Elasticsearch IK分词器
Elasticsearch-IK分词器
一、简介
因为Elasticsearch中默认的标准分词器(analyze)对中文分词不是很友好,会将中文词语拆分成一个一个中文的汉字,所以引入中文分词器-IK。
使用默认
二、安装IK分词器
1.先下载ik分词器
注意 一定要下载和Elastic版本相同的IK分词器
2.我们将ik分词器上传到我们的es的plugins/ik目录下,ik文件夹需要我们自己创建
cd /usr/local/elasticsearch/plugins/ik/
unzip elasticsearch-analysis-ik-XX.zip
# windos下安装也是一样的操作
3.重启
重启的时候在日志中就可以看到关于IK分词器已经被加载进去了

三、测试分词器
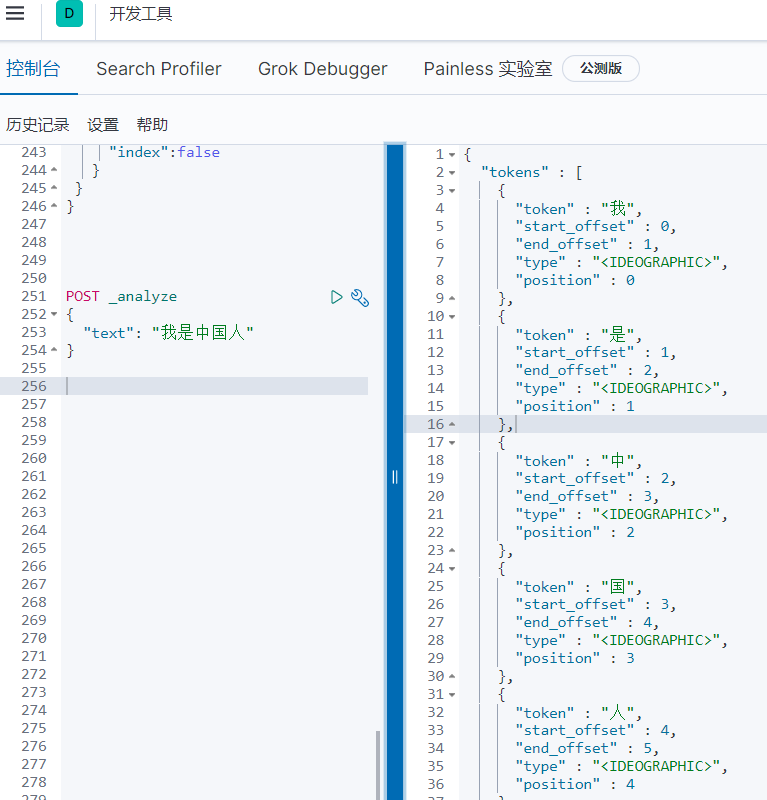
1.ik_smart
会做最粗粒度的拆分,比如会将“我是中国人”拆分为我、是、中国人。
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
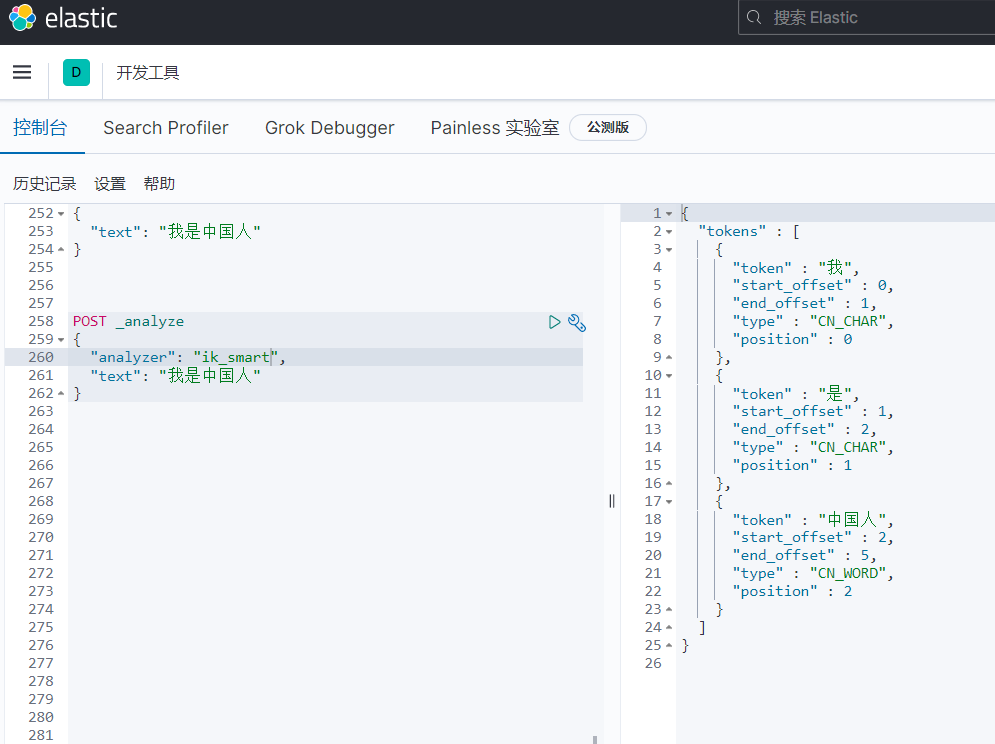
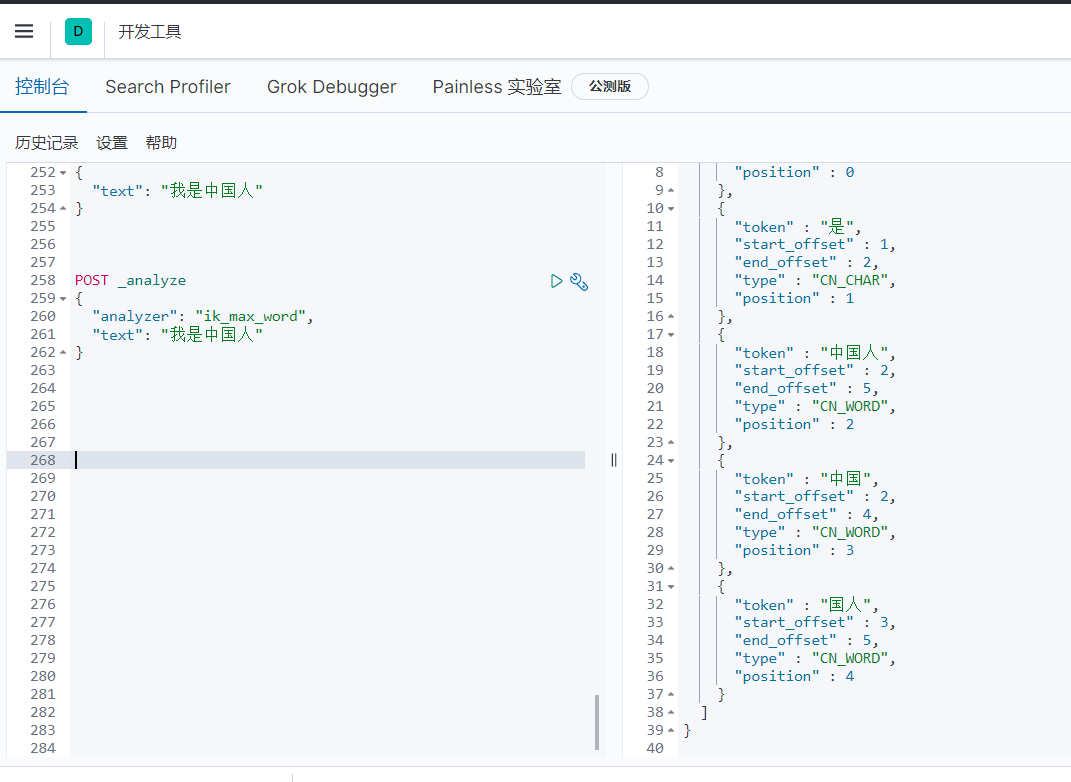
