golang切片的一些自问自答

你好,我是轩脉刃。这篇是关于go切片的一些问题和回答。
go的切片基本上是代码中使用最多的一种数据结构了,使用这种数据结构有哪些要注意的点,这个是非常必要了解的东西。基本上,以前写的一篇博客 https://www.cnblogs.com/yjf512/p/9531282.html 就说的很清楚了。这里再深挖一些。
问题:go的切片数据结构是什么样子的?
切片是有可能在编译器就被内联的,而如果在编译器没有被内联,进入运行期,就是直接使用SliceHeader数据结构。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
这三个字段分别表示指针,长度,容量。
问题:为什么在初始化slice的时候尽量补全cap
当我们要创建一个slice结构,并且往slice中append元素的时候,我们可能有两种写法来初始化这个slice。
方法1:
package main
import "fmt"
func main() {
arr := []int{}
arr = append(arr, 1,2,3,4, 5)
fmt.Println(arr)
}
方法2:
package main
import "fmt"
func main() {
arr := make([]int, 0, 5)
arr = append(arr, 1,2,3,4, 5)
fmt.Println(arr)
}
方法2相较于方法1,就只有一个区别:在初始化[]int slice的时候在make中设置了cap的长度,就是slice的大小。
这两种方法对应的功能和输出结果是没有任何差别的,但是实际运行的时候,方法2会比少运行了一个growslice的命令。
