四、排序算法总结二(归并排序)(C++版本)
一、什么是归并排序?
归并排序是基于分而治之的思想建立起来的。
所谓的分而治之,也就是将一个数据规模为N的数据集,分解为两个规模大小差不多的数据集(n/2),然而分别处理这两个更小的问题,就相当于解决了总的问题。
二、归并排序的思路。
1-首先将数据分为左右相等的两部分,不断细分,到最后只有单个元素。
2-再将相邻的两个元素集合(只是规模为1)排序,变为 n/2 个规模为2的数据序列。
随后不断的合并数据集并且排序,直到最后得到了一个完整的数据有序序列。
三、一个简单的例子。
下图是一个数据规模为8的数据集的排序过程。
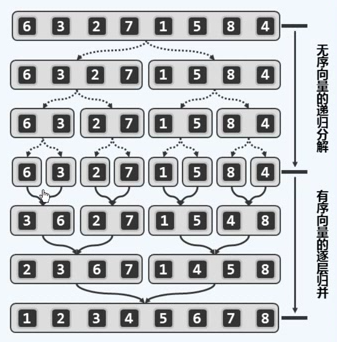
最开始8个数据不断地细分,知道不可再分(数据数目为一)
随后开始进行排序,将相邻的两个数据集排序合并,形成3 6,2 7, 1 5 ,4, 8
随后不断地向上排序,知道合并成一个完整的有序数据序列。
四 算法功能
上面的过程说明了算法需要完成的两个的算法功能
一是对于数据二分的过程,直到不可再分
二是对于两个数据集排序合并,形成一个更大的数据集的过程。
五、算法实现
1-递归版本
#include <stdlib.h>
#include <stdio.h> void Merge(int sourceArr[],int tempArr[], int startIndex, int midIndex, int endIndex)
{
int i = startIndex, j=midIndex+, k = startIndex;
while(i!=midIndex+ && j!=endIndex+)
{
if(sourceArr[i] > sourceArr[j])
tempArr[k++] = sourceArr[j++];
else
tempArr[k++] = sourceArr[i++];
}
while(i != midIndex+)
tempArr[k++] = sourceArr[i++];
while(j != endIndex+)
tempArr[k++] = sourceArr[j++];
for(i=startIndex; i<=endIndex; i++)//这里的复制是从头到尾的,
//我之前就是这里出了问题
sourceArr[i] = tempArr[i];
} //内部使用递归
void MergeSort(int sourceArr[], int tempArr[], int startIndex, int endIndex)
{
int midIndex;
if(startIndex < endIndex)
{
midIndex = startIndex + (endIndex-startIndex) / ;//避免溢出int
MergeSort(sourceArr, tempArr, startIndex, midIndex);
MergeSort(sourceArr, tempArr, midIndex+, endIndex);
Merge(sourceArr, tempArr, startIndex, midIndex, endIndex);
}
} int main(int argc, char * argv[])
{
int a[] = {, , , , , , , };
int i, b[];
MergeSort(a, b, , );
for(i=; i<; i++)
printf("%d ", a[i]);
printf("\n");
return ;
}
2-迭代版本
(待补充)
六、复杂度
时间复杂度: O(n log n)
空间复杂度:O(n)
四、排序算法总结二(归并排序)(C++版本)的更多相关文章
- Java排序算法(二)
java排序算法(二) 二.改进排序算法 2.1希尔排序 定义:希尔排序(ShellSort)是插入排序的一种.也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本.希尔排序是非稳定排序算法. ...
- java讲讲几种常见的排序算法(二)
java讲讲几种常见的排序算法(二) 目录 java讲讲几种常见的排序算法(一) java讲讲几种常见的排序算法(二) 堆排序 思路:构建一个小顶堆,小顶堆就是棵二叉树,他的左右孩子均大于他的根节点( ...
- java排序算法(二):直接选择排序
java排序算法(二) 直接选择排序 直接选择排序排序的基本操作就是每一趟从待排序的数据元素中选出最小的(或最大的)一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完,它需要经过n- ...
- 《算法导论》读书笔记之排序算法—Merge Sort 归并排序算法
自从打ACM以来也算是用归并排序了好久,现在就写一篇博客来介绍一下这个算法吧 :) 图片来自维基百科,显示了完整的归并排序过程.例如数组{38, 27, 43, 3, 9, 82, 10}. 在算法导 ...
