循环神经网络(RNN)的改进——长短期记忆LSTM
一:vanilla RNN
使用机器学习技术处理输入为基于时间的序列或者可以转化为基于时间的序列的问题时,我们可以对每个时间步采用递归公式,如下,We can process a sequence of vector x by applying a recurrence formula at every time step:
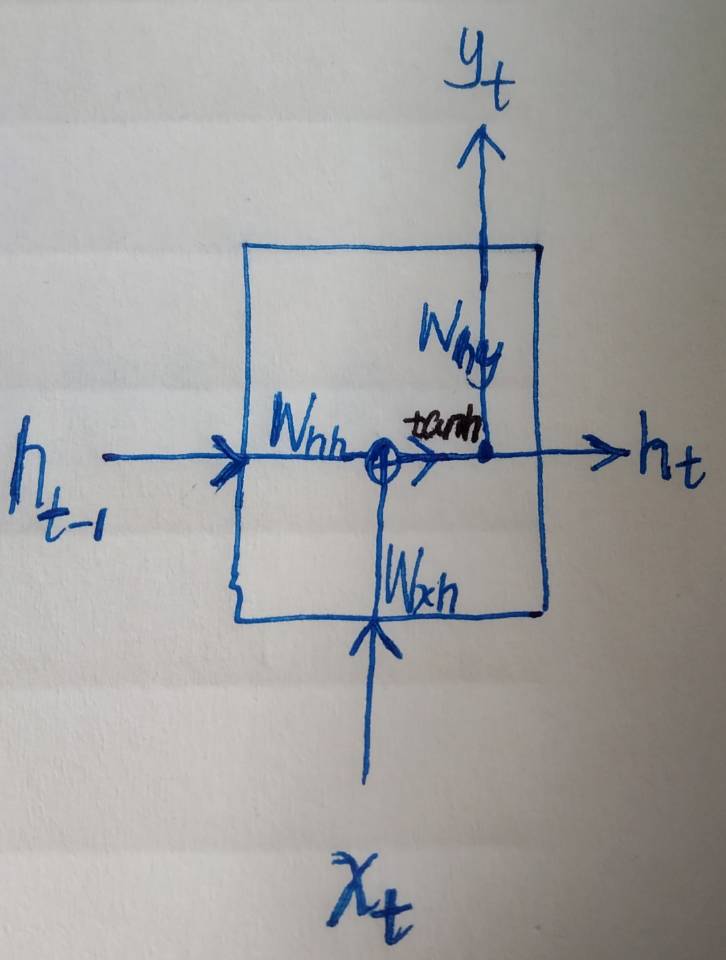
ht = fW( ht-1,xt )
其中xt 是在第t个时间步的输入(input vector at time step t);ht 是新状态量(new state),蕴含着前t个时间步的信息,在处理完xt后产生;ht-1 是前一个状态量(old state),蕴含着前t-1个时间步的信息,在处理完xt-1后产生;fW 是参数为W的从输入到输出的连接,在每个时间步都相同,反向传播对它的参数W进行优化。
original的RNN是这样的(以下简称vanilla RNN):
对于每个时间步:
ht = tanh(Whh • ht-1 + Wxh • xt) 或者用矩阵表示——ht = tanh( W • [ht-1,xt]T )
yt= Why • ht
图示:(当然描述它的图有很多,我自己画的这个比较直观易懂)
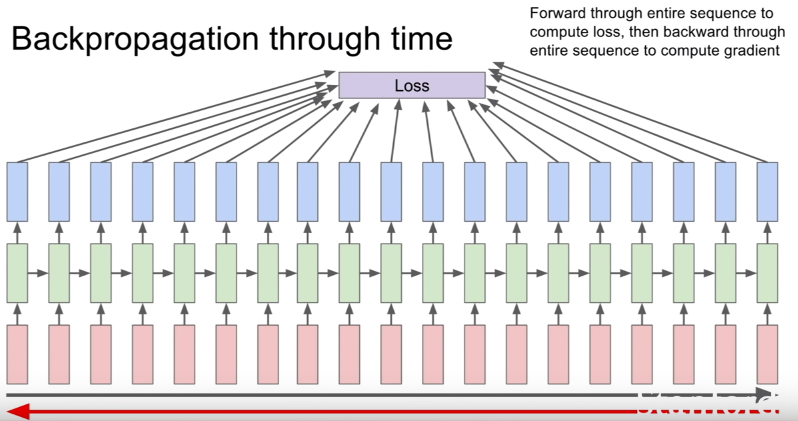