2.ik_max_word
会将文本做最细粒度的拆分,比如会将“我是中国人”拆分为“我、是、中华、中国人、中国、国人
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
四、自定义词库
使用场景
在利用ik分词的过程中,当ik的分词规则不满足我们的需求了,这个时候就可以利用ik的自定义词库进行匹配,比如最火的常用的网络用语;我们输入乔碧罗殿下正常的情况下,是不会识别整个词语的,返回的都是分开的。我们识别整个词语就需要自定义词库
1、自定义词库方式一(新建dic文件)
(1)到elasticsearch/plugins中寻找ik插件所在的目录
(2)在ik中的config文件中添加词库
创建目录 mkdir ciku
创建文件 vim test.dic
#编辑test.dic 注意每个词语一行
(3)修改ik配置
vim /**/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
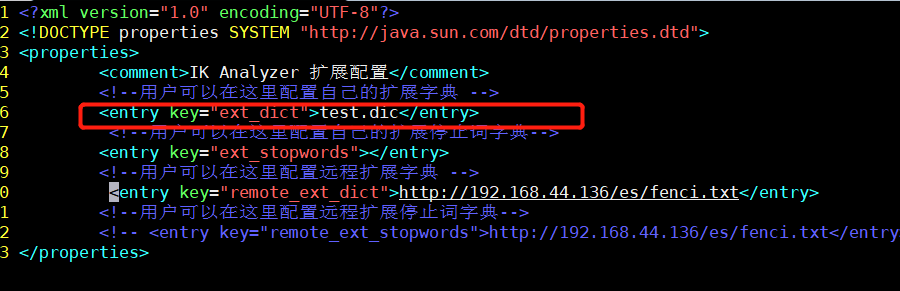
(4)重启ElasticSearch
2、通过Nginx配置自定义词库
(1)安装好nginx,到nginx的html目录下创建分词文件