- [Swift]八大排序算法(二):快速排序
排序分为内部排序和外部排序. 内部排序:是指待排序列完全存放在内存中所进行的排序过程,适合不太大的元素序列. 外部排序:指的是大文件的排序,即待排序的记录存储在外存储器上,待排序的文件无法一次装入内存 ...
- 数据结构Java版之排序算法(二)
排序按时间复杂度和空间复杂度可分为 低级排序 和 高级排序 算法两种.下面将对排序算法进行讲解,以及样例的展示. 低级排序:冒泡排序.选择排序.插入排序. 冒泡排序: 核心思想,小的数往前移.假设最小 ...
- 【Java】 大话数据结构(17) 排序算法(4) (归并排序)
本文根据<大话数据结构>一书,实现了Java版的归并排序. 更多:数据结构与算法合集 基本概念 归并排序:将n个记录的序列看出n个有序的子序列,每个子序列长度为1,然后不断两两排序归并,直 ...
- 八大排序算法之二希尔排序(Shell Sort)
希尔排序是1959 年由D.L.Shell 提出来的,相对直接排序有较大的改进.希尔排序又叫缩小增量排序 基本思想: 先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 ...
- 排序算法入门之归并排序(java实现)
归并排序是采用分治法的典型应用. 参考<数据结构与算法分析-Java语言描述> 归并排序其实要做两件事: (1)"分解"--将序列每次折半划分. (2)"合并 ...
随机推荐
- Flask 教程 第十二章:日期和时间
本文翻译自The Flask Mega-Tutorial Part XII: Dates and Times 这是Flask Mega-Tutorial系列的第十二部分,我将告诉你如何以适配所有用户的 ...
- springcloud vue.js 微服务分布式 前后分离 集成代码生成器 shiro权限 activiti工作流
1.代码生成器: [正反双向](单表.主表.明细表.树形表,快速开发利器)freemaker模版技术 ,0个代码不用写,生成完整的一个模块,带页面.建表sql脚本.处理类.service等完整模块2. ...
- Cesium数据可视化-仓储调度系统可视化部分(附github源码)
Cesium数据可视化-仓储调度系统可视化部分 目的 仓储调度系统需要一个可视化展示物资运输实况的界面,需要配合GPS设备发送的位置信息,实时绘制物资运输情况和仓储仓库.因此,使用Cesium可视化该 ...
- Flink01
1. 什么是Flink? 1.1 4代大数据计算引擎 第一代: MapReducer 批处理 Mapper, Reducer Hadoop的MapReducer将计算分为两个阶段, 分别为Map和Re ...
- 程序员:May the Force be with you!
程序员如何理解:May the Force be with you! 我们并没有向其他人那样讨论现象级产品的生成原因,因为我们并不清楚这个原因是什么. 我们也不知道足记是否会重复过去一些现象级产品忽生 ...
- Dockerfile优化
总结: 1.编写.dockerignore文件 2.容器只运行单个应用 3.将多个RUN指令合并为一个 4.基础镜像的标签不要用latest 5.每个RUN指令后删除多余文件 6.选择合适的基础镜像( ...
- Shell脚本监控CPU、内存和硬盘利用率
1.监控CPU利用率(通过vmstat工具) #!/bin/bash #==================================================== # Author: l ...
- 浅谈python面向对象编程和面向过程编程的区别
面向过程:分析出解决问题所需要的步骤,然后用函数把这些步骤一步步实现,使用的时候再一个个的依次调用即可. 优点:性能高 缺点:相较于面向对象而言,不易维护,不易复用,不易扩展 适合于小型的项目面向对象 ...
- 多项式总结(STAGE 1)
这么难的专题居然只给了这么短时间... 然而在NC的教导之下还是有一定的收获的. 必须打广告:0,1,2,3 附带一个垃圾博客:-1 按照习惯,堆砌结论而不加证明. Section1 导数: 基本形式 ...
- 网络编程懒人入门(十):一泡尿的时间,快速读懂QUIC协议
1.TCP协议到底怎么了? 现时的互联网应用中,Web平台(准确地说是基于HTTP及其延伸协议的客户端/服务器应用)的数据传输都基于 TCP 协议. 但TCP 协议在创建连接之前需要进行三次握手(如下 ...