这个我们可以通过打印汇编码进行查看:
方法1:

方法2:
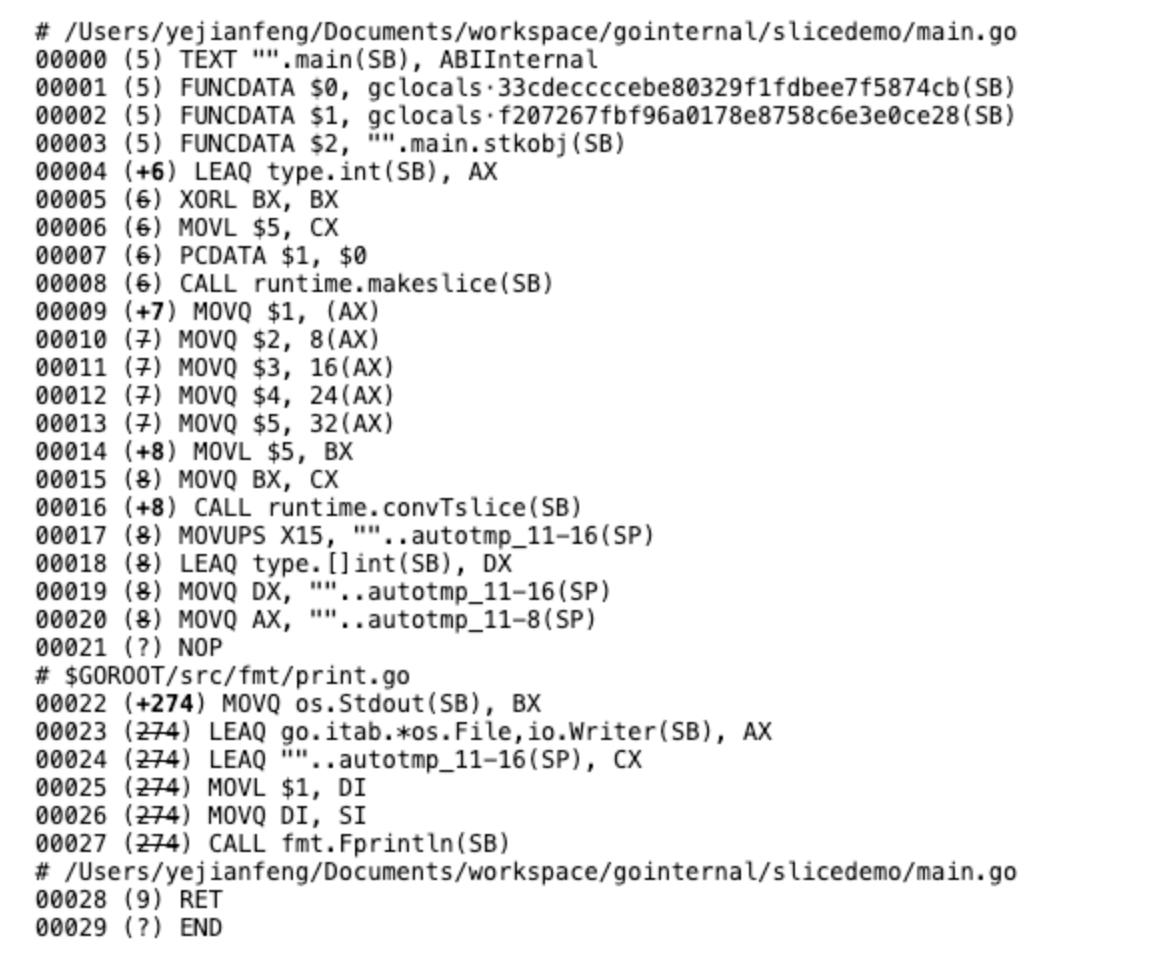
我们看到方法1中使用了growsslice方法,而方法2中是没有调用这个方法的。
这个growslice的作用就是扩充slice的容量大小。就好比是原先我们没有定制容量,系统给了我们一个能装两个鞋子的盒子,但是当我们装到第三个鞋子的时候,这个盒子就不够了,我们就要换一个盒子,而换这个盒子,我们势必还需要将原先的盒子里面的鞋子也拿出来放到新的盒子里面。所以这个growsslice的操作是一个比较复杂的操作,它的表现和复杂度会高于最基本的初始化make方法。对追求性能的程序来说,应该能避免尽量避免。
具体对growsslice函数具体实现同学有兴趣的可以参考源码src的 runtime/slice.go 。
当然,我们并不是每次都能在slice初始化的时候就能准确预估到最终的使用容量的。所以这里使用了一个“尽量”。明白是否设置slice容量的区别,我们在能预估容量的时候,请尽量使用方法2那种预估容量后的slice初始化方式。
问题:如果不设置cap,make slice的时候,创建的cap为多大?
如果不设置cap,不管是使用make,还是直接使用[]slice 进行初始化,编译器都会计算初始化所需的空间,使用最小化的cap进行初始化。
a := make([]int, 0) // cap 为0
a := []int{1,2,3} // cap 为3
可以从ssa看出

问题:slice什么时候决定扩张?
