大数据 | 分布式文件系统 HDFS
HDFS 的特点与应用场景
适合存储大文件
容错性高
适用于流式的数据访问
适用于读多写少场景
HDFS的相关概念
数据块(Block)
NameNode和DataNode
Secondary NameNode
块缓存
HDFS 架构
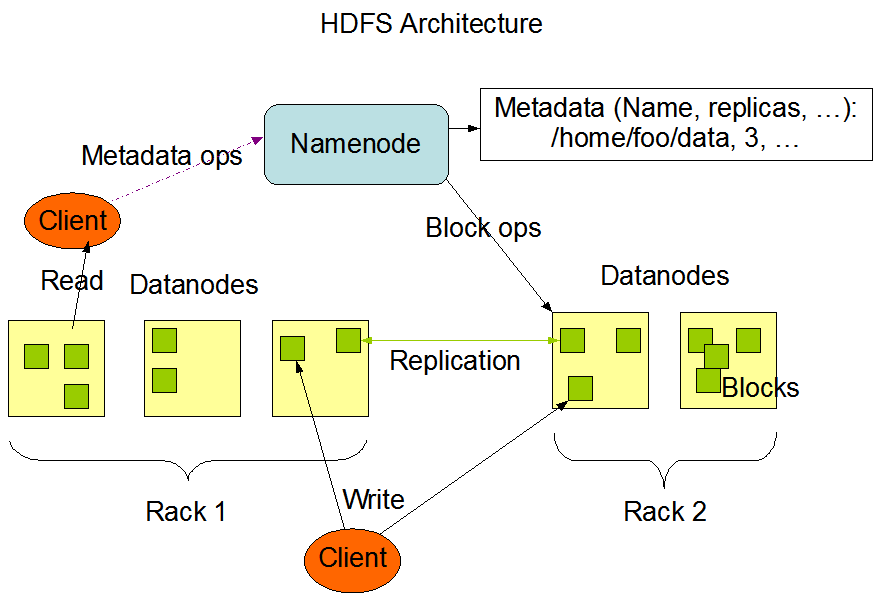
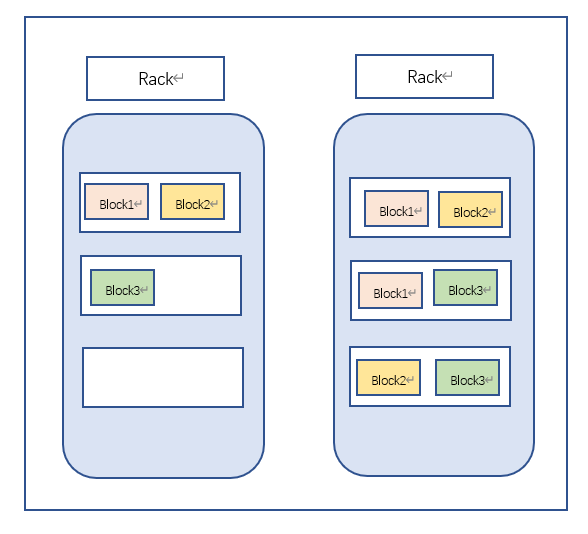
机架感知和副本机制
读写流程
读操作
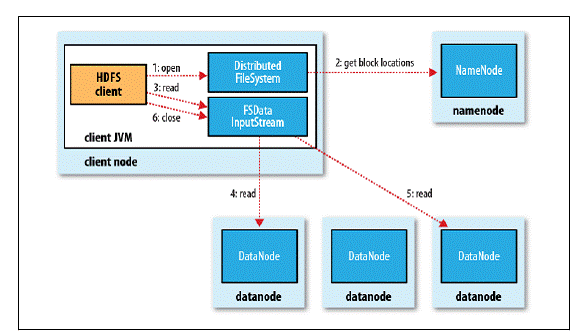
- 客户端通过调用 FileSystem 对象的 open() 方法来打开希望读取的文件,对于 HDFS 来说,这个对象是分布式文件系统的一个实例;
- DistributedFileSystem 通过RPC 调用 NameNode 以确定文件起始块的位置,由于存在多个副本,因此Namenode会返回同一个Block的多个文件的位置,然后根据集群拓扑结构排序,就近取;
- 前两步会返回一个 FSDataInputStream 对象,该对象会被封装成 DFSInputStream 对象,DFSInputStream 可以方便的管理 datanode 和 namenode 数据流,客户端对这个输入流调用 read() 方法;
- 存储着文件起始块的 DataNode 地址的 DFSInputStream 随即连接距离最近的 DataNode,通过对数据流反复调用 read() 方法,可以将数据从 DataNode 传输到客户端;
- 到达块的末端时,DFSInputStream 会关闭与该 DataNode 的连接,然后寻找下一个块的最佳 DataNode,这些操作对客户端来说是透明的,从客户端的角度来看只是读一个持续不断的流;
- 一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法关闭文件读取。
写操作
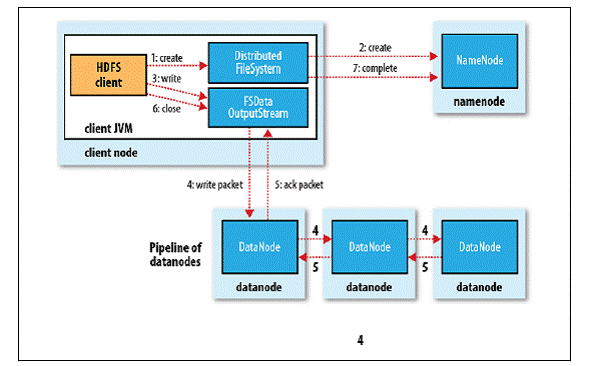
- 客户端通过调用 DistributedFileSystem 的 create() 方法创建新文件;
- DistributedFileSystem 通过 RPC 调用 NameNode 去创建一个没有 Blocks 关联的新文件,创建前 NameNode 会做各种校验,比如文件是否存在、客户端有无权限去创建等。如果校验通过,NameNode 会为创建新文件记录一条记录,否则就会抛出 IO 异常;
- 前两步结束后会返回 FSDataOutputStream 的对象,和读文件的时候相似,FSDataOutputStream 被封装成 DFSOutputStream,DFSOutputStream 可以协调 NameNode 和 Datanode。客户端开始写数据到 DFSOutputStream,DFSOutputStream 会把数据切成一个个小的数据包,并写入内部队列称为“数据队列”(Data Queue);
- DataStreamer 会去处理接受 Data Queue,它先问询 NameNode 这个新的 Block 最适合存储在哪几个 DataNode 里,比如重复数是 3,那么就找到 3 个最适合的 DataNode,把他们排成一个 pipeline。DataStreamer 把 Packet 按队列输出到管道的第一个 Datanode 中,第一个 DataNode 又把 Packet 输出到第二个 DataNode 中,以此类推;
- DFSOutputStream 还有一个队列叫 Ack Quene,也是由 Packet 组成,等待 DataNode 的收到响应,当 Pipeline 中的所有 DataNode 都表示已经收到的时候,这时 Akc Quene 才会把对应的 Packet 包移除掉;
- 客户端完成写数据后调用 close() 方法关闭写入流;
- DataStreamer 把剩余的包都刷到 Pipeline 里然后等待 Ack 信息,收到最后一个 Ack 后,通知 NameNode 把文件标示为已完成。
总结

大数据 | 分布式文件系统 HDFS的更多相关文章
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- 大数据 | 分布式文件系统HDFS 练习
本次作业来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 利用Shell命令与HDFS进行交互 以”./bin/dfs ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- Hadoop分布式文件系统--HDFS结构分析
