Redis源码分析(sds)
源码版本:redis-4.0.1
源码位置:https://github.com/antirez/sds
一、SDS简介
sds (Simple Dynamic String),Simple的意思是简单,Dynamic即动态,意味着其具有动态增加空间的能力,扩容不需要使用者关心。String是字符串的意思。说白了就是用C语言自己封装了一个字符串类型,这个项目由Redis作者antirez创建,作为Redis中基本的数据结构之一,现在也被独立出来成为了一个单独的项目,项目地址位于这里。
sds 有两个版本,在Redis 3.2之前使用的是第一个版本,其数据结构如下所示:
typedef char *sds; //注意,sds其实不是一个结构体类型,而是被typedef的char*,好处见下文
struct sdshdr {
unsigned int len; //buf中已经使用的长度
unsigned int free; //buf中未使用的长度
char buf[]; //柔性数组buf
};但是在Redis 3.2 版本中,对数据结构做出了修改,针对不同的长度范围定义了不同的结构,如下,这是目前的结构:
typedef char *sds;
struct __attribute__ ((__packed__)) sdshdr5 { // 对应的字符串长度小于 1<<5
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 { // 对应的字符串长度小于 1<<8
uint8_t len; /* used */ //目前字符创的长度
uint8_t alloc; //已经分配的总长度
unsigned char flags; //flag用3bit来标明类型,类型后续解释,其余5bit目前没有使用
char buf[]; //柔性数组,以'\0'结尾
};
struct __attribute__ ((__packed__)) sdshdr16 { // 对应的字符串长度小于 1<<16
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 { // 对应的字符串长度小于 1<<32
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 { // 对应的字符串长度小于 1<<64
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
新版带来的好处就是针对长度不同的字符串做了优化,选取不同的数据类型uint8_t或者uint16_t或者uint32_t等来表示长度、一共申请字节的大小等。上面结构体中的__attribute__ ((__packed__)) 设置是告诉编译器取消字节对齐,则结构体的大小就是按照结构体成员实际大小相加得到的。
二、SDS的优势和不足
sds和一般的自定义String相比,有自己的优势和不足,假设我们用C语言自己定义一个String结构体,一般会这么定义:
struct mysds {
char *buf; //存储实际字符
size_t len; //字符串的长度
... possibly more fields here ... //其他的成员
};如果我们要打印buf的内容,如下这样使用:
struct mysds *sds = mysdsnew("Hello World"); //假设mysdsnew函数中分配空间并初始化buf为"Hello World"
printf("%s", sds->buf);
Out> Hello World即我们打印的buf是属于struct mysds的一个成员,我们需要通过指针操作它。但是Redis sds与之不同,它的定义是typedef char *sds;,如果使用它实现上面的功能,我们的代码是:
sds sds = sdsnew("Hello World");
printf("%s", sds);
Out> Hello World在这里我们直接输出的是sds,之所以可以这样,是因为它的结构如下所示:
+--------+-------------------------------+-----------+
| Header | Binary safe C alike string... | Null term |
+--------+-------------------------------+-----------+
|
`-> Pointer returned to the user.我们通过sdsnew返回的实际上是一个char *类型的指针,这个指针指向的是字符串的开始位置,它的头部信息是在字符串前面分配的,这样带来的好处有:
- 我们可以把sds传递给任何使用
char *为参数的函数,包括一些库函数(strcmp,strcat等),而不用通过结构体获取地址再传递。 - 可以直接访问单个字符
printf("%c %c\n", sds[0], sds[1]);如果使用mysds则需要每次获取下buf的地址mysds->buf[1]再访问。 - 分配的空间地址连续,对高速缓存命中率更加友好。即一次连续分配
Header+String+Null,因此对于一个sds,它的各个部分总是内存连续的,但是上面的mysds通常需要两次malloc,如下所示:
struct mysds *sds = (struct mysds *) malloc(sizeof(struct mysds));
sds->buf = (char *) malloc(SIZE);
//这两次malloc不能保证sds和buf内存地址是连续的除了上面的优点,sds还有一些缺点:
- API返回后不能确定内部是否重新分配了空间
s = sdscat(s, "Some more data"); s既是参数,又作为了返回值,原因是我们在调用sdscat函数之前不确定s的剩余空间是否足够分配出
data长度的字节,如果不够的话,内部会重新malloc空间,然后把目前的sds包括头部全部挪过去,这样的话如果我们没有把返回的地址重新赋值给s,那么s实际上是失效的。
- 如果sds会在程序的不同位置共享,则在修改字符串时候必须修改所有的应用。因为它本身是一个
char *的地址,一旦在一个地方重新分配了,则其他地方的会失效。
三、创建、扩容和销毁
接下来我们以一个例子来跟踪源码展示sds的创建、扩容和销毁等过程,这是我们的源代码:
int main(int argc, char *argv[]) {
sds s = sdsnew("Hello World,");
printf("Length:%d, Type:%d\n", sdslen(s), sdsReqType(sdslen(s)));
s = sdscat(s, "The length of this sentence is greater than 32 bytes");
printf("Length:%d, Type:%d\n", sdslen(s), sdsReqType(sdslen(s)));
sdsfree(s);
return 0;
}
Out>
Length:12, Type:0
Length:64, Type:1
首先我们创建了一个sds名为s,初始化为”Hello World”,然后打印它的length和type分别为12和0,接着我们继续给s追加了一个字符串,使得它的长度变成了64,获取type,发现变成了1,最后free掉s,有关type的定义,位于sds.h头文件,随着长度不同,type也会发生变化。
#define SDS_TYPE_5 0 //长度小于 1<<5 即32,类型为SDS_TYPE_5
#define SDS_TYPE_8 1 // ...
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4下面我们从sdsnew出发,去看下它的实现:
/* Create a new sds string starting from a null terminated C string. */
sds sdsnew(const char *init) {
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}可以看到sdsnew实际上调用了sdsnewlen,帮我们计算了传进去的字符串长度,然后传给sdsnewlen,继续看sdsnewlen
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1);
if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\0';
return s;
}函数基本流程如下所示:
char type = sdsReqType(initlen);根据我们传入的初始化字符串长度获取类型,获取代码如下:
static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
#endif
return SDS_TYPE_64;
}函数根据字符串大小的不同返回不同的类型。
int hdrlen = sdsHdrSize(type);根据上一步获取的type通过sdsHdrSize函数获得Header的长度,sdsHdrSize代码如下:
static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
}
return 0;
}这个函数直接return了相应的结构体大小。
接下来
malloc申请了hdrlen+initlen+1大小的空间,表示头部+字符串+Null,然后让s指向了字符串的首地址,fp指向了头部的最后一个字节,也就是flag。然后我们的程序进入了
switch,因为类型为SDS_TYPE_5,所以执行了*fp = type | (initlen << SDS_TYPE_BITS);对于SDS_TYPE_5类型来说,长度信息实际上也是存在flag里面的,因为最大长度是31,占5bit,还有3bit表示type。接着
break出来后,完成了字符串的拷贝工作,然后给s结尾置’\0’,s[initlen] = '\0';,至此,sdsnew调用完毕,此时我们的sds结构如下图所示:
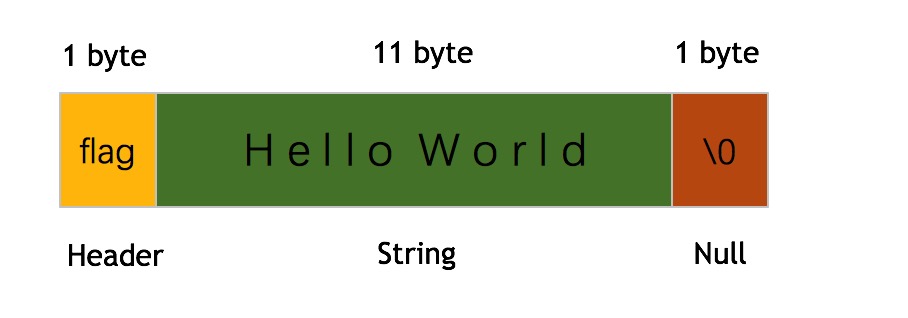
flag大小为1字节,中间的String长度为11字节,后面还有一个\0结尾。接着我们的代码执行输出长度和类型,然后调用了sdscat函数,如下:
s = sdscat(s, "The length of this sentence is greater than 32 bytes");
