python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池
用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用。
作用:每次访问代表使用的浏览器不一样
import urllib.request
import re
import random
uapools=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
]
def ua(uapools):
thisua=random.choice(uapools)
print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
for i in range(10):
ua(uapools)
thisurl="https://www.qiushibaike.com/text/page/"+str(i+1)+"/";
data=urllib.request.urlopen(thisurl).read().decode("utf-8","ignore")
pat='<div class="content">.*?<span>(.*?)</span>.*?</div>'
res=re.compile(pat,re.S).findall(data)
for j in range(len(res)):
print(res[j])
print('---------------------')
IP代理与IP代理池的构建的两种方案
搜索西刺、大象代理IP
尽量选国外的IP。
import urllib.request
ip="219.131.240.35"
proxy=urllib.request.ProxyHandler({"http":ip})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
url="https://www.baidu.com/"
data=urllib.request.urlopen(url).read()
fp=open("ip_baidu.html","wb")
fp.write(data)
fp.close()
IP代理池构建的第一种方式(适合代理IP稳定的情况)
import random
import urllib.request
ippools=[
"163.125.70.22",
"111.231.90.122",
"121.69.37.6",
]
def ip(ippools):
thisip=random.choice(ippools)
print(thisip)
proxy=urllib.request.ProxyHandler({"http":thisip})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
for i in range(5):
try:
ip(ippools)
url="https://www.baidu.com/"
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
print(len(data))
fp=open("ip_res/ip_baidu_"+str(i+1)+".html","w")
fp.write(data)
fp.close()
except Exception as err:
print(err)
IP代理池构建的第二种方式(接口调用法,更适合代理IP不稳定的情况)
此方法因为经济原因暂时鸽着。
淘宝商品图片爬虫
现在的淘宝反爬虫,下面这份代码已经爬不了了,但可以作为练习。
import urllib.request
import re
import random
keyname="python"
key=urllib.request.quote(keyname) #网址不能有中文,这里处理中文
uapools=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
]
def ua(uapools):
thisua=random.choice(uapools)
print(thisua)
headers=("User-Agent",thisua)
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
for i in range(1,11): #第1页到第10页
ua(uapools)
url="https://s.taobao.com/search?q="+key+"&s="+str((i-1)*44)
data=urllib.request.urlopen(url).read().decode("UTF-8","ignore")
pat='pic_url":"//(.*?)"'
imglist=re.compile(pat).findall(data)
print(len(imglist))
for j in range(len(imglist)):
thisimg=imglist[j]
thisimgurl="https://"+thisimg
localfile="淘宝图片/"+str(i)+str(j)+".jpg"
urllib.request.urlretrieve(thisimgurl,localfile)
同时使用用户代理池和IP代理池
封装成函数:
import urllib.request
import re
import random
uapools=[
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; ) AppleWebKit/534.12 (KHTML, like Gecko) Maxthon/3.0 Safari/534.12',
]
ippools=[
"163.125.70.22",
"111.231.90.122",
"121.69.37.6",
]
def ua_ip(myurl):
def ip(ippools,uapools):
thisip=random.choice(ippools)
print(thisip)
thisua = random.choice(uapools)
print(thisua)
headers = ("User-Agent", thisua)
proxy=urllib.request.ProxyHandler({"http":thisip})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
opener.addheaders = [headers]
urllib.request.install_opener(opener)
for i in range(5):
try:
ip(ippools,uapools)
url=myurl
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
print(len(data))
break
except Exception as err:
print(err)
return data
data=ua_ip("https://www.baidu.com/")
fp=open("uaip.html","w",encoding="utf-8")
fp.write(data)
fp.close()
封装成模块:
把模块拷贝到python目录
使用:
from uaip import *
data=ua_ip("https://www.baidu.com/")
fp=open("baidu.html","w",encoding="utf-8")
fp.write(data)
fp.close()
抓包分析
fiddler工具:用作代理服务器,request和response都要经过fiddler
选用火狐浏览器,设置网络: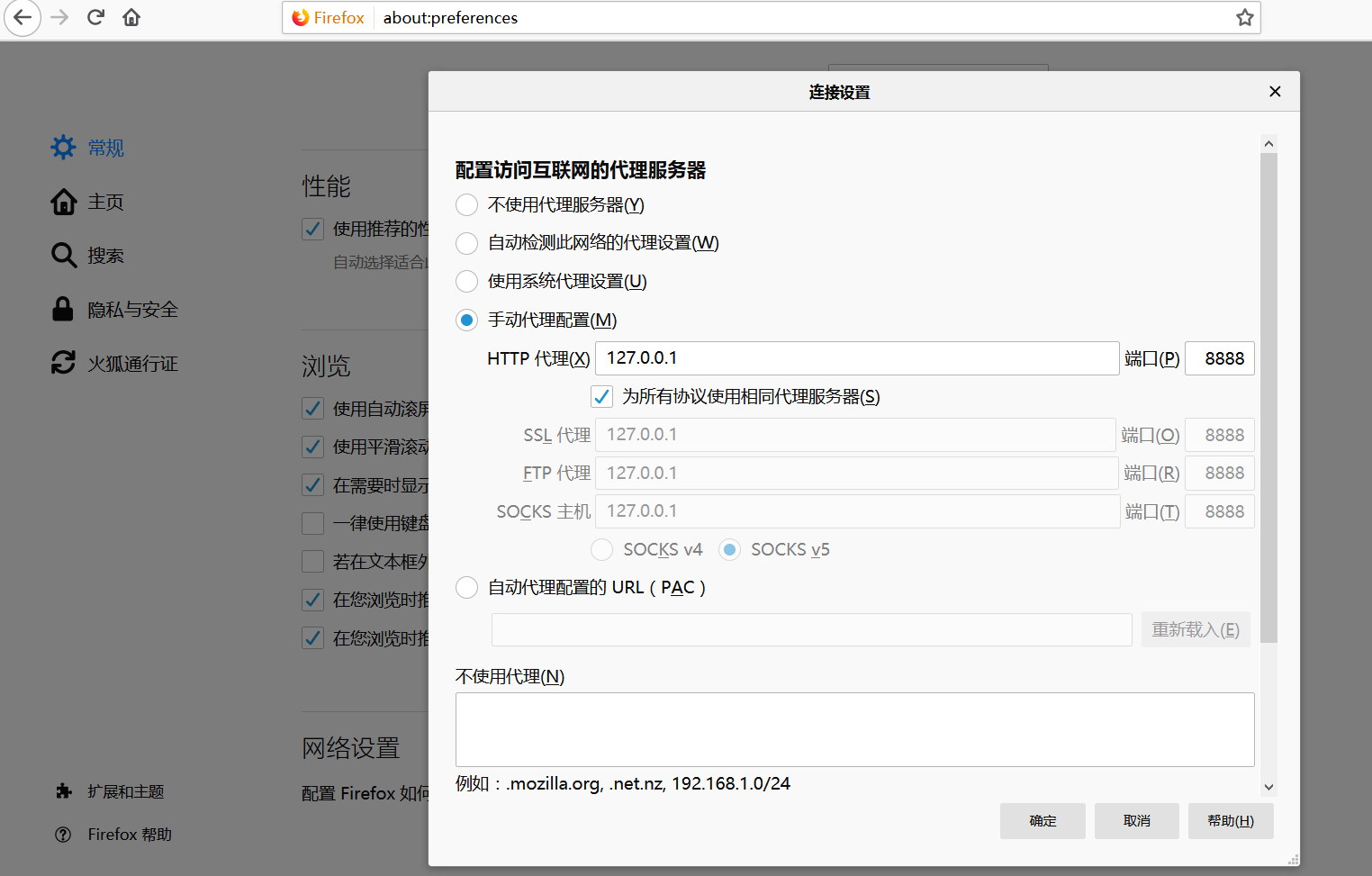
设置HTTPS协议:打开fiddler的工具的选项,打上勾

然后点Actions选导入到桌面。
再回到火狐的设置
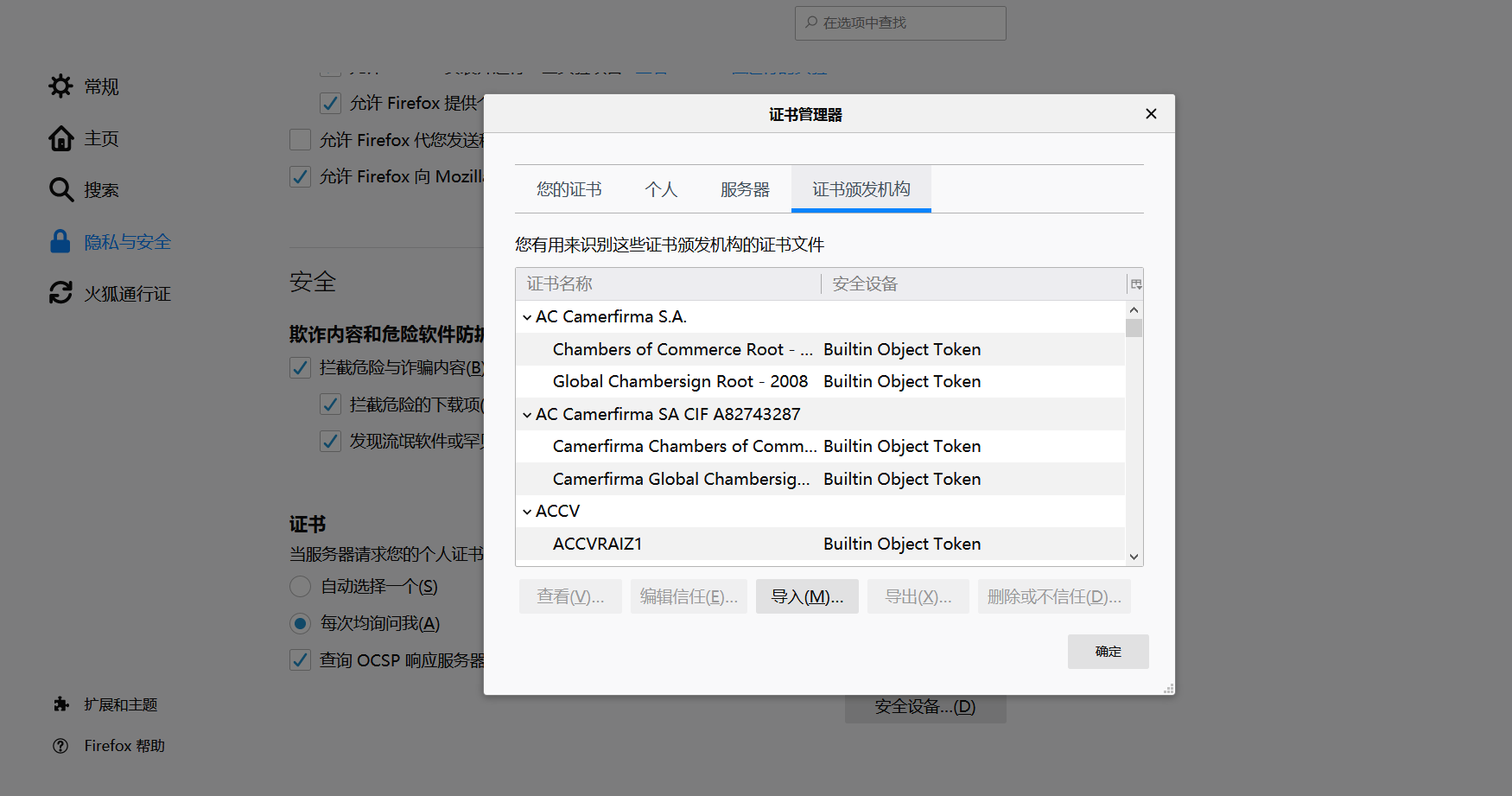
