经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
前言:
目标检测的预测框经过了滑动窗口、selective search、RPN、anchor based等一系列生成方法的发展,到18年开始,开始流行anchor free系列,CornerNet算不上第一篇anchor free的论文,但anchor freee的流行却是从CornerNet开始的,其中体现的一些思想仍值得学习。
看过公众号以往论文解读文章的读者应该能感觉到,以往论文解读中会有不少我自己的话来表述,文章写得也很简练。但这篇论文的写作实在很好,以至于这篇解读文章几乎就是对论文的翻译,几乎没有改动。
论文提出了 CornerNet,这是一种新的目标检测方法,我们使用单个卷积神经网络将对象边界框检测为一对关键点,即左上角和右下角。 通过将对象检测为成对的关键点,我们无需设计一组在先前单级检测器中常用的锚框。 除了我们的新范式外,我们还引入了corner pooling,这是一种新型的池化层,可帮助网络更好地定位角点。
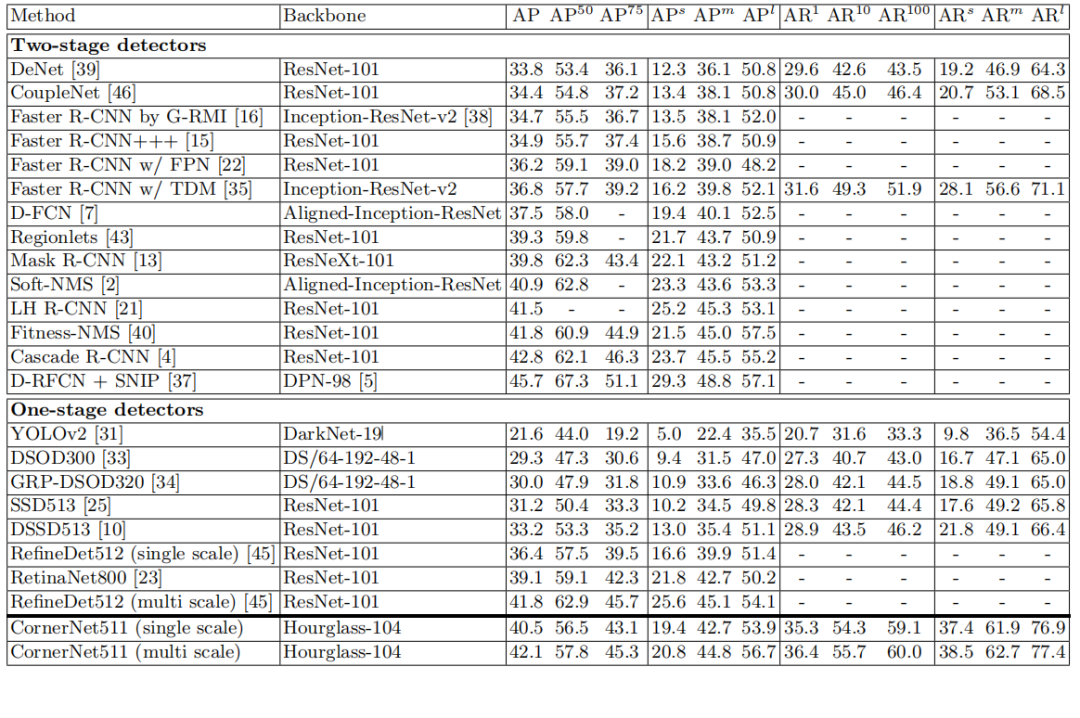
实验表明,CornerNet 在 MS COCO 上实现了 42.1% 的 AP,优于所有现有的单级检测器。
论文:https://arxiv.org/abs/1808.01244v2
代码:https://github.com/umichvl/CornerNet
关注公众号CV技术指南,及时获取更多计算机视觉的内容。
论文出发点|anchor box的缺陷
目标检测中SOTA模型中一个常见组成部分是锚框,它是各种大小和纵横比的框,用作检测候选框。Anchor box广泛应用于one-stage检测器中,可以在效率更高的情况下获得与two-stages检测器极具竞争力的结果。one-stage检测器将锚框密集地放置在图像上,并通过对锚框进行评分并通过回归细化其坐标来生成最终的框预测。
但是使用锚框有两个缺点。