之前写过一篇文章 https://www.cnblogs.com/yjf512/p/10714792.html 里面得出的结论就是slice在编译期就决定是否要调用growslice。
这个逻辑是正确的。
编译器在ssa的时候 对于append是会转换为 OAPPEND(cmd/compile/internal/typecheck/universe.go) 。而在 cmd/compile/internal/ssagen/ssa.go 中,对其进行判断。
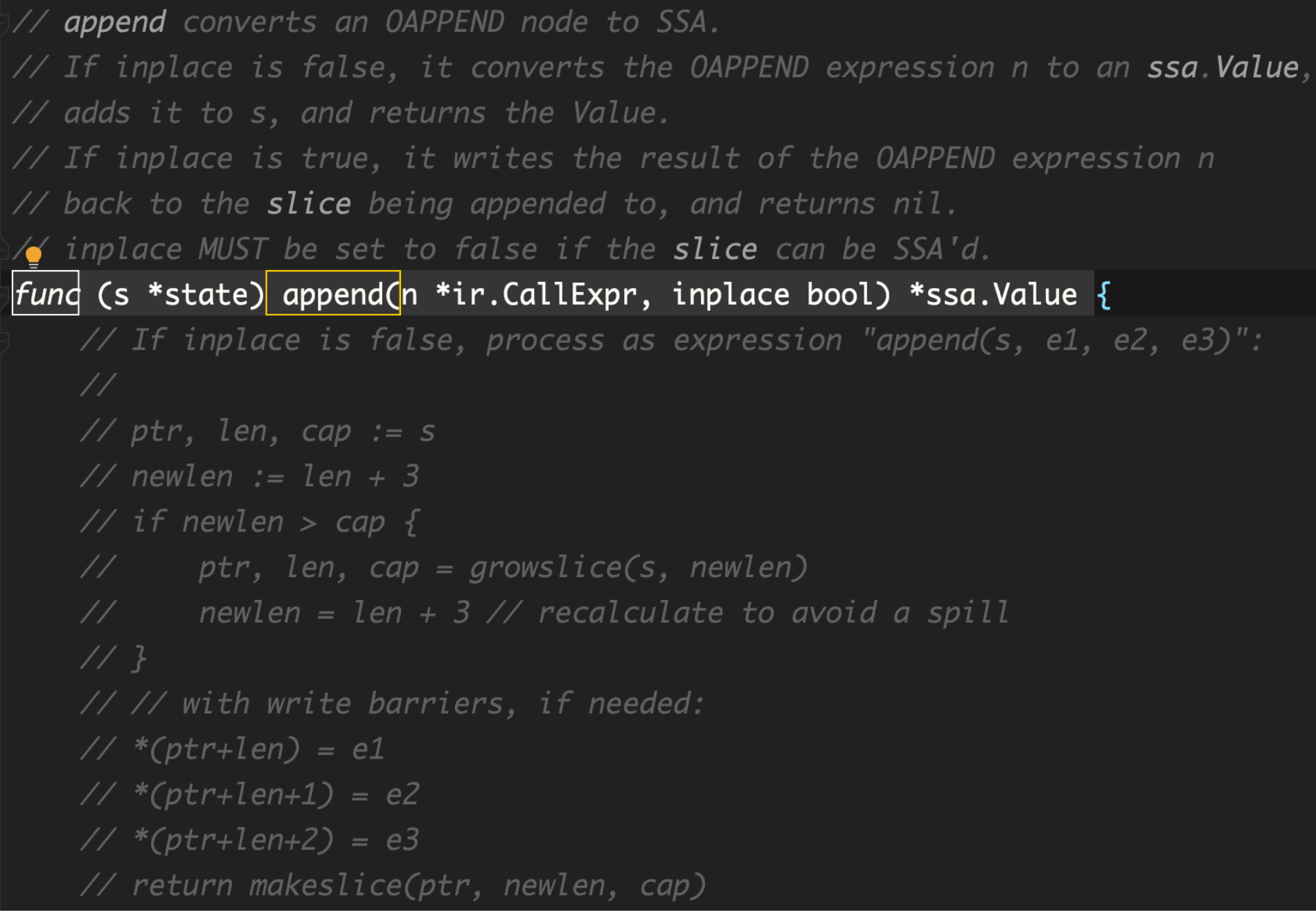
目前还看不懂下面append下面的逻辑,不过基于这个注释,能了解到这里growslice的逻辑。比较扩容前后大小,如果原先cap小于扩容后需要cap,就growslice。
总结
琢磨了四个关于切片的问题:
问题:go的切片数据结构是什么样子的?
问题:为什么在初始化slice的时候尽量补全cap?
问题:如果不设置cap,make slice的时候,创建的cap为多大?
问题:slice什么时候决定扩张?
golang切片的一些自问自答的更多相关文章
- golang 数组的一些自问自答
所有代码基于Go-1.17.一些研究Go数组的自问自答,可以考虑作为面试题. 问题:静态存储区是什么?和堆/栈有什么区别? 回答: 可以参考下列图 堆上存放new产生的大块内存 栈上存放的是程序运行的 ...
- [python]自问自答:python -m参数?
python -m xxx.py 作用是:把xxx.py文件当做模块启动 但是我一直不明白当做模块启动到底有什么用.python xxx.py和python -m xxx.py有什么区别! 自问自答: ...
