RNN循环神经网络
1.为什么还会有RNN?
CNN(卷积神经网络)我们会发现, 他们的输出都是只考虑前一个输入的影响而不考虑其它时刻输入的影响, 比如简单的猫,狗,手写数字等单个物体的识别具有较好的效果. 但是, 对于一些与时间先后有关的, 比如视频的下一时刻的预测,文档前后文内容的预测等, 这些算法的表现就不尽如人意了.因此, RNN就应运而生了
2.什么是RNN?
RNN是一种特殊的神经网络结构, 它是根据"人的认知是基于过往的经验和记忆"这一观点提出的. 它与DNN,CNN不同的是: 它不仅考虑前一时刻的输入,而且赋予了网络对前面的内容的一种'记忆'功能
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出
3.RNN的主要应用领域
- 自然语言处理(NLP):主要有视频处理,文本生成,语言模型,图像处理
- 机器翻译,机器写小说
- 语音识别
- 图像描述生成
- 文本相似度计算
- 音乐推荐,网易考拉商品推荐,视频推荐等等新的应用领域
4.RNN模型结构
RNN怎么实现记忆功能?

如图所示, 我们可以看到RNN层级结构较之于CNN来说比较简单, 它主要有输入层,Hidden Layer, 输出层组成.
并且会发现在Hidden Layer 有一个箭头表示数据的循环更新, 这个就是实现时间记忆功能的方法
RNN展开
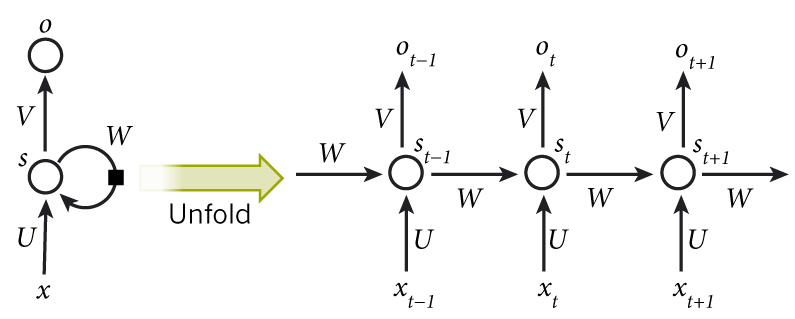
如图所示为Hidden Layer的层级展开图. t-1, t, t+1表示时间序列. X表示输入的样本. St表示样本在时间t处的的记忆,St = f(W*St-1 +U*Xt). W表示输入的权重, U表示此刻输入的样本的权重, V表示输出的样本权重。
在t =1时刻, 一般初始化输入S0=0, 随机初始化W,U,V, 进行下面的公式计算
其中,f和g均为激活函数. 其中f可以是tanh,relu,sigmoid等激活函数,g通常是softmax也可以是其他
时间就向前推进,此时的状态s1作为时刻1的记忆状态将参与下一个时刻的预测活动.
依次类推,可以得到最终的输出值
注:
这里的W,U,V在每个时刻都是相等的(权重共享).
隐藏状态可以理解为: S=f(现有的输入+过去记忆总结)
5.RNN代码示例
动态RNN和静态RNN
静态RNN:
静态 rnn的意思就是按照样本时间序列个数(n_steps)展开,在图中创建(n_steps)个序列的cell。
动态RNN:
动态rnn的意思是只创建样本中的一个序列RNN,其他序列数据会通过循环进入该RNN运算通过。
区别:
静态生成的RNN网络,生成过程所需的时间会更长,网络所占有的内存会更多,导出的模型会更大。模型中会带有第个序列中间态的信息,利于调试。在使用时必须与训练的样本序列个数相同。通过动态生成的RNN网络,所占用内存较少。模型中只会有最后的状态,在使用时还能支持不同的序列个数。
# 导包,加载数据,定义变量
import tensorflow as tf
# 流式计算图,构建第二次的时候会有内存,计算图形的时候初始化
tf.reset_default_graph()
import datetime # 打印时间
import os # 保存文件
from tensorflow.examples.tutorials.mnist import input_data import warnings
warnings.filterwarnings('ignore')
# minst测试集
mnist = input_data.read_data_sets('./', one_hot=True) # 每次使用100条数据进行训练
batch_size = 100
# 图像向量
width = 28
height = 28
# LSTM隐藏神经元数量
rnn_size = 256
# 输出层one-hot向量长度的
out_size = 10 def weight_variable(shape, w_alpha=0.01):
initial = w_alpha * tf.random_normal(shape)
return tf.Variable(initial) def bias_variable(shape, b_alpha=0.1):
initial = b_alpha * tf.random_normal(shape)
return tf.Variable(initial) # 权重及偏置
w = weight_variable([rnn_size, out_size])
b = bias_variable([out_size]) # 将数据转化成RNN要求的数据
# 按照图片大小申请占位符
X = tf.placeholder(tf.float32, [None, height, width])
# 原排列[0,1,2]transpose为[1,0,2]代表前两维装置,如shape=(1,2,3)转为shape=(2,1,3)
# 这里的实际意义是把所有图像向量的相同行号向量转到一起,如x1的第一行与x2的第一行
x = tf.transpose(X, [1, 0, 2])
# reshape -1 代表自适应,这里按照图像每一列的长度为reshape后的列长度
x = tf.reshape(x, [-1, width])
# split默任在第一维即0 dimension进行分割,分割成height份,这里实际指把所有图片向量按对应行号进行重组
x = tf.split(x, height) # 构建神经网络
# LSTM
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(rnn_size)
# 这里RNN会有与输入层相同数量的输出层,我们只需要最后一个输出
outputs, status = tf.nn.static_rnn(lstm_cell, x, dtype=tf.float32) y_conv = tf.add(tf.matmul(outputs[-1], w), b)
# 最小化损失优化
Y = tf.placeholder(dtype=tf.float32,shape = [None,10])
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_conv, labels=Y))
optimizer = tf.train.AdamOptimizer(0.01).minimize(loss)