首先,我们通常需要一组非常大的锚框,例如 在 DSSD 中超过 40k,在 RetinaNet 中超过 100k。这是因为检测器被训练来对每个锚框是否与一个ground truth框充分重叠进行分类,并且需要大量的anchor box来确保与大多数ground truth框有足够的重叠。结果,只有一小部分锚框会与ground truth重叠; 这会造成正负锚框之间的巨大不平衡并减慢训练速度。
其次,锚框的使用引入了许多超参数和设计选择。 这些包括多少个box、多大scale和多大aspect ratios。 这种选择主要是通过临时启发式进行的,当与多尺度体系结构相结合时会变得更加复杂,多尺度体系即单个网络在多个分辨率下进行单独预测,每个尺度使用不同的特征和自己的一组锚框。
methods
受到 Newell 等人提出的关联嵌入方法的启发。谁在多人人体姿势估计的背景下检测和分组关键点。论文提出了 CornerNet,这是一种新的one-stage目标检测方法,无需锚框。
我们将一个对象检测为一对关键点——边界框的左上角和右下角。我们使用单个卷积网络来预测同一对象类别的所有实例的左上角的热图、所有右下角的热图以及每个检测到的角的嵌入向量。嵌入用于对属于同一对象的一对角进行分组——网络经过训练以预测它们的相似嵌入。
这种方法极大地简化了网络的输出并消除了设计锚框的需要。
下图说明了方法的整体流程
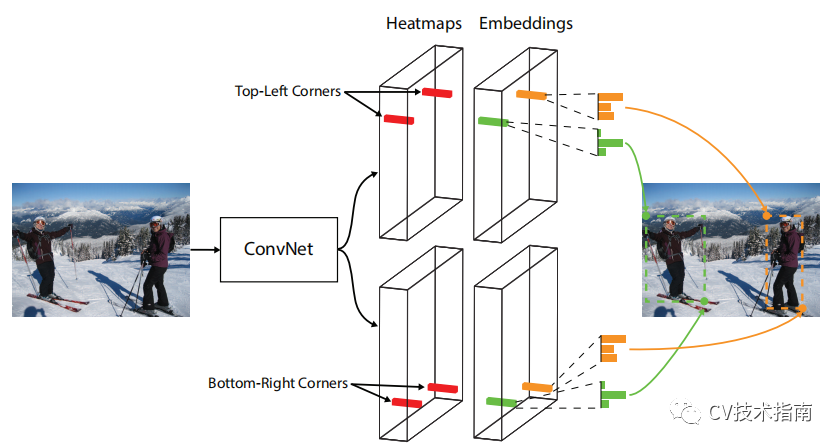

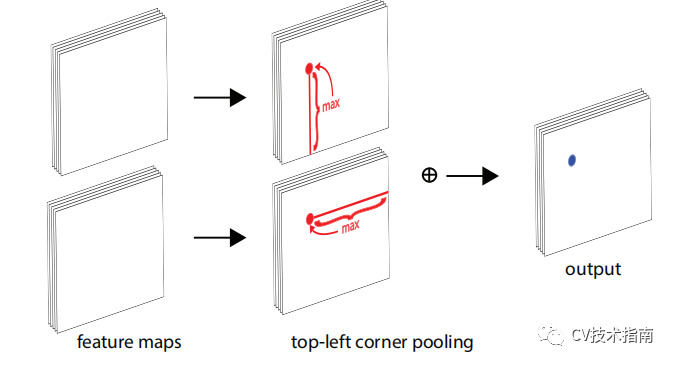
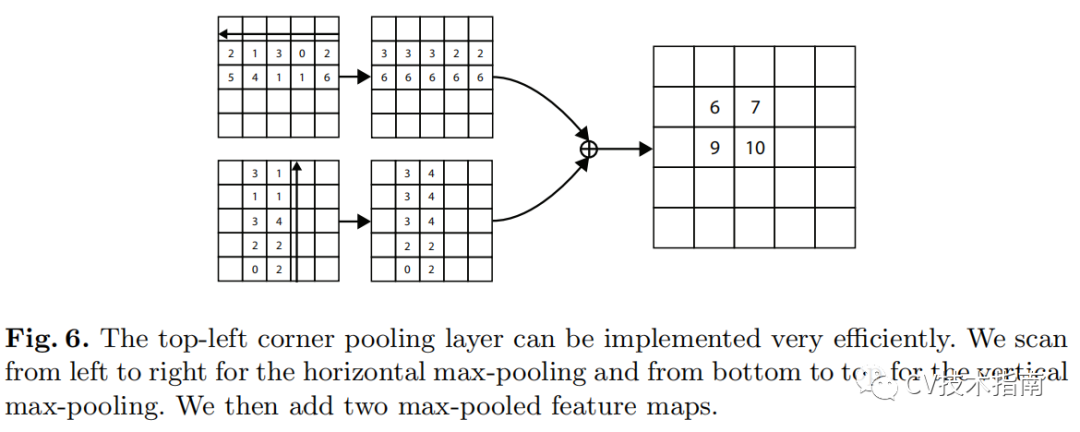
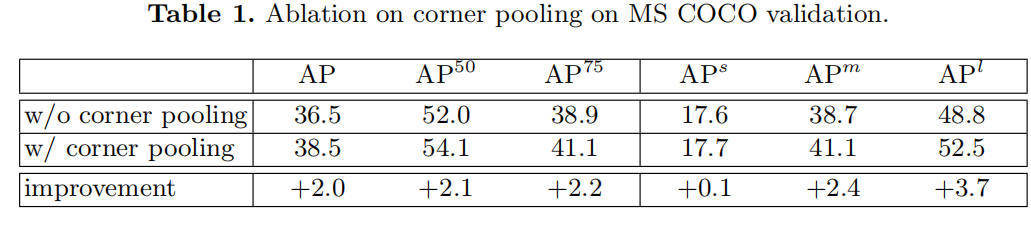
CornerNet 的另一个新颖组件是corner pooling,这是一种新型的池化层,可帮助卷积网络更好地定位边界框的角点。 边界框的角通常在对象之外——考虑圆形的情况以及下面图(中)示例。

在这种情况下,不能基于局部证据来定位角。 相反,要确定像素位置是否有左上角,我们需要水平向右看对象的最上边界,垂直向下看最左边界。 基于这一点,我们提出了corner pooling。
它输入两个特征图; 在每个像素位置,它最大池化第一个特征图右侧的所有特征向量,最大池化第二个特征图正下方的所有特征向量,然后将两个合并的结果加在一起。