导入桌面上的证书
常用命令clear:清屏
自动进行Ajax异步请求数据
如微博,拖到下面的时候数据才加载出来,不是同步出来的。再如“点击加载更多”,都是异步,需要抓包分析。
看下面这个栗子。
腾讯视频评论(深度解读)爬虫实战
在火狐浏览器打开腾讯视频,比如https://v.qq.com/x/cover/j6cgzhtkuonf6te.html
点击查看更多解读,这时fiddler会有一个js文件:
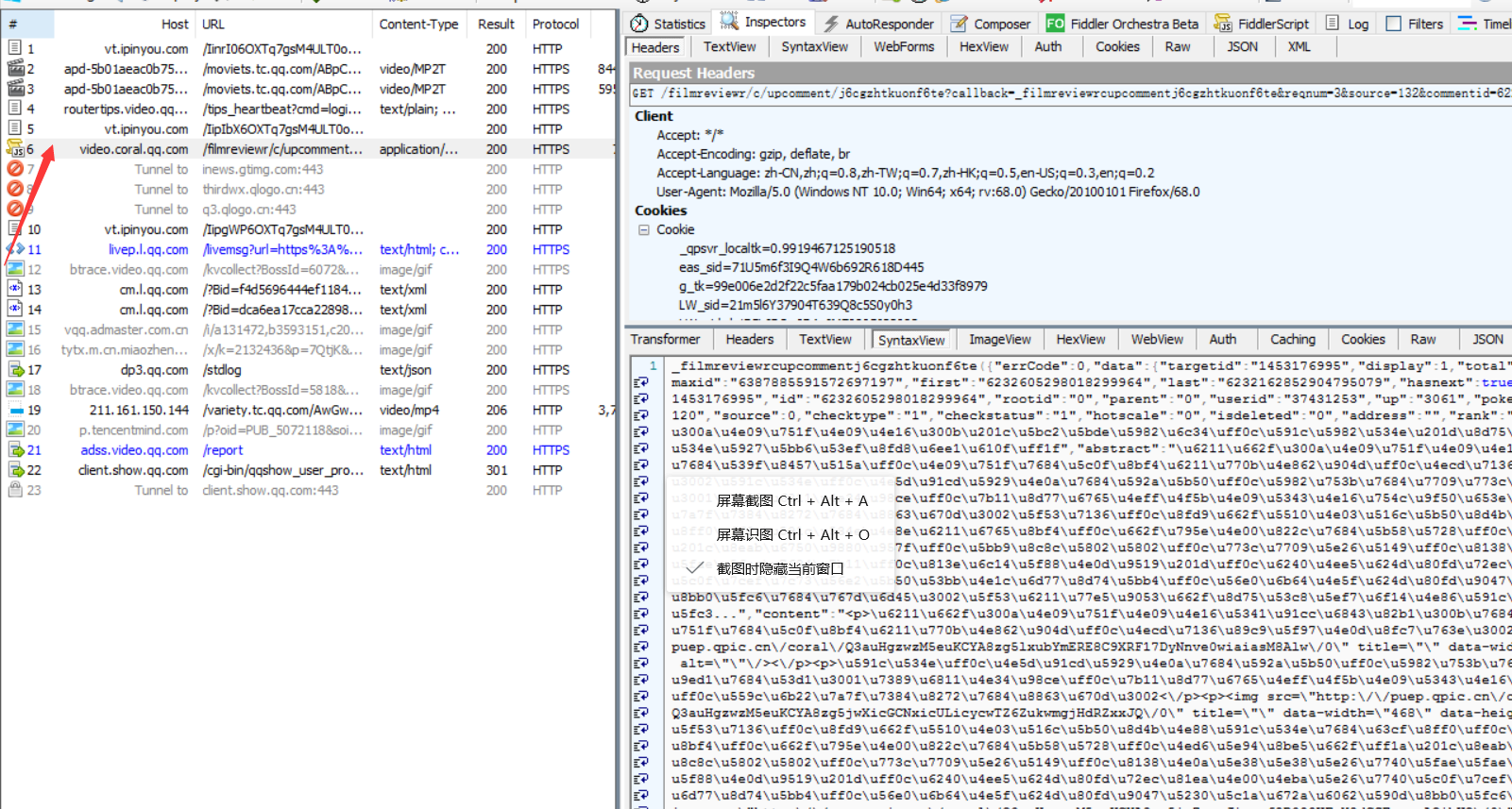
里面的内容就是评论。
找到一条评论转一下码: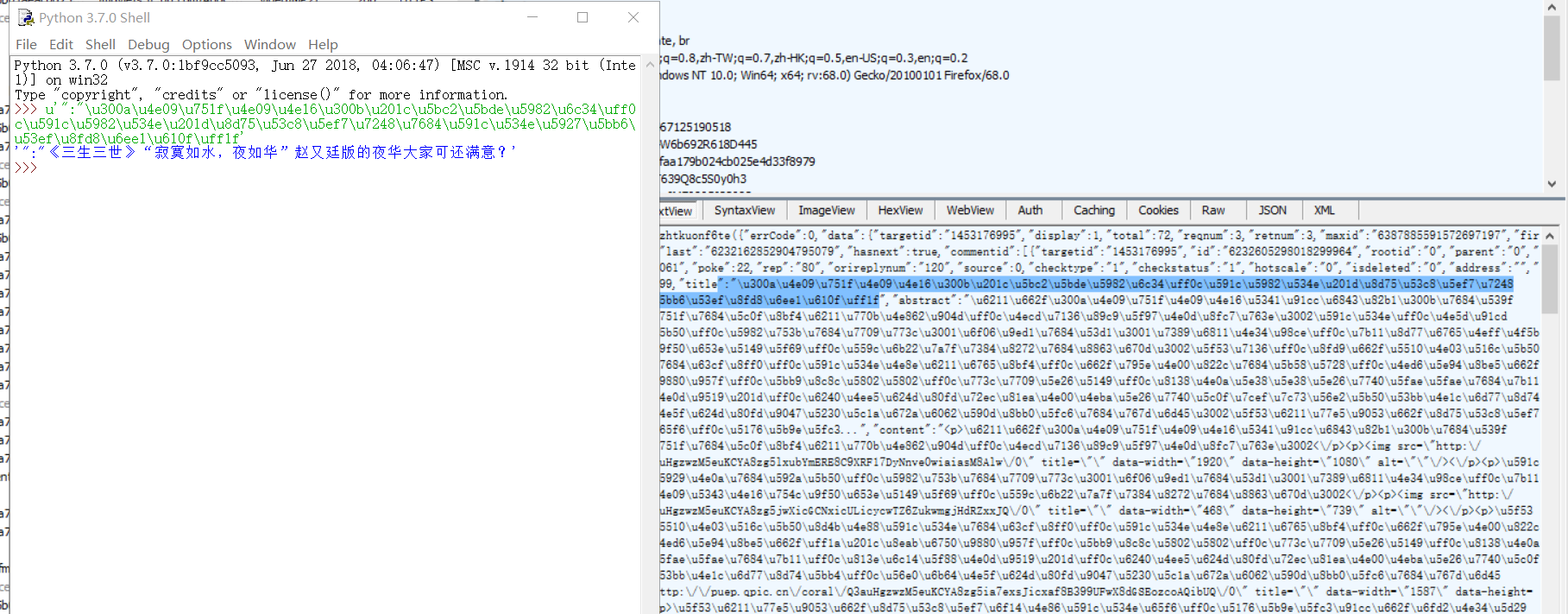
在火狐里ctrl+f看看有没有这条评论。
copy js文件的url。
点击查看更多评论,再触发一个json,copy url
分析两个url:
通过分析,我们可以知道j6cg……是视频id,reqnum是每次查看的评论数量,commentid是评论id
https://video.coral.qq.com/filmreviewr/c/upcomment/【vid】?reqnum=【num】&commentid=【cid】
- 单页评论爬虫
有一些特殊字符比如图片现在还不知道怎么处理……以后再说吧
import urllib.request
import re
from uaip import *
vid="j6cgzhtkuonf6te"
cid="6227734628246412645"
num="3" #每页提取3个
url="https://video.coral.qq.com/filmreviewr/c/upcomment/"+vid+"?reqnum="+num+"&commentid="+cid
data=ua_ip(url)
titlepat='"title":"(.*?)","abstract":"'
commentpat='"content":"(.*?)",'
titleall=re.compile(titlepat,re.S).findall(data)
commentall=re.compile(commentpat,re.S).findall(data)
# print(len(commentall))
for i in range(len(titleall)):
try:
print("评论标题是:"+eval("u'"+titleall[i]+"'"))
print("评论内容是:"+eval("u'"+commentall[i]+"'"))
print('---------------')
except Exception as err:
print(err)
翻页评论爬虫