# 偏差 准确率
correct = tf.equal(tf.argmax(y_conv, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) # 模型训练
# 启动会话.开始训练
saver = tf.train.Saver()
session = tf.Session()
session.run(tf.global_variables_initializer())
step = 0
acc_rate = 0.90
while 1:
batch_x, batch_y = mnist.train.next_batch(batch_size)
batch_x = batch_x.reshape((batch_size, height, width))
session.run(optimizer, feed_dict={X:batch_x,Y:batch_y})
# 每训练10次测试一次
if step % 10 == 0:
batch_x_test = mnist.test.images
batch_y_test = mnist.test.labels
batch_x_test = batch_x_test.reshape([-1, height, width])
acc = session.run(accuracy, feed_dict={X: batch_x_test, Y: batch_y_test})
print(datetime.datetime.now().strftime('%c'), ' step:', step, ' accuracy:', acc)
# 偏差满足要求,保存模型
if acc >= acc_rate:
model_path = os.getcwd() + os.sep + str(acc_rate) + "mnist.model"
saver.save(session, model_path, global_step=step)
break
step += 1
session.close()
静态RNN
import tensorflow as tf
tf.reset_default_graph()
from tensorflow.examples.tutorials.mnist import input_data # 载入数据
mnist = input_data.read_data_sets("./", one_hot=True) # 输入图片是28
n_input = 28
max_time = 28
lstm_size = 100 # 隐藏单元
n_class = 10 # 10个分类
batch_size = 50 # 每次50个样本
n_batch_size = mnist.train.num_examples // batch_size # 计算一共有多少批次 # 这里None表示第一个维度可以是任意长度
# 创建占位符
x = tf.placeholder(tf.float32,[None, 28*28])
# 正确的标签
y = tf.placeholder(tf.float32,[None, 10]) # 初始化权重 ,stddev为标准差 truncated_normal 裁剪过得正太分布,去掉特别大和特别小的值
weight = tf.Variable(tf.truncated_normal([lstm_size, n_class], stddev=0.1))
# 初始化偏置层
biases = tf.Variable(tf.constant(0.1, shape=[n_class])) # 定义RNN网络
def RNN(X, weights, biases):
# 原始数据为[batch_size,28*28]
# input = [batch_size, max_time, n_input]
input = tf.reshape(X,[-1, max_time, n_input])
# 定义LSTM的基本单元
# lstm_cell = tf.contrib.rnn.BasicLSTMCell(lstm_size)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(lstm_size)
# final_state[0] 是cell state
# final_state[1] 是hidden stat
outputs, final_state = tf.nn.dynamic_rnn(lstm_cell, input, dtype=tf.float32)
display(final_state)
results = tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results # 计算RNN的返回结果
prediction = RNN(x, weight, biases)
# 损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction, labels=y))
# 使用AdamOptimizer进行优化
train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)
# 将结果存下来
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
# 计算正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(6):
for batch in range(n_batch_size):
# 取出下一批次数据
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x: batch_xs,y: batch_ys})
if(batch%100==0):
print(str(batch)+"/" + str(n_batch_size))
acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels})
print("Iter" + str(epoch) + " ,Testing Accuracy = " + str(acc))
动态RNN
RNN循环神经网络的更多相关文章
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
https://www.zhihu.com/question/34681168 CNN(卷积神经网络).RNN(循环神经网络).DNN(深度神经网络)的内部网络结构有什么区别?修改 CNN(卷积神经网 ...