vim fenci.txt
#每个词语一行
(2)修改ik配置
vim /**/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
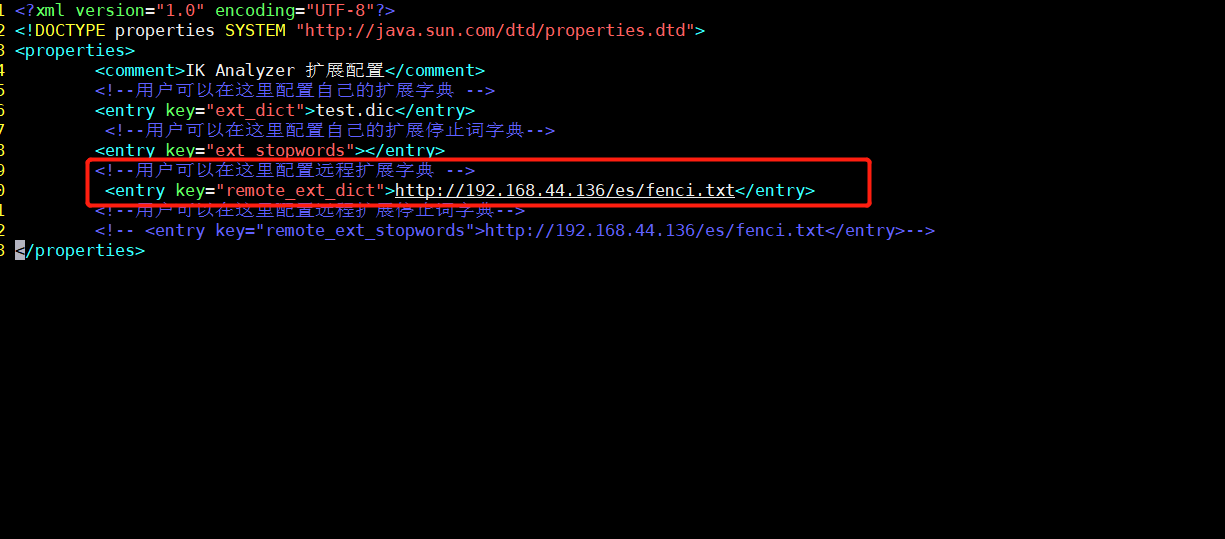
(3)重启ElasticSearch
效果
我们输入乔碧罗殿下正常的情况下,是不会识别整个词语的,返回的都是分开的。当我们在词库文件中写上乔碧罗殿下就会返回下面的效果

Elasticsearch IK分词器的更多相关文章
- SpringBoot整合Elasticsearch+ik分词器+kibana
话不多说直接开整 首先是版本对应,SpringBoot和ES之间的版本必须要按照官方给的对照表进行安装,最新版本对照表如下: (官网链接:https://docs.spring.io/spring-d ...
- 七、Elasticsearch+elasticsearch-head的安装+Kibana环境搭建+ik分词器安装
一.安装JDK1.8 二.安装ES 三个节点:master.slave01.slave02 1.这里下载的是elasticsearch-6.3.1.rpm版本包 https://www.elastic ...
