mysql order by语句流程是怎么样的
order by流程是怎么样的
注意点:
select id, name,age,city from t1 where city='杭州' order by age limit 1000;
order by 和limit一般共同出现使用。他的流程是什么呢?
首先依然会走连接器,分析器,优化器选择索引。查看sql语句执行计划,一定要多使用explain sql语句。能发现很多事情。
排序避免全表扫描,我们排序字段需要尽可能有索引,explain sql语句由
Using filesort字段,代表需要使用排序。排序需要先读出数据,读出的数据需要在内存里面开辟一个空间来存数据。这块空间叫
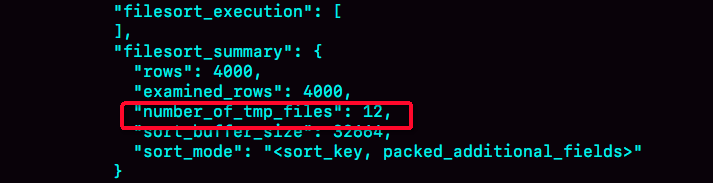
sort_buffer,由参数sort_buffer_size控制。如果排序数据量过大。超过了自己sort_buffer空间的大小,怎么办?这是就会用额外的磁盘临时文件来辅助排序。这种情况下,性能就会非常低。通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files 中看到是否使用了临时文件。12代表使用了12个磁盘文件,这种外部排序一般使用归并排序算法。
sort_buffer空间的数据,每行长度也有限制,排序后查询的结果字段太多,就会存在放不下,这种情况下,mysql会使用rowid排序算法。这个算法在sort_buffer空间不用取出全部字段,只取排序字段age。排序后查询limit限制的100。然后根据主机id再去索引树上取得其他字段的值。
排序过程中需要排序这个过程,如果我们索引字段上排序,索引本来就有顺序,就不需要排序了。这样explain里面就没有user filesort关键字了。
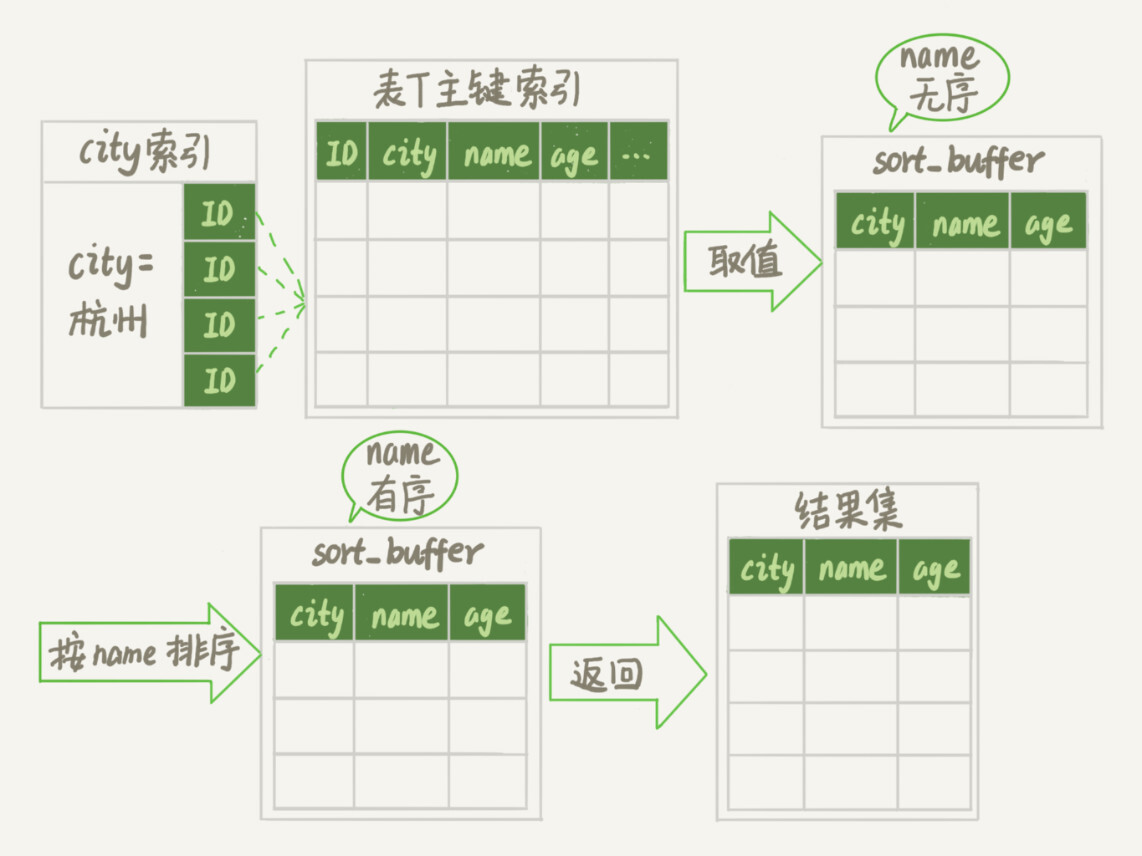
排序流程:
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;按照排序结果取前 1000 行返回给客户端。
mysql order by语句流程是怎么样的的更多相关文章
- mysql ORDER BY语句 语法
mysql ORDER BY语句 语法 作用:用于对结果集进行排序. 语法:顺序:SELECT * from 表名 ORDER BY 排序的字段名 倒序:SELECT * from 表名 ORDER ...