- 自问自答之VR遐想
先让我组织一下语言,作为表达能力超弱的战五渣来讲,归纳总结什么的最要命了. 我可以给你分析个1到N条出来,但是一般来讲没什么顺序,想到什么就说什么.而且我属于线性思维,有一个引子就可以按着话头一步步发 ...
- [python]自问自答:python -m参数? (转)
python -m xxx.py 作用是:把xxx.py文件当做模块启动但是我一直不明白当做模块启动到底有什么用.python xxx.py和python -m xxx.py有什么区别! 自问自答: ...
- [python]自问自答:python -m参数? (转) ( python2.7 版本 )
原文地址: http://www.cnblogs.com/xueweihan/p/5118222.html python -m xxx.py 作用是:把xxx.py文件当做模块启动 但是我一直不明白当 ...
- css自问自答(二)
css自问自答(二) 7.掌握定位的一些属性 position 和 display 属性,以及如何浮动(float)和清除(clear)元素,z-index属性 三个属性控制: position 属性 ...
- css自问自答(一)
css自问自答(一) 1.块级元素和行内元素特性与区别? 块级:display:block <div>.<p>.<h1>...<h6>.<ol&g ...
- vue 源码自问自答-响应式原理
vue 源码自问自答-响应式原理 最近看了 Vue 源码和源码分析类的文章,感觉明白了很多,但是仔细想想却说不出个所以然. 所以打算把自己掌握的知识,试着组织成自己的语言表达出来 不打算平铺直叙的写清 ...
- 区块链自问自答 day1
区块链自问自答 day1 简要介绍区块链是什么? 区块链(Blockchain)是一种对等网络下的分布式数据库系统 数据结构中的单向链表是通过每个节点包含一个节点的指针实现"链" ...
随机推荐
- C语言中的位段----解析
有些信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位. 例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可. 为了节省存储空间并使处理简便,C语言又提供了一种数据结 ...
- Hadoop入门 完全分布式运行模式-准备
目录 Hadoop运行环境 完全分布式运行模式(重点) scp secure copy 安全拷贝 1 hadoop102上的JDK文件推给103 2 hadoop103从102上拉取Hadoop文件 ...
- 自然语言式parsing
got NUM(1) Is NUM(1) an expr? Is NUM(1) a term? Is NUM(1) a number? is_term got -(-) -(-) was back i ...
- A Child's History of England.34
'Prince!' said Fitz-Stephen, 'before morning, my fifty and The White Ship shall overtake [超过, 别和take ...
- ache
ache和pain可能没啥差别,头疼和头好痛都对.从词典来看,有backache, bellyache, earache, headache, heartache, moustache/mustach ...
- 数据存储SharePreferences详解
1.SharedPreferences存储 SharedPreferences时使用键值对的方式来存储数据的,也就是在保存一条数据时,需要给这条数据提供一个对应的键,这样在读取的时候就可以通过这个键把 ...
- GO并发相关
锁的使用 注意要成对,重点是代码中有分支或者异常返回的情况,这种情况要在异常返回前先释放锁 mysqlInstanceLock.Lock() slaveHostSql := "show sl ...
- Hadoop生态圈学习-1(理论基础)
一.大数据技术产生的背景 1. 计算机和信息技术(尤其是移动互联网)的迅猛发展和普及,行业应用系统的规模迅速扩大(用户数量和应用场景,比如facebook.淘宝.微信.银联.12306等),行业应用所 ...
- InnoDB学习(四)之RedoLog和UndoLog
BinLog是MySQL Server层的日志,所有的MySQL存储引擎都支持BinLog.BinLog可以支持主从复制和数据恢复,但是对事务的ACID特性支持比较差.InnoDB存储引擎引入Redo ...
- 【web】docker复现环境踩坑
在先知看到有师傅发了个学习 P 牛的代码审计的文章,在 github 上下下来复现环境,结果 docker 各种问题,气死 安装 docker-compose:pip install -i https ...