我们给原始的s继续追加了超过32个字符,其实目的是为了是它转变成SDS_TYPE_8类型,sdscat的代码如下所示:
sds sdscat(sds s, const char *t) {
return sdscatlen(s, t, strlen(t));
}它调用了sdscatlen函数:
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}size_t curlen = sdslen(s);首先获取了当前的长度curlen,接着调用了sdsMakeRoomFor函数,这个函数比较关键,它能保证s的空间足够,如果空间不足会动态分配,代码如下:
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
size_t avail = sdsavail(s);首先调用sdsavail函数获取了当前s可用空间的大小,sdsavail函数如下:
static inline size_t sdsavail(const sds s) {
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5: {
return 0;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
return sh->alloc - sh->len;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
return sh->alloc - sh->len;
}
}
return 0;
}对于SDS_TYPE_5类型,直接return 0,对于其他类型,需要在Header获取alloc和len然后相减,获取Header的宏如下:
SDS_HDR_VAR(8,s);
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
//本质上就是用s的地址减去(偏移)相应头部结构体大小的地址,就到了Header的第一个字节
return sh->alloc - sh->len;
//然后返回可用字节大小
if (avail >= addlen) return s;接着判断大小,如果空间是足够的,则将s返回,函数结束。- 否则我们获取到目前的长度,然后给它加上
sdscat所追加的字符串长度,如果此时的新长度没有超过SDS_MAX_PREALLOC=1024*1024,我们再给新长度x2,这样做是为了避免频繁调用malloc。 type = sdsReqType(newlen);然后我们需要根据新长度重新获取type类型。if (oldtype==type)然后判断type是否发生了变化,来决定扩充空间还是重新申请空间。对于我们的例子,接下来需要重新分配空间,如下,走else分支:
else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1); //重新分配Header+newlen+1的空间
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1); //将String部分拷贝至新String部分
s_free(sh); //把旧的sds全部释放
s = (char*)newsh+hdrlen;
s[-1] = type; //将type更新
sdssetlen(s, len); //设置大小
}
sdssetalloc(s, newlen); //设置alloc大小
return s; //将新的s返回
}当sdsMakeRoomFor函数返回后,sdscatlen函数继续执行,将需要添加的字符串拷贝至新的空间,然后设置长度和最后的\0就返回了。此时s变成了下面这样:

需要注意的是执行代码打印出来长度为64指的是已经分配的长度,也就是len的大小,图片上的128是alloc的大小,则此时可用长度还有64字节,下次如果再追加小于64字节的内容就不会重新分配了。最后我们看下free的过程,代码如下:
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}很简单,如果为NULL就返回,否则得到Header的首地址然后释放,sdsHdrSize(s[-1])是根据flag类型获取Header的长度,用s减去(偏移)Header长度个字节就到头部了。上面的过程基本上分析清楚了sds有关于创建和扩容以及释放的过程,这样其实已经把握了sds的大体脉络,接下来我们看一下它还实现了哪些方便的接口供我们使用。
四、其他的接口和特性
1、sdssplitargs函数可以将字符串分割,它会默认按\n、空格、\t、\r、、0以及双引号和单引号进行分割,如下所示:
eg1:
int args;
sds *arr = sdssplitargs("H\ne\tl\rlo Wor\ald",&args);
printf("args is :%d\n",args);
for (int i = 0; i < args; ++i) {
printf("%s ", arr[i]);
}
sdsfreesplitres(arr,args); //注意free方式
Out>
args is :5
H e l lo Wor ld
eg2;
