重新整理 mysql 基础篇————— 介绍mysql日志[二]
前言
对于后端开发来说,打交道最多的应该是数据库了,因为你总得把东西存起来。
或是mongodb或者redis又或是mysql。然后你发现一个问题,就是他们都有日志系统,那么这些日志用来干什么的呢?
举两个例子,回滚和同步。
回滚,这里的回滚是比如说一条语句增加了1,然后再减一吗?这里的回滚操作并不是这样的。
比如说我要更新一条语句,update test set a=1 where b=2,这样的语句,如果这条语句需要回滚,那么操作就应该是在执行前,先查询这条数据进行保存,如果执行完毕需要回滚,那么就直接把原来那条语句写回去。
又比如说,你的数据库要还原到一个小时前,那么你可以把2个小时前的备份拿出来,然后运行前两个小时到前一个小时的日志文件,那么这个时候就相当于回到了一个小时前了。
同步,比如说主从同步了,这样老生常谈的了,一般通过事务日志来同步。
总之,有了日志,那么可以帮我们实现很多功能的了。
那么mysql 在innodb 引擎下,有两个日志非常重要,那就是redo log(重做日志)和 binlog(归档日志)日志。
如果没有这两个日志,应该没啥人敢用mysql的了,因为这两个日志使用了保证mysql的数据完整性的,如果一个数据库连完整性都不能保证,那么是非常危险的。
正文
redo log
首先看下redo log,这个是什么呢? 这个是innodb存储引擎的日志。
说一个它的功能哈,前文提及到存储引擎就相当于我们操作系统的文件系统。
那么问题来了,我们的文件系统是有缓存的,比方说我们写入一个文件,当我们调用函数的时候,不会直接写入,而是写入缓存去,而后又文件系统自己判断啥时候应该写入进去。
判断啥时候应该写入进去,其中有一个标准就是这次要写入缓存的时候,判断缓存是否能够装的下,如果装不下,那么先写入文件,清除缓存,然后再写入缓存。
第二个判断标准就是根据时间某一段时间后进行写入。
同样存储引擎也要为这一段事情操心啊。如果我们更新一条语句,存储引擎就直接给我们操作正在存储数据的地方,那效率可想而知。
所以说,存储引擎就想到一个方法,把更新记录记录到redo log 中,等redo log 快写满,然后就操作到磁盘,或等空闲时间更新进去。
写完redo log 之后,就会告诉执行器,执行完毕了。这个时候我们的应用程序得到更新成功的回调。
如果单纯只写入redo log是不行的,因为存储过程不仅要写,还要读啊,如果写完redo log 通知我们的应用程序更新成功,这个时候还没写入到数据文件,那么我们的应用程序去读的时候就读到了旧的数据。
那么这个时候,存储引擎是这么干的。 反正你给我查询的时候要先查询内存,内存中没有才去查询数据文件。那么存储引擎,先更新到内存中,然后更新到redo log。这样对于存储引擎外部来说,是更新了的,毕竟对于外部来说存储引擎是一个整体。
这就是MySQL里经常说到的WAL技术,WAL的全称是Write-Ahead Logging。
那么这个redo log 是一个什么样的机制呢?难道就一直记录到一个文件中,然后当要写入数据文件的时候,全部写入,然后删除?
如果这么干效率自然是低了。redo log的机制是这样的。
redo log 是由四个文件组成,每个文件大小为1G左右,这个都是可以设置的。
有两个参数,分别为checkpoint 和 write pos。
write pos 是当前记录的位置。checkpoint 是当前写入到数据文件的位置。
比如说:
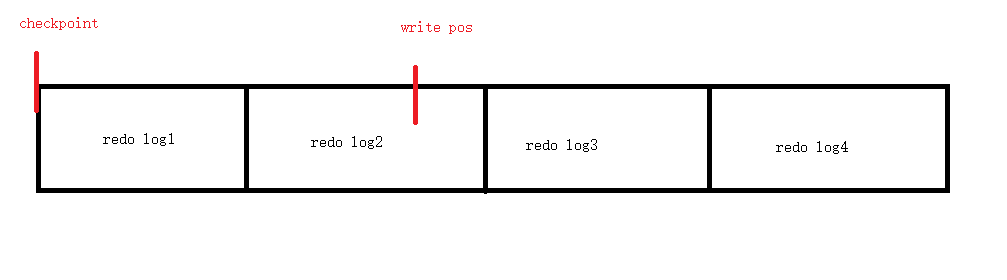
一开始的时候write pos 写的了第二个文件的问题,如果为位置1000。
这个时候还没有去正在写入数据文件,那么这个时候checkpoint 位置就是0。要往数据文件中写入数据的部分就是checkpoint 到 write pos这一段区间,也就是0-1000位置。
那么这个时候存储引擎感觉可以更新了,然后开始写入到正在的数据文件中,那么这个时候开始checkpoints 开始往右移动,假设更新800条。
那么就到了下面这个位置:
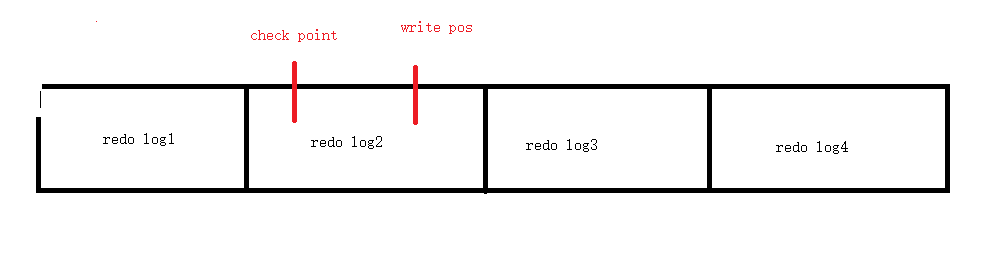
这个时候存储引擎感觉比较忙了,那么就更新800条后,继续接执行器的任务,那么write pos 往右继续移动。
那么这个时候就有一个问题出现,比如说文件大小不变,write pos 一直往右移动,这样会超出啊。
那么这个时候write pos 发现自己到了末尾,人家又从第一个开始写,覆盖写入。
如下:
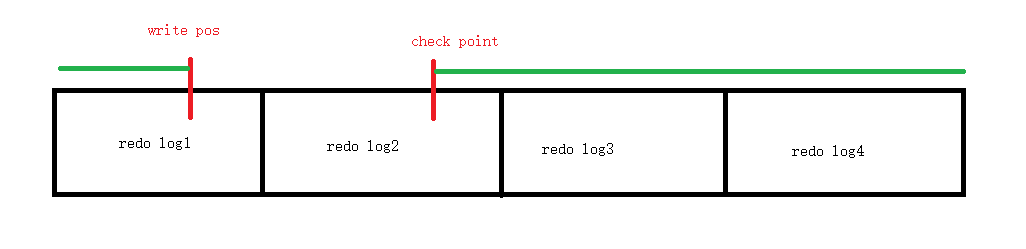