训练模型优化参数的时候通过基于时间的反向传播(BPTT)进行优化,这里不废话了,一个图就说明白了:(来自斯坦福Lecture 10 | Recurrent Neural Networks)
当时间步数大的时候也就是时间步数多的时候,vanillaRNN便不可避免的遇到了梯度爆炸(gradient exploding)与梯度消失(gradient vanishing)。如果参数大于1,backprop累乘下去,就会导致梯度很大——>+∞;如果参数小于1,backprop累乘下去,就会导致梯度很小——>0。为了对付这个问题,有人基于vanillaRNN设计了新的结构,LSTM与GRU相继被提出来。
二:LSTM
先看LSTM,vanillaRNN只有一个时序状态h,而LSTM有两个分别是h和c。LSTM将vanillaRNN的每个时序块改成一个cell,对于每个cell输入分别是xt,ht-1,ct-1,输出是ct和ht 。结构图如下:
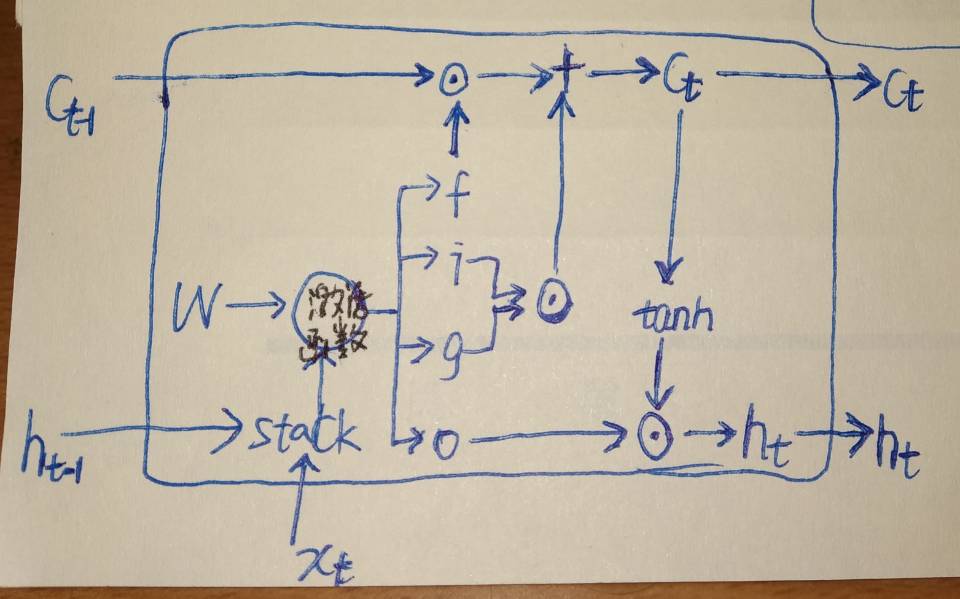
在LSTM的cell内部有四个门(gate)分别是f,i,g,o,
f:whether to erase cell
i:whether to write to cell
g:how much to write to cell
o:how much to reveal cell
数学表达是这样的:

ct = fꙨ ct-1 + i Ꙩ g
ht = o Ꙩ tan(ct)
反正让我看一眼结构图就记住LSTM结构,呃,悬,但是这个矩阵式子一扔立马就印刻在脑子里了。
前向传播弄明白了,那反向传播呢?