sds *arr = sdssplitargs("\"Hello\" World",&args);
Out>
args is :2
Hello World
eg3:
sds *arr = sdssplitargs("\x41 \x42 \x43",&args);
Out>
args is :3
A B C //把16进制转成了10进制2、sdssplitlen也是分割字符串的函数,不过它只可以指定一个分割符号进行分割,但是这个符号可以是一个字符串。
sds s = sdsnew("Hello_-_World");
int args;
sds *arr = sdssplitlen(s, sdslen(s), "_-_", 3, &args);
printf("args is :%d\n", args);
for (int i = 0; i < args; ++i) {
printf("%s ", arr[i]);
}
Out>
args is :2
Hello World 3、sdscatprintf()格式化字符串,类似于sprintf():
int a = 1,b = 1;
sds s = sdsnew("Sum is: ");
s = sdscatprintf(s, "%d+%d = %d", a, b, a+b);
printf("%s\n", s);
Out>
Sum is: 1+1 = 24、sdscatfmt类似于sdscatprintf,但是比sdscatprintf要快,因为它不依赖于libc提供的sprintf()函数,但是它指实现了一部分格式化语义,如下:
* However this function only handles an incompatible subset of printf-alike
* format specifiers:
*
* %s - C String
* %S - SDS string
* %i - signed int
* %I - 64 bit signed integer (long long, int64_t)
* %u - unsigned int
* %U - 64 bit unsigned integer (unsigned long long, uint64_t)
* %% - Verbatim "%" character.
sds s = sdsnewlen("Hello ",6);
s = sdscatfmt(s,"%s"," World");
printf("%s\n",s);
Out>
Hello World5、sdstrim可以剔除sds中指定的字符:
sds s = sdsnew("AA...AA.a.aa.aHelloWorldiii :::");
s = sdstrim(s, "A. a:i");
printf("%s\n",s);
>Out
HelloWorld6、sdsrange类似于substring的功能,可以返回子串
sds s = sdsnew("Hello World");
sdsrange(s, 1, -1); // 1 表示第一个字符,-1 表示倒数第一个字符
printf("%s\n", s);
Out>
ello World 7、sdsmapchars可以将字符串中指定字符替换。
sds s = sdsnew("Hello World");
s = sdsmapchars(s, "o", "u", 1); //将o替换成u
printf("%s\n",s);
Out>
Hellu Wurld[完]
Redis源码分析(sds)的更多相关文章
- Redis源码分析:serverCron - redis源码笔记
[redis源码分析]http://blog.csdn.net/column/details/redis-source.html Redis源代码重要目录 dict.c:也是很重要的两个文件,主要 ...
- redis源码分析之事务Transaction(下)
接着上一篇,这篇文章分析一下redis事务操作中multi,exec,discard三个核心命令. 原文地址:http://www.jianshu.com/p/e22615586595 看本篇文章前需 ...
- redis源码分析(一)-sds实现
redis支持多种数据类型,sds(simple dynamic string)是最基本的一种,redis中的字符串类型大多使用sds保存,它支持动态的扩展与压缩,并提供许多工具函数.这篇文章将分析s ...
- redis源码分析之有序集SortedSet
有序集SortedSet算是redis中一个很有特色的数据结构,通过这篇文章来总结一下这块知识点. 原文地址:http://www.jianshu.com/p/75ca5a359f9f 一.有序集So ...
- Redis源码分析(intset)
源码版本:4.0.1 源码位置: intset.h:数据结构的定义 intset.c:创建.增删等操作实现 1. 整数集合简介 intset是Redis内存数据结构之一,和之前的 sds. skipl ...
- Redis源码分析(dict)
源码版本:redis-4.0.1 源码位置: dict.h:dictEntry.dictht.dict等数据结构定义. dict.c:创建.插入.查找等功能实现. 一.dict 简介 dict (di ...