- IK 分词器
目录 IK 分词器-介绍 IK 分词器-安装 环境准备:Maven 安装 IK 分词器 IK 分词器-使用 IK 分词器-介绍 现有问题:ES 默认对中文分词并不友好,实际上是把中文进行了每个字的分词 ...
- Elasticsearch入门之从零开始安装ik分词器
起因 需要在ES中使用聚合进行统计分析,但是聚合字段值为中文,ES的默认分词器对于中文支持非常不友好:会把完整的中文词语拆分为一系列独立的汉字进行聚合,显然这并不是我的初衷.我们来看个实例: POST ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- Elasticsearch下安装ik分词器
安装ik分词器(必须安装maven) 上传相应jar包 解压到相应目录 unzip elasticsearch-analysis-ik-master.zip(zip包) cp -r elasticse ...
- elasticsearch安装ik分词器(极速版)
简介:下面讲有我已经打包并且编辑过的zip包,你可以在下面下载即可. 1.下载zip包.elasticsearch-analysis-ik-1.8.0.jar下面有附件链接[ik-安装包.zip],下 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
- ElasticSearch(六):IK分词器的安装与使用IK分词器创建索引
之前我们创建索引,查询数据,都是使用的默认的分词器,分词效果不太理想,会把text的字段分成一个一个汉字,然后搜索的时候也会把搜索的句子进行分词,所以这里就需要更加智能的分词器IK分词器了. 1. i ...
随机推荐
- hugo + nginx 搭建博客记录
作为一个萌新Gopher,经常逛网站能看到那种极简的博客,引入眼帘的不是花里胡哨的图片和样式,而是黑白搭配,简简单单的文章标题,这种风格很吸引我.正好看到煎鱼佬也在用这种风格的博客,于是卸载了我的wo ...
- 使用Hugo框架搭建博客的过程 - 部署
前言 完成前期的准备工作后,在部署阶段需要配置服务器或对象存储服务. 对象存储和服务器对比 对象存储平台 国内有阿里云OSS.腾讯COS.又拍云.七牛云等.国外有Github Pages.Netlif ...
- python 15篇 面向对象
1.面向对象编程概念 面向对象是包含面向过程 面向过程编程 买车: 1.4s看车,买车 2.上保险 保险公司 3.交税 地税局 4.交管所 上牌面向对象编程 卖车处: 1.4s 2.保险 3.交税 4 ...
- C语言:3个数排序
#include <stdio.h> int main() { int a,b,c,t; /*定义4个基本整型变量a.b.c.t*/ printf("Please input a ...
- C语言:键盘输入
C语言有多个函数可以从键盘获得用户输入,它们分别是: scanf():和 printf() 类似,scanf() 可以输入多种类型的数据. getchar().getche().getch():这三个 ...
- CF1329F题解
能发现: 1.输出序列与掉落顺序没有任何关系(因为单调性不会被改变). 2.输出的序列 \(h_i\) 最多有一组 \(h_i=h_{i+1}\). 对 2 的证明: 当 \(h_{i+1}\) 与 ...
- svo论文随手记
论文链接:http://rpg.ifi.uzh.ch/docs/ICRA14_Forster.pdf 论文提出了一种半直接单目视觉里程计,在精确性.鲁棒性和速度方面都有较大的优势.将基于特征的方法(包 ...
- Real DOM和 Virtual DOM 的区别?优缺点?
一.是什么 Real DOM,真实DOM, 意思为文档对象模型,是一个结构化文本的抽象,在页面渲染出的每一个结点都是一个真实DOM结构,如下: Virtual Dom,本质上是以 JavaScript ...
- C++11 左值引用和右值引用与引用折叠和完美转发
1.左值与右值 最感性的认识. 当然,左值也是可以在右边的. 左值是可以被修改的,右值不能. 当然取地址也是. 生存周期一般左值会比右值的长,一般右值都计算时产生的无名临时对象,存在时间比较短. 下面 ...
- 在docker for windows建立mssql容器后,ssms连接mssql出现错误号码18456的问题
在docker for windows建立mssql容器后,ssms连接mssql出现错误号码18456的问题 笔者提供一个可能会没考虑到的点. 请检查本机是否安装了mssql!!! 请检查本机的ms ...