xxxxxxxxxxxxxxxxxxxxx
三:读论文《long short term memory》
>>hochriter做了六个实验,分别是:(不好意思我只看了其中1,2,4三个实验QAQ)
实验1,the embedded Reber grammar。聚焦于递归单元的标准基准测试(a standard benchmark test for recurrent nets)。Reber grammar是字符串生成器,实验要用LSTM来学习它。如果不知道什么是Reber grammar可以看这里:https://willamette.edu/~gorr/classes/cs449/reber.html,实验使用了7 input units & 7 output units,除了h门[-1,1]和g门[-2,2],其他的sigmoid激活后都在[0,1]的范围。除了output门的bias分别初始成-1,-2,-3,其他权重初始都是[-0.2,0.2]。学习率尝试了0.1,0.2,0.5。训练集和测试集分别有256个字符串样本,均是随机生成且免重。实验使用了三组不同的训练测试集。该实验说明了output门的重要性。Learning to store the first T or P should not perturb activations representing the more easily learnable transitions of the original Reber grammar。
实验2,noise-free and noisy sequences。
——"noise-free sequences with long time lags".有p+1个可能的输入符号,我们用a1,......,ap-1,ap=x,ap+1=y来表示。每个元素用p+1维的one_hot向量表示。有着p+1个输入单元和p+1个输出单元的网络模型序列地每个时间步读一个符号,并预测下一个符号。每个时间步都产生误差信号error signal。训练集仅由两个非常相似的序列(y , a1,......,ap-1 , y)和(x , a1,......,ap-1 , x)组成,每个序列被选择的概率相等。为了预测出最后一个元素,网络模型必须学会经过p个时间步依旧存储着第一个元素的信息。作者把LSTM与RTRL和BPTT以及Neural Sequence Chunker作比较,权重初始化[-0.2,0.2],训练使用了5百万个sequence presentations。训练好之后,当序列很长时,BPTT和RTRL都失败了,只有LSTM和CH成功。p=100的时候,2 -net sequence chunker成功了三分之一的尝试,而LSTM完美通过测试。
——"no local regularities",作者说,上面的实验中chunker有时成功预测了序列的最后元素,是因为学到了一些可预测的局部规则。那我给换个更难的训练集,看看谁还能继续牛逼。We remove compressibility by replacing the deterministic subsequence() by a random subsequence of length p-1 over the alphabet a1,a2,...,ap-1. We obtain 2 sets of sequences {(y , ai1,......,aip-1 , y)|1<=i1,i2,...,ip-1<=p-1} and {(x , ai1,......,aip-1 , x)|1<=i1,i2,...,ip-1<=p-1} 。 结果chunker败下阵来,LSTM笑到了最后(此处滑稽脸.jpg)。说明了LSTM的成功根本就不需要local regularities。
——"very long time lags——no local regularities".这个是实验2的极限测试了。在LSTM出现之前还没有循环神经网络的模型能完美通过这个测试。有p+4个可能的输入符号,分别为a1,......,ap ,ap+1=e,ap+2=b,ap+3=x,ap+4=y。我们把a1,......,ap 称为"distractor symbols"。网络模型有p+4个输入,2个输出。训练样本序列从
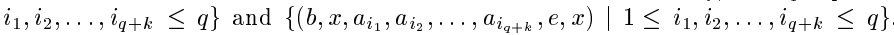 这两个集合中随机选取。随机生成长度q+2的序列前缀,后续元素有9/10的可能性随机生成(不包括b,e,x,y),1/10的可能性为e。误差信号只在序列末尾产生。为了预测最后一个元素,网络模型必须要学会存储第二个符号经过至少q+1个时间步,直到它遇到trigger symbol e。如果训练好的模型在处理10000个连续的随机选择的输入序列时,两个输出单元对于最后元素的预测偏差都小于0.2,那么就认为成功通过测试。模型权重初始化[-0.2,0.2]。参数无bias。h和g门的sigmoid输出分别归一到[-1,1]和[-2,2]。学习率为0.01。最小的time lag设为q+1,因为短的训练序列对长的测试序列的归类无益。当然实验结果肯定是nice,要不也不拿来吹逼了。实验总结时说了"干扰因素的影响“——increasing this frequency decreases learning speed, an effect due to weight oscillations caused by frequently observed input symbols。
这两个集合中随机选取。随机生成长度q+2的序列前缀,后续元素有9/10的可能性随机生成(不包括b,e,x,y),1/10的可能性为e。误差信号只在序列末尾产生。为了预测最后一个元素,网络模型必须要学会存储第二个符号经过至少q+1个时间步,直到它遇到trigger symbol e。如果训练好的模型在处理10000个连续的随机选择的输入序列时,两个输出单元对于最后元素的预测偏差都小于0.2,那么就认为成功通过测试。模型权重初始化[-0.2,0.2]。参数无bias。h和g门的sigmoid输出分别归一到[-1,1]和[-2,2]。学习率为0.01。最小的time lag设为q+1,因为短的训练序列对长的测试序列的归类无益。当然实验结果肯定是nice,要不也不拿来吹逼了。实验总结时说了"干扰因素的影响“——increasing this frequency decreases learning speed, an effect due to weight oscillations caused by frequently observed input symbols。
实验3,noise and signal on same channel。
实验4,adding problem。处理离散表示的连续值的时延问题。
实验5,multiplication problem
实验6,temporal order
>>作者本人所阐述的LSTM的局限性:
Reference:
1.《long short term memory》,Hochreiter&Schmidhuber,1997
2. Stanford CS231n
循环神经网络(RNN)的改进——长短期记忆LSTM的更多相关文章
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
- 循环神经网络RNN模型和长短时记忆系统LSTM
传统DNN或者CNN无法对时间序列上的变化进行建模,即当前的预测只跟当前的输入样本相关,无法建立在时间或者先后顺序上出现在当前样本之前或者之后的样本之间的联系.实际的很多场景中,样本出现的时间顺序非常 ...