查看网页源代码可以发现last:后面的内容为下一页的idimport urllib.request
import re
from uaip import *
vid="j6cgzhtkuonf6te"
cid="6227734628246412645"
num="3"
for j in range(10): #爬取1~10页内容
print("第"+str(j+1)+"页")
url = "https://video.coral.qq.com/filmreviewr/c/upcomment/" + vid + "?reqnum=" + num + "&commentid=" + cid
data = ua_ip(url)
titlepat = '"title":"(.*?)","abstract":"'
commentpat = '"content":"(.*?)",'
titleall = re.compile(titlepat, re.S).findall(data)
commentall = re.compile(commentpat, re.S).findall(data)
lastpat='"last":"(.*?)"'
cid=re.compile(lastpat,re.S).findall(data)[0]
for i in range(len(titleall)):
try:
print("评论标题是:" + eval("u'" + titleall[i] + "'"))
print("评论内容是:" + eval("u'" + commentall[i] + "'"))
print('---------------')
except Exception as err:
print(err)
对于短评(普通评论)方法类似,这里就不赘述了,看下面这个短评爬虫代码:
import urllib.request
import re
from uaip import *
vid="1743283224"
cid="6442954225602101929"
num="5"
for j in range(10): #爬取1~10页内容
print("第"+str(j+1)+"页")
url="https://video.coral.qq.com/varticle/"+vid+"/comment/v2?orinum="+num+"&oriorder=o&pageflag=1&cursor="+cid
data = ua_ip(url)
commentpat = '"content":"(.*?)"'
commentall = re.compile(commentpat, re.S).findall(data)
lastpat='"last":"(.*?)"'