我们假设检测角点比边界框中心或提案更有效的两个原因。 首先,一个box的中心可能更难定位,因为它取决于目标的所有 4 个边,而定位一个角取决于 2 个边,因此更容易,对于corner pooling更是如此,它编码了一些关于角的定义的明确的先验知识。 其次,角提供了一种更有效的方法来密集离散框的空间:我们只需要 O(wh) 个角来表示 O(wh)^2 个可能的锚框。
一些细节

整体实现
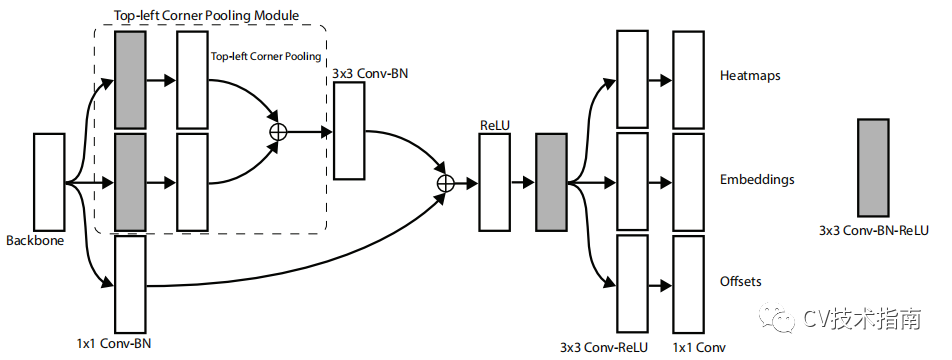
在 CornerNet 中,我们将一个对象检测为一对关键点——边界框的左上角和右下角。卷积网络预测两组热图来表示不同对象类别的角的位置,一组用于左上角,另一组用于右下角。每组热图都有C个通道,C为类别数量(不含背景),每个通道是关于一个类别角点位置的二进制掩码。
该网络还为每个检测到的角点预测一个嵌入向量,使得来自同一对象的两个角点的嵌入之间的距离很小。 为了产生更紧密的边界框,网络还预测偏移量以稍微调整角的位置。 使用预测的热图、嵌入和偏移量,我们应用一个简单的后处理算法来获得最终的边界框。
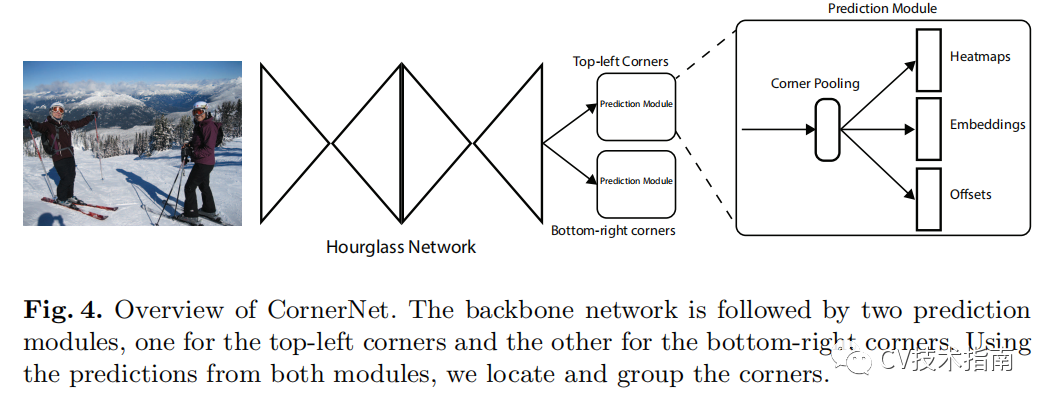
使用沙漏网络作为 CornerNet 的骨干网络。沙漏网络之后是两个预测模块。一个模块用于左上角,而另一个用于右下角。每个模块都有自己的corner pooling模块,用于在预测热图、嵌入和偏移之前从沙漏网络中池化特征。 与许多其他目标检测器不同,我们不使用不同尺度的特征来检测不同尺寸的物体。 我们只将这两个模块应用于沙漏网络的输出。
对于每个Corner,有一个ground truth正位置,所有其他位置都是负位置。 在训练期间,我们不是对负位置进行同等惩罚,而是减少对正位置半径内的负位置的惩罚。 这是因为一对错误的角点检测,如果它们靠近各自的ground truth位置,仍然可以产生一个与ground truth框充分重叠的框。 我们通过对象的大小来确定半径,方法是确保半径内的一对点将生成一个具有至少 t IoU 的边界框,并带有ground truth标注。
Corners分组
使用“pull”损失训练网络对角点进行分组,使用“push”损失来分离角点:
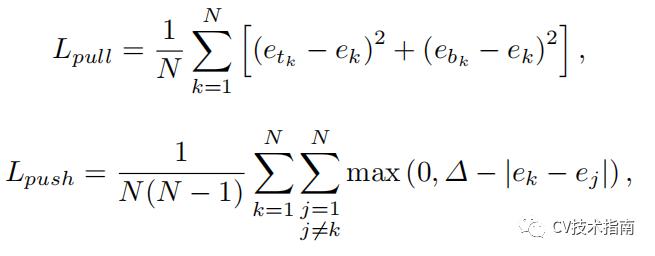
Corner Pooling
预测模块
沙漏网络
CornerNet 使用沙漏网络作为其骨干网络。沙漏网络首先被引入用于人体姿势估计任务。它是一个完全卷积的神经网络,由一个或多个沙漏模块组成。沙漏模块首先通过一系列卷积和最大池化层对输入特征进行下采样。然后通过一系列上采样和卷积层将特征上采样回原始分辨率。由于最大池化层中的细节丢失,因此添加了跳过层以将细节带回上采样特征。沙漏模块在单个统一结构中捕获全局和局部特征。当多个沙漏模块堆叠在网络中时,沙漏模块可以重新处理特征以捕获更高级别的信息。这些特性也使沙漏网络成为目标检测的理想选择。事实上,目前很多检测器已经采用了类似于沙漏网络的网络。
结论
实验表明,CornerNet 在 MS COCO 上实现了 42.1% 的 AP,优于所有现有的单级检测器。
Corner Pooling的消融实验
本文来源于公众号 CV技术指南 的论文分享系列。
欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
在公众号中回复关键字 “技术总结” 可获取以下文章的汇总pdf。

其它文章
经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷
在做算法工程师的道路上,你掌握了什么概念或技术使你感觉自我提升突飞猛进?
经典论文系列 | 目标检测--CornerNet & 又名 anchor boxes的缺陷的更多相关文章
- 经典论文系列 | 缩小Anchor-based和Anchor-free检测之间差距的方法:自适应训练样本选择
前言 本文介绍一篇CVPR2020的论文,它在paperswithcode上获得了16887星,谷歌学术上有261的引用次数. 论文主要介绍了目标检测现有的研究进展.anchor-based和 ...
- 目标检测复习之Anchor Free系列
目标检测之Anchor Free系列 CenterNet(Object as point) 见之前的过的博客 CenterNet笔记 YOLOX 见之前目标检测复习之YOLO系列总结 YOLOX笔记 ...