- 通过keras例子理解LSTM 循环神经网络(RNN)
博文的翻译和实践: Understanding Stateful LSTM Recurrent Neural Networks in Python with Keras 正文 一个强大而流行的循环神经 ...
- 循环神经网络RNN及LSTM
一.循环神经网络RNN RNN综述 https://juejin.im/entry/5b97e36cf265da0aa81be239 RNN中为什么要采用tanh而不是ReLu作为激活函数? htt ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍(转载)
循环神经网络(RNN, Recurrent Neural Networks)介绍 这篇文章很多内容是参考:http://www.wildml.com/2015/09/recurrent-neur ...
- 循环神经网络(RNN, Recurrent Neural Networks)介绍
原文地址: http://blog.csdn.net/heyongluoyao8/article/details/48636251# 循环神经网络(RNN, Recurrent Neural Netw ...
- 从网络架构方面简析循环神经网络RNN
一.前言 1.1 诞生原因 在普通的前馈神经网络(如多层感知机MLP,卷积神经网络CNN)中,每次的输入都是独立的,即网络的输出依赖且仅依赖于当前输入,与过去一段时间内网络的输出无关.但是在现实生活中 ...
- 用纯Python实现循环神经网络RNN向前传播过程(吴恩达DeepLearning.ai作业)
Google TensorFlow程序员点赞的文章! 前言 目录: - 向量表示以及它的维度 - rnn cell - rnn 向前传播 重点关注: - 如何把数据向量化的,它们的维度是怎么来的 ...
- 循环神经网络 RNN
随着科学技术的发展以及硬件计算能力的大幅提升,人工智能已经从几十年的幕后工作一下子跃入人们眼帘.人工智能的背后源自于大数据.高性能的硬件与优秀的算法的支持.2016年,深度学习已成为Google搜索的 ...
随机推荐
- WebGL简易教程(十二):包围球与投影
目录 1. 概述 2. 实现详解 3. 具体代码 4. 参考 1. 概述 在之前的教程中,都是通过物体的包围盒来设置模型视图投影矩阵(MVP矩阵),来确定物体合适的位置的.但是在很多情况下,使用包围盒 ...
- [Spark]Spark-streaming通过Receiver方式实时消费Kafka流程(Yarn-cluster)
1.启动zookeeper 2.启动kafka服务(broker) [root@master kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh con ...
- Nginx篇--最初级用法web
最近很久都没有写博客了,一来主要是时间不够每天回到家都接近晚上11点了,但是以后每天还是保证一篇随笔.好用来整理总结自己的知识. web服务器很有多例如:Apache nginx tengine li ...
- CSPS模拟 91
T1 sz最多根号种 T2 没计算内存,水过了..CSPS这样的话要爆零的qaq T3 感谢miku带我重学ST表%%%%%
- js设置Date
function getDate (yyyy, MM, dd) { let t = new Date() t.setFullYear(yyyy) t.setMonth(Number(MM) - 1) ...
- python经典面试算法题4.1:如何找出数组中唯一的重复元素
本题目摘自<Python程序员面试算法宝典>,我会每天做一道这本书上的题目,并分享出来,统一放在我博客内,收集在一个分类中. [百度面试题] 难度系数:⭐⭐⭐ 考察频率:⭐⭐⭐⭐ 题目描述 ...
- java-optional-快速使用-教程
前言: 在公司中开发项目时碰到一个从Java8引入的一个Optional类,以前jdk版本使用的比较低,没有使用过,于是我在网上浏览了一些文档写篇文章学习总结一下,希望没有用过的朋友们都能够快速学习到 ...
- 013.Kubernetes二进制部署worker节点Nginx实现高可用
一 Nginx代理实现kube-apiserver高可用 1.1 Nginx实现高可用 基于 nginx 代理的 kube-apiserver 高可用方案. 控制节点的 kube-controller ...
- [WPF] Caliburn Micro学习二 Infrastructure
Caliburn Micro学习一 Installation http://blog.csdn.net/alvachien/article/details/12985415 Step 1. 无论是通过 ...
- Spring框架学习笔记(7)——Spring Boot 实现上传和下载
最近忙着都没时间写博客了,做了个项目,实现了下载功能,没用到上传,写这篇文章也是顺便参考学习了如何实现上传,上传和下载做一篇笔记吧 下载 主要有下面的两种方式: 通过ResponseEntity实现 ...