- mysql group by语句流程是怎么样的
group by流程是怎么样的 注意点: select id%10 as m, count(*) as c from t1 group by m; group by是用于对数据进行分组,我们排序用到了 ...
- MySQL——优化ORDER BY语句
本篇文章我们将了解ORDER BY语句的优化,在此之前,你需要对索引有基本的了解,不了解的朋友们可以先看一下我之前写过的索引相关文章.现在让我们开始吧. MySQL中的两种排序方式 1.通过有序索引顺 ...
- Mysql常用sql语句(7)- order by 对查询结果进行排序
测试必备的Mysql常用sql语句系列 https://www.cnblogs.com/poloyy/category/1683347.html 前言 通过select出来的结果集是按表中的顺序来排序 ...
- Mysql 常用 SQL 语句集锦
Mysql 常用 SQL 语句集锦 基础篇 //查询时间,友好提示 $sql = "select date_format(create_time, '%Y-%m-%d') as day fr ...
- mysql常用操作语句
mysql常用操作语句 1.mysql -u root -p 2.mysql -h localhost -u root -p database_name 2.列出数据库: 1.show datab ...
- Mysql 常用 SQL 语句集锦 转载(https://gold.xitu.io/post/584e7b298d6d81005456eb53)
Mysql 常用 SQL 语句集锦 基础篇 //查询时间,友好提示 $sql = "select date_format(create_time, '%Y-%m-%d') as day fr ...
- MYSQL随机抽取查询 MySQL Order By Rand()效率问题
MYSQL随机抽取查询:MySQL Order By Rand()效率问题一直是开发人员的常见问题,俺们不是DBA,没有那么牛B,所只能慢慢研究咯,最近由于项目问题,需要大概研究了一下MYSQL的随机 ...
- 23个MySQL常用查询语句
23个MySQL常用查询语句 一查询数值型数据: SELECT * FROM tb_name WHERE sum > 100; 查询谓词:>,=,<,<>,!=,!> ...
随机推荐
- T-SQL - query02_查看数据库信息|查看服务器名称|查看实例名
时间:2017-09-29 编辑:byzqy 本篇记录几个查询数据库信息的 T-SQL 语句: 查看数据库信息 查看服务器名称 查看实例名 文件:SQLQuery2.sql /* 说明: SQLQue ...
- APP 兼容性测试之云测平台体验
前言 兼容性测试主要通过人工或自动化的方式,在需要覆盖的终端设备上进行功能用例执行,查看软件性能.稳定性等是否正常. 对于需要覆盖的终端设备,大型互联网公司,像BAT,基本都有自己的测试实验室,拥有大 ...
- 【Spring 持久层】Spring 与 Mybatis 整合
持久层整合总述 1.Spring 框架为什么要与持久层技术进行整合? JavaEE开发需要持久层进行数据库的访问操作 JDBC.Hibernate.MyBatis 进行持久开发过程存在大量的代码冗余 ...
- CSS实用技巧(中)
前言 我们经常使用CSS,但是却不怎么了解CSS,本文主要对vertical-align.BFC.position中开发过程不怎么注意的特性进行简要总结,从本文中,你将了解到以下内容: vertica ...
- Django——数据库连接配置
配置settings.py : DATABASES = { 'default': { #default表示默认,也可以指定app 'ENGINE': 'django.db.backends.mysql ...
- Java链表练习题小结
链表 链表(Linked List)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer).一个链表节点至少包含一个 数据域和 ...
- Excel中怎么快速选中区域
连续的表格选定 一张表格中会有不同的部分,若想选择某一个区域的数据的时候我们可以使用快捷键Ctrl+A,这是需要先选中第一个单元格,接着点击Ctrl+A即可选中连续的单元格. 汇总后需要汇 ...
- python爬取疫情数据存入MySQL数据库
import requests from bs4 import BeautifulSoup import json import time from pymysql import * def mes( ...
- symfony2 数据库原生查询
1. 数组,没有键名 但只查询出第一个结果 $conn = $this->getDoctrine()->getConnection(); $data = $conn->fetchAr ...
- Linux系列(14) - grep
简述 grep是在文件当中匹配符合条件的字符串,作用是查找文件内容 格式 grep [选项] 字符串 文件名 选项 -i:忽略大小写 -v:排除指定字符串 -n:显示行号 例子 grep " ...