转自:http://blog.csdn.net/androidlushangderen/article/details/47377543 HDFS系列:http://blog.csdn.net/And ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 大数据篇:HDFS
HDFS HDFS是什么? Hadoop分布式文件系统(HDFS)是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File Syste ...
- 你想了解的分布式文件系统HDFS,看这一篇就够了
1.分布式文件系统 计算机集群结构 分布式文件系统把文件分布存储到多个节点(计算机)上,成千上万的计算机节点构成计算机集群. 分布式文件系统使用的计算机集群,其配置都是由普通硬件构成的,与用多个处理器 ...
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 大数据技术 - 分布式文件系统 HDFS 的设计
本章内容介绍下 Hadoop 自带的分布式文件系统,HDFS 即 Hadoop Distributed Filesystem.HDFS 能够存储超大文件,可以部署在廉价的服务器上,适合一次写入多次读取 ...
随机推荐
- 034.Python的__str__,__repr__,__bool__ ,__add__和__len__魔术方法
Python的其他方法 1 __str__方法 触发时机: 使用print(对象)或者str(对象)的时候触发 功能: 查看对象信息 参数: 一个self接受当前对象 返回值: 必须返回字符串类型 基 ...
- python基础之流程控制(if判断和while、for循环)
程序执行有三种方式:顺序执行.选择执行.循环执行 一.if条件判断 1.语句 (1)简单的 if 语句 (2)if-else 语句 (3)if-elif-else 结构 (4)使用多个 elif 代码 ...
- Jquery的load加载本地文件出现跨域错误的解决方案"Access to XMLHttpRequest at 'file:///android_asset/web/graph.json' from(Day_46)
博主是通过JS调用本地的一个json文件赋值给变量出现的跨域错误, 网上有大量文章,五花八门的,但总归,一般性此问题基本可通过这三种方法解决: https://blog.csdn.net/qq_418 ...
- 同一个Controller里的同一个Service实例,在当前的Controller里的不同方法中状态不一致
直接上代码如下: @Controller@RequestMapping("/views/information")public class PubContentController ...
- stream的groupby出来的map是有顺序的map
stream分组后的map是有序map List<RedisInstanceTypeDto> typeDtoList = ModuleHelper.mapAll(redisInstance ...
- SLAM相机定位
SLAM相机定位 摘要 深度学习在相机定位方面取得了很好的结果,但是当前的单幅图像定位技术通常会缺乏鲁棒性,从而导致较大的离群值.在某种程度上,这已通过序列的(多图像)或几何约束方法解决,这些方法可以 ...
- 多篇开源CVPR 2020 语义分割论文
多篇开源CVPR 2020 语义分割论文 前言 1. DynamicRouting:针对语义分割的动态路径选择网络 Learning Dynamic Routing for Semantic Segm ...
- Vitis-AI集成
Vitis-AI集成 Vitis-AI是Xilinx的开发堆栈,用于在Xilinx平台(包括边端设备和Alveo卡)上进行硬件加速的AI推理.它由优化的IP,工具,库,模型和示例设计组成.设计时考虑到 ...
- NVIDIA Jarvis:一个GPU加速对话人工智能应用的框架
NVIDIA Jarvis:一个GPU加速对话人工智能应用的框架 Introducing NVIDIA Jarvis: A Framework for GPU-Accelerated Conversa ...
- 用华为MindSpore进行分布式训练
技术背景 分布式和并行计算,在计算机领域是非常重要的概念.对于一些行外人来说,总觉得这是一些很简单的工作,但是如果我们纵观计算机的硬件发展史,从CPU到GPU,再到TPU和华为的昇腾(NPU),乃至当 ...