- 经典论文系列| 实例分割中的新范式-SOLO
前言: 这是实例分割中的一篇经典论文,以往的实例分割模型都比较复杂,这篇论文提出了一个简单且直接的实例分割模型,如何设计这种简单直接的模型且要达到一定的精度往往会存在一些困难,论文中有很多思路或思想值 ...
- 目标检测 1 : 目标检测中的Anchor详解
咸鱼了半年,年底了,把这半年做的关于目标的检测的内容总结下. 本文主要有两部分: 目标检测中的边框表示 Anchor相关的问题,R-CNN,SSD,YOLO 中的anchor 目标检测中的边框表示 目 ...
- Domain Adaptive Faster R-CNN:经典域自适应目标检测算法,解决现实中痛点,代码开源 | CVPR2018
论文从理论的角度出发,对目标检测的域自适应问题进行了深入的研究,基于H-divergence的对抗训练提出了DA Faster R-CNN,从图片级和实例级两种角度进行域对齐,并且加入一致性正则化来学 ...
- yolo系列目标检测+自标注数据集进行目标识别
1. yolov1的识别原理 参考:https://blog.csdn.net/u010712012/article/details/85116365 https://blog.csdn.net/gb ...
- 深度学习与CV教程(12) | 目标检测 (两阶段,R-CNN系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 带你读AI论文丨用于目标检测的高斯检测框与ProbIoU
摘要:本文解读了<Gaussian Bounding Boxes and Probabilistic Intersection-over-Union for Object Detection&g ...
- 大话目标检测经典模型(RCNN、Fast RCNN、Faster RCNN)
目标检测是深度学习的一个重要应用,就是在图片中要将里面的物体识别出来,并标出物体的位置,一般需要经过两个步骤:1.分类,识别物体是什么 2.定位,找出物体在哪里 除了对单个物体进行检测,还要能支持 ...
随机推荐
- 『动善时』JMeter基础 — 27、通过JMeter函数助手实现参数化
目录 1.测试计划中的元件 2.数据文件内容 3.函数助手配置 (1)函数助手的打开方式 (2)函数助手界面介绍 (3)编辑后的函数助手界面 4.HTTP请求组件内容 5.线程组元件内容 6.脚本运行 ...
- ALD技术,相机去噪,图像传感器
ALD技术,相机去噪,图像传感器 1. 作为镜片的防反射涂层技术被关注的ALD(atomic layer deposition)的引入趋势. (a)为什么需要一种新的防止反射的涂层技术? ALD被认为 ...
- MinkowskiNonlinearities非线性
MinkowskiNonlinearities非线性 MinkowskiReLU class MinkowskiEngine.MinkowskiReLU(*args, **kwargs) __init ...
- CVPR2020:点云分析中三维图形卷积网络中可变形核的学习
CVPR2020:点云分析中三维图形卷积网络中可变形核的学习 Convolution in the Cloud: Learning Deformable Kernels in 3D Graph Con ...
- 痞子衡嵌入式:嵌入式里通用微秒(microseconds)计时函数框架设计与实现
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家分享的是嵌入式里通用微秒(microseconds)计时函数框架设计与实现. 在嵌入式软件开发里,计时可以说是非常基础的功能模块了,其应用也非常 ...
- 俄罗斯方块(c++)
这个俄罗斯方块是用c++基于windows控制台制作的. 源码地址:https://github.com/Guozhi-explore 话不多说,先上图感受一下:(控制台丑陋的界面不是我的锅emmm) ...
- 【NX二次开发】通过两点创建单位向量
源码1: //生成从起点到终点的单位向量 double douPoint_Start[3] = { 10,10,10 }; double douPoint_End[3] = { 15,16,13 }; ...
- 『心善渊』Selenium3.0基础 — 1、Selenium自动化测试框架介绍
目录 1.Selenium介绍 2.Selenium的特点 3.Selenium版本说明 4.拓展:WebDriver与Selenium RC的区别 5.Webdriver工作原理 1.Seleniu ...
- SpringBoot2配置文件application.yaml
源码基于SpringBoot 2.4.4 1.认识配置文件 1.1 配置文件的加载 创建SpringBoot项目的时候,会自动创建一个application.properties文件,该文件是Spri ...
- Django(65)jwt认证原理
前言 带着问题学习是最有目的性的,我们先提出以下几个问题,看看通过这篇博客的讲解,能解决问题吗? 什么是JWT? 为什么要用JWT?它有什么优势? JWT的认证流程是怎样的? JWT的工作原理? 我们 ...