- Recurrent Neural Networks(RNN) 循环神经网络初探
1. 针对机器学习/深度神经网络“记忆能力”的讨论 0x1:数据规律的本质是能代表此类数据的通用模式 - 数据挖掘的本质是在进行模式提取 数据的本质是存储信息的介质,而模式(pattern)是信息的一 ...
- CNN(卷积神经网络)、RNN(循环神经网络)、DNN,LSTM
http://cs231n.github.io/neural-networks-1 https://arxiv.org/pdf/1603.07285.pdf https://adeshpande3.g ...
- TensorFlow框架(6)之RNN循环神经网络详解
1. RNN循环神经网络 1.1 结构 循环神经网络(recurrent neural network,RNN)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络.RNN的主 ...
- Keras(四)CNN 卷积神经网络 RNN 循环神经网络 原理及实例
CNN 卷积神经网络 卷积 池化 https://www.cnblogs.com/peng8098/p/nlp_16.html 中有介绍 以数据集MNIST构建一个卷积神经网路 from keras. ...
- 关于 RNN 循环神经网络的反向传播求导
关于 RNN 循环神经网络的反向传播求导 本文是对 RNN 循环神经网络中的每一个神经元进行反向传播求导的数学推导过程,下面还使用 PyTorch 对导数公式进行编程求证. RNN 神经网络架构 一个 ...
- 4.5 RNN循环神经网络(recurrent neural network)
自己开发了一个股票智能分析软件,功能很强大,需要的点击下面的链接获取: https://www.cnblogs.com/bclshuai/p/11380657.html 1.1 RNN循环神经网络 ...
- 神经网络6_CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)概念区分理解
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程,QQ:231469242) https://study.163.com/course/introduction.htm?courseId ...
- CNN(卷积神经网络)、RNN(循环神经网络)和DNN(深度神经网络)
本文转载修改自:知乎-科言君 感知机(perceptron) 神经网络技术起源于上世纪五.六十年代,当时叫感知机(perceptron),拥有输入层.输出层和一个隐含层.输入的特征向量通过隐含层变换达 ...
- RNN循环神经网络学习——概述
循环神经网络(Recurrent Neural NetWork,RNN)是一种将节点定向连接成环的人工神经网络,其内部状态可以展示动态时序行为. 循环神经网络的主要用途是处理和预测序列数据.循环神经网 ...
随机推荐
- node读取excel文件生成JSON
当前的目录结构 excel的数据如下: node识别excel,先得安装 node-xlsx,用npm或yarn都可以 npm install node-xlsx 或 yarn add node- ...
- windows anaconda python3.7 import ssl,psycopg2报错
使用anaconda,本来是为了减少装第三方模块依赖出错问题的. 但是,今天发现,也是有坑啊. 首先 import ssl 报错,import _ssl 说DLL load failed 解决办法:用 ...
- Mint UI Example的运行
Mint -UI是新推出的移动端UI框架 官网 不过官网上的文档例子不是很全面. 建议下载他们提供的example来学习. 1.examplle源码下载地址 2.打开项目,我这里使用webstorm, ...
- H3C交换机DHCP基础配置案例 v7版本
一.需求 要求在Switch A上配置DHCP服务器功能实现:• 为网络内的客户端动态分配 10.1.1.0/24 网段内的 IP 地址.租用有效期限. DNS 信息.网关地址等配置信息:• 根据 S ...
- python3 之 函数传参
一.可变对象与不可变对象 在 python 中,strings, tuples, 和 numbers 是不可更改的对象,而 list,dict 等则是可以修改的对象. 不可变类型:变量赋值 a=5 后 ...
- Spring(Bean)1
Spring支持3种依赖注入的方式 (DI依赖注入)*属性注入 (配置bean set方法注入) <bean id="car" class="spring.bean ...
- python numpy学习
以下代码来源于本博文作者观看大神视频并纯手敲. 目录 numpy的属性 创建array numpy的运算1 随机数生成以及矩阵的运算2 numpy的索引 array合并 array分割 numpy的浅 ...
- ++a与a++、--a与a--
++a 与 a++ public class Demo { public static void main(String[] args) { int a = 1; System.out.println ...
- desc和show
desc只能查看表结构 查看zx1表结构 desc zx1; mysql> desc zx1 -> ; +---------+---------+------+-----+-------- ...
- xcode8 运行项目时自己打印些东西
使用 Xcode 8 运行工程的时候,在打印台会发现如下这些奇怪的日志输出: 2016-09-19 10:43:44.001757 Demo[7100:171568] subsystem: com.a ...