cid=re.compile(lastpat,re.S).findall(data)[0]
# print(len(gg))
# print(len(commentall))
for i in range(len(commentall)):
try:
print("评论内容是:" + eval("u'" + commentall[i] + "'"))
print('---------------')
except Exception as err:
print(err)
python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫的更多相关文章
- 静听网+python爬虫+多线程+多进程+构建IP代理池
目标网站:静听网 网站url:http://www.audio699.com/ 目标文件:所有在线听的音频文件 附:我有个喜好就是听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续一)
通过前一节得出地址可能的构建规律,如下: https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksT ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析
一.抓包基础 在淘宝上搜索“Python机器学习”之后,试图抓取书名.作者.图片.价格.地址.出版社.书店等信息,查看源码发现html-body中没有这些信息,分析脚本发现,数据存储在了g_page_ ...
- Jmeter设置代理,抓包之app请求
步骤: 1. Jmeter选择测试计划,添加线程组,添加http请求,添加监听器-察看结果树 2. 添加http代理服务器,右键添加非测试元件-添加http代理服务器 3. 端口改为8889,目标控制 ...
- [TCP/IP] 数据链路层-ethereal 抓包分析数据帧
1.下载 http://dx1.pc0359.cn/soft/e/ethereal.rar 2.打开软件,指定抓取的网卡,下面是我抓取自己的主要网卡数据 3.开启个ping命令 , 不停的ping一台 ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- python爬虫实战(三)--------搜狗微信文章(IP代理池和用户代理池设定----scrapy)
在学习scrapy爬虫框架中,肯定会涉及到IP代理池和User-Agent池的设定,规避网站的反爬. 这两天在看一个关于搜狗微信文章爬取的视频,里面有讲到ip代理池和用户代理池,在此结合自身的所了解的 ...
随机推荐
- [b0044] numpy_快速上手
1 概念理清 2 创建数组 2.1 f1= np.array( [ [1,2,3,4], [2,3,4,5], [3,4,5,6] ]) 其他代码 a= np.array([ [ [3.4,5,6,8 ...
- none 和 host 网络的适用场景
我们会首先学习 Docker 提供的几种原生网络,以及如何创建自定义网络.然后探讨容器之间如何通信,以及容器与外界如何交互. Docker 网络从覆盖范围可分为单个 host 上的容器网络和跨多个 h ...
- MySQL 优化 (二)
参数优化 Max_connections (1)简介 Mysql的最大连接数,如果服务器的并发请求量比较大,可以调高这个值,如果连接数越来越多,mysql会为每个连接提供单独的缓冲区,就会开销的越多的 ...
- Python入门基础学习(面向对象)
Python基础学习笔记(四) 面向对象的三个基本特征: 封装:把客观事物抽象并封装成对象,即将属性,方法和事件等集合在一个整体内 继承:允许使用现有类的功能并在无须重新改写原来的类情况下,对这些功能 ...
- You Are Given a Decimal String... CodeForces - 1202B [简单dp][补题]
补一下codeforces前天教育场的题.当时只A了一道题. 大致题意: 定义一个x - y - counter :是一个加法计数器.初始值为0,之后可以任意选择+x或者+y而我们由每次累加结果的最后 ...
- [HDU6288]Tree
题目 题解 首先读题就很成问题....英语咋办呐!!! 直接考虑有点复杂,直接分析每一条边能否被选入最终答案.对于这条边,看看他的\(size[v]\) 与 \(n-size[v]\) 是否都大于等于 ...
- Noip2016Day2T3 愤怒的小鸟
题目链接 problem 平面内有n个点,每次可以确定一条过原点且开口向上的抛物线,将这条抛物线上所有的点都删去.问最少需要删几次可以删掉全部的点. solution n比较小,直接状压一下.因为已经 ...
- jenkins传统模式发布istio应用
一.发布金丝雀版本 Pre Setps cd /var/lib/jenkins/workspace/istio-service-user-canary/istio-service-user # 旧版本 ...
- 乘积量化(Product Quantization)
乘积量化 1.简介 乘积量化(PQ)算法是和VLAD算法是由法国INRIA实验室一同提出来的,为的是加快图像的检索速度,所以它是一种检索算法,在矢量量化(Vector Quantization,VQ) ...
- 【STM32H7教程】第21章 STM32H7的NVIC中断分组和配置(重要)
完整教程下载地址:http://www.armbbs.cn/forum.php?mod=viewthread&tid=86980 第21章 STM32H7的NVIC中断分组和配置( ...