具--NLTK和Stanford NLP.在本文中,我们将会学习到如何使用深度学习工具来自己一步步地实现N ...
- 用CRF做命名实体识别(一)
用CRF做命名实体识别(二) 用CRF做命名实体识别(三) 用BILSTM-CRF做命名实体识别 博客园的markdown格式可能不太方便看,也欢迎大家去我的简书里看 摘要 本文主要讲述了关于人民日报 ...
- 用CRF做命名实体识别(二)
用CRF做命名实体识别(一) 用CRF做命名实体识别(三) 一. 摘要 本文是对上文用CRF做命名实体识别(一)做一次升级.多添加了5个特征(分别是词性,词语边界,人名,地名,组织名指示词),另外还修 ...
- 使用CRF做命名实体识别(三)
摘要 本文主要是对近期做的命名实体识别做一个总结,会给出构造一个特征的大概思路,以及对比所有构造的特征对结构的影响.先给出我最近做出来的特征对比: 目录 整体操作流程 特征的构造思路 用CRF++训练 ...
- 手把手教你用深度学习做物体检测(六):YOLOv2介绍
本文接着上一篇<手把手教你用深度学习做物体检测(五):YOLOv1介绍>文章,介绍YOLOv2在v1上的改进.有些性能度量指标术语看不懂没关系,后续会有通俗易懂的关于性能度量指标的介绍文章 ...
- 手把手教你用深度学习做物体检测(五):YOLOv1介绍
"之前写物体检测系列文章的时候说过,关于YOLO算法,会在后续的文章中介绍,然而,由于YOLO历经3个版本,其论文也有3篇,想全面的讲述清楚还是太难了,本周终于能够抽出时间写一些YOLO算法 ...
- NLP入门(八)使用CRF++实现命名实体识别(NER)
CRF与NER简介 CRF,英文全称为conditional random field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机 ...
随机推荐
- Jmeter 之 逻辑控制器 if 控制器
最近工作不忙,利用空闲时间整理了下Jmeter的相关知识,下面给大家分享下Jmeter中 如果(if)控制的使用和应用. 如下图:线程组 > 添加 > 逻辑控制器 > 如果 (if) ...
- CVE-2014-6271 Shellshock 破壳漏洞 复现
补坑. 什么是shellshock ShellShock是一个BashShell漏洞(据说不仅仅是Bash,其他shell也可能有这个漏洞). 一般情况来说,系统里面的Shell是有严格的权限控制的, ...
- springboot使用 @EnableScheduling、@Scheduled开启定时任务
1.在main启动项添加一个注解@EnableScheduling package com.example.springmybatis; import org.mybatis.spring.annot ...
- vue-cli3.0 Typescript 项目集成环信WebIM 群组聊天
项目背景 环信webim 官方没有vue版本的,自己就根据sdk重写了个vue版本的,只实现了基础的 登录 群组功能,其他的可以根据需要参考官方文档,添加相应的功能. 环信webim SDK相关文档: ...
- C#中using的使用-以FileStream写入文件为例
场景 CS中FileStream的对比以及使用方法: https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/100396022 关注公众号 ...
- java8 把List<Object> 根据某字段去重
import java.util.ArrayList;import java.util.List;import org.apache.shiro.SecurityUtils;import org. ...
- ACM团队周赛题解(1)
这次周赛题目拉了CF315和CF349两套题. 因为我代码模板较长,便只放出关键代码部分 #define ll long long #define MMT(s,a) memset(s, a, size ...
- 从零开始入门 K8s| K8s 的应用编排与管理
作者 | 张振 阿里巴巴高级技术专家 一.资源元信息 1. Kubernetes 资源对象 我们知道,Kubernetes 的资源对象组成:主要包括了 Spec.Status 两部分.其中 Spec ...
- Azure Application Insights REST API使用教程
本文是Azure Application Insights REST API的简单介绍,并会包含一个通过Python消费API的示例/小工具. 新加入的team中的一项工作是制作日常的运维报表,制作方 ...
- prometheus告警模块alertmanager注意事项(QQ邮箱发送告警)
配置alertmanager的时候,都是根据网上的教程来配置的. 因为我是用QQ邮箱来发送告警的,所以alertmanager.yml的邮箱配置如下: global: resolve_timeout: ...