绿色横线部分是要更新到数据文件部分。
redo log 还有一个重要的作用,保证数据正在的写入到数据文件中。
比如说这个时候正在写入数据文件,然后数据库异常重启了,这里理解异常重启,简单点理解就是内存都没了。
那么我们知道写入文件是有缓存的,如果写入到一半异常了,那么数据其实是丢了的。
有了redo log之后,只有数据文件flush了,那么这个时候checkpoint才开始偏移,否则就如果异常了内存没了,那么继续覆盖更新,因为checkpoint 没有变化,那么还是从原来那个异常前的位置开始同步。
那么问题来了,这时候就会想,数据文件是文件,redo log也是文件啊。如果写入的时候在缓存区,然后宕机这个时候也没了啊。
没错,的确有这个问题,这个时候为了数据安全,redo log直接不使用缓存区。
redo log用于保证crash-safe能力。innodb_flush_log_at_trx_commit这个参数设置成1的时候,表示每次事务的redo log都直接持久化到磁盘。
binlog
binlog 是每个mysql都有的,而不是存储引擎的东西,属于mysql 的server 层的东西。
对比一下binlog 和 redo log。
这两种日志有以下三点不同。
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
一条更新语句在innodb引擎下的更新过程:
1. 执行器先找引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
2. 执行器拿到引擎给的行数据,把这个值加上1,比如原来是N,现在就是N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
3. 引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。
4. 执行器生成这个操作的binlog,并把binlog写入磁盘。
5. 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交(commit)状态,更新完成。
这个时候有人可能会问,如果第3步骤先更新到内存,这个时候要是读取操作而之后redo log没有写入就宕机怎么办?因为是写入是有锁的,如果没有提交事务,这个时候有写锁。
这时候就发现一个细节,那就是redo log 一条记录有两个状态一个是prepare,一个是commit状态。
那么为什么要两个状态呢?
我们知道mysql 主从,其实是通过binlog 一条一条发送给从数据库,让从数据库执行binlog里面的操作。
假设没有这两个状态。
假如innodb 写入redo log之后呢,这个时候数据库突然宕机了,这个时候redo log 是有的记录的,这个时候binlog 没有记录。
那么innodb 通过redo log 进行写入到数据文件后,binlog 依然没有这一条记录。那么从库就少了一条操作了。
这个时候主从永远不可能一致。
如果有了两个状态,数据库重启后,innodb存储引擎还是会通知binlog。这时候两个状态就保证了binlog里面的数据完整性。
那么这个时候又会问了,假如上面第四步执行了,第五步没有执行怎么办?比如宕机了。
是啊,这个时候bin log 中有记录但是redo log没有记录。
那么从库就少了一条操作记录了。
这个时候主从永远不可能一致。同样,我们如果数据库退回到某个时间点,如果binlog 和 redolog不一致的话,同样适用binlog进行回滚一样的会遇到这个问题。
如果有了redo log 的prepare 状态,那么如果数据库重启的时候检测到宕机,这个时候redo log里面prepare 状态的数据就会和binlog里面的数据进行校验,进而进行恢复。
这种有两个状态的提交,叫做两阶段提交。他们起到的作用是如果宕机检测到异常,就会对比恢复。
同样binlog也是文件,同样存在缓存的问题,sync_binlog这个参数设置成1的时候,表示每次事务的binlog都持久化到磁盘。
结
以上只是个人整理,如有错误,望请指点。
下一节事务。
重新整理 mysql 基础篇————— 介绍mysql日志[二]的更多相关文章
- 重新整理 mysql 基础篇————— 介绍mysql[一]
前言 准备整理mysql的基础篇了,前面整理了sql语句序列的的<sql 语句系列(八百章)>,感觉很多用不上,就停下来了,后续还是会继续整理. mysql 基础篇主要是对一些基础进行整理 ...
- 【目录】mysql 基础篇系列
随笔分类 - mysql 基础篇系列 mysql 开发基础系列22 SQL Model(带迁移事项) 摘要: 一.概述 与其它数据库不同,mysql 可以运行不同的sql model 下, sql m ...
- mysql 基础篇5(mysql语法---数据)
6 增删改数据 -- ********一.增删改数据********* --- -- 1.1 增加数据 -- 插入所有字段.一定依次按顺序插入 INSERT INTO student VALUES(1 ...
- 「MySQL高级篇」MySQL索引原理,设计原则
大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!! 专栏引言 MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段, ...
- 「 MySQL高级篇 」MySQL索引原理,设计原则
大家好,我是melo,一名大二后台练习生,大年初三,我又来充当反内卷第一人了!!! 专栏引言 MySQL,一个熟悉又陌生的名词,早在学习Javaweb的时候,我们就用到了MySQL数据库,在那个阶段, ...
- MySQL基础配置之mysql的默认字符编码的设置(my.ini设置字符编码) - 转载
MySQL基础配置之mysql的默认字符编码的设置(my.ini设置字符编码) MySQL的默认编码是Latin1,不支持中文,那么如何修改MySQL的默认编码呢,下面以设置UTF-8为例来说明. 需 ...
- MySQL基础配置之mysql的默认字符编码的设置(my.ini设置字符编码)
MySQL基础配置之mysql的默认字符编码的设置(my.ini设置字符编码) MySQL的默认编码是Latin1,不支持中文,那么如何修改MySQL的默认编码呢,下面以设置UTF-8为例来说明. 需 ...
- [MySQL实战-Mysql基础篇]-mysql的日志
参考文章: https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html https://dev.mysql.com/doc/ ...
- 《MySQL 基础课程》笔记整理(基础篇)
一.尝试MySQL 1.打开MySQL # 启动MySQL服务 sudo service mysql start # 使用 root 用户登录,这里密码为空,直接回车登录 mysql -u root ...
随机推荐
- 联想R720Y空间问题
由于之前Y空间在启动项中,所以将他关闭,这次想找到他却找不到 备注:因为在解决问题前,没有把图片保存下来,所以下面用一个颜色框挡住,表示之前的效果 第一个问题 在电脑上找到Y空间 百度上很多说在开始中 ...
- maven 中setting.xml
<mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http:/ ...
- 【微信小程序】--bindtap参数传递,配合wx.previewImage实现多张缩略图预览
本文为原创随笔,纯属个人理解.如有错误,欢迎指出. 如需转载请注明出处 在微信小程序中预览图片分为 a.预览本地相册中的图片. b.预览某个wxml中的多张图片. 分析:实质其实是一样的.都是给wx. ...
- python中的的异步IO
asyncio 是干什么的? 异步网络操作 并发 协程 python3.0 时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado pytho ...
- 关于ollydbg的堆栈视图的使用(结合crackme2分析)
在crackme2中我们通过在弹出的窗口处下段然后逐层往用户区回溯,我们利用不断下断点和反复运行程序回溯,其实可以利用Ollydbg的堆栈视图来完成, ollydbg的堆栈视图反映了程序在运行期间函数 ...
- 2020.12.14vj补题
A. Lucky Ticket 题意:就是说4与7是幸运数字,用4和7组成的数字也是幸运数字,问所给数字是不是幸运数字 思路:直接敲 代码: 1 #include<iostream> 2 ...
- FHD 4K 8K分辨率
4K(2160P,即4096×2160的像素分辨率)和8K(4320P,即7,680 × 4,320的像素分辨率)属于UHDTV. FHD是FULL HD(Full High Definition)的 ...
- 3D高清电商购物小图标图片_在线商城三维icon图标素材大全
3D高清电商购物小图标图片_在线商城三维icon图标素材大全
- 什么是NPS 客户净推荐值?
客户忠诚是企业在客户服务方面的最高目标. 客户是否忠诚通过一个问题即可判断,那就是--你会把这家企业推荐给朋友的可能性有多大?这就是著名的NPS指标,本文希望能讲清NPS客户净推荐值是什么,用好客服系 ...
- .NetCore·集成Ocelot组件之完全解决方案
阅文时长 | 11.04分钟 字数统计 | 17672.8字符 主要内容 | 1.前言.环境说明.预备知识 2.Ocelot基本使用 3.Ocelot功能挖掘 4.Ocelot集成其他组件 5.避坑指 ...