- redis源码分析之发布订阅(pub/sub)
redis算是缓存界的老大哥了,最近做的事情对redis依赖较多,使用了里面的发布订阅功能,事务功能以及SortedSet等数据结构,后面准备好好学习总结一下redis的一些知识点. 原文地址:htt ...
- redis源码分析之事务Transaction(上)
这周学习了一下redis事务功能的实现原理,本来是想用一篇文章进行总结的,写完以后发现这块内容比较多,而且多个命令之间又互相依赖,放在一篇文章里一方面篇幅会比较大,另一方面文章组织结构会比较乱,不容易 ...
- Redis源码分析系列
0.前言 Redis目前热门NoSQL内存数据库,代码量不是很大,本系列是本人阅读Redis源码时记录的笔记,由于时间仓促和水平有限,文中难免会有错误之处,欢迎读者指出,共同学习进步,本文使用的Red ...
随机推荐
- 重新整理 .net core 周边阅读篇————AspNetCoreRateLimit[一]
前言 整理了一下.net core 一些常见的库的源码阅读,共32个库,记100余篇. 以下只是个人的源码阅读,如有错误或者思路不正确,望请指点. 正文 github 地址为: https://git ...
- 鸿蒙内核源码分析(根文件系统) | 先挂到`/`上的文件系统 | 百篇博客分析OpenHarmony源码 | v66.01
百篇博客系列篇.本篇为: v66.xx 鸿蒙内核源码分析(根文件系统) | 先挂到/上的文件系统 | 51.c.h.o 文件系统相关篇为: v62.xx 鸿蒙内核源码分析(文件概念篇) | 为什么说一 ...
- P3980-[NOI2008]志愿者招募【费用流】
正题 题目链接:https://www.luogu.com.cn/problem/P3980 题目大意 \(n\)天,第\(i\)天需要\(A_i\)个志愿者.有\(m\)种志愿者,第\(i\)种从\ ...
- 腾讯的表妹告诉我怎么学Python,今天就教我搭建Python环境和基本语法,我【码上开始】
本文首发公众号:码上开始 环境准备 Pycharm Python3 window10/win7 安装 Python 打开Python官网地址 下载 executable installer,x86 表 ...
- Python3模块调用你真的会吗?不懂就来看一看?
前言 学习Python自动化框架的时候,各种文件会相互之间的调用.刚学的时候是不是很头疼!有木有!!一步步告诉你如何调用文件里的类和方法. 经常会调用同目录下的文件还有跨文件的调用 调用同目录下文件A ...
- IdentityServer4[3]:使用客户端认证控制API访问(客户端授权模式)
使用客户端认证控制API访问(客户端授权模式) 场景描述 使用IdentityServer保护API的最基本场景. 我们定义一个API和要访问API的客户端.客户端从IdentityServer请求A ...
- Wireshark简单协议的抓包分析
一.实验目的 HTTP.TCP.UDP.ICMP.ARP.IP.FTP.TELNET查询分析 基本掌握查询命令的使用方法 二.实验环境 硬件环境:一台Windows7系统,一台XP系统 软件环境:VM ...
- caffe运行错误 target_blobs.blobs_size()与 source_layer.blobs_size() 不一致
解决方法参考:http://blog.csdn.net/zhangla1220/article/details/50697352 感谢博主!!! 最新下载的caffe代码,运行mnist,训练时可以正 ...
- Java初步学习——2021.10.10每日总结,第五周周日
(1)今天做了什么: (2)明天准备做什么? (3)遇到的问题,如何解决? 今天继续学习菜鸟教程java字符串实例 5.字符串反转--reverse方法 public class Main { pub ...
- 洛谷4208 JSOI2008最小生成树计数(矩阵树定理+高斯消元)
qwq 这个题目真的是很好的一个题啊 qwq 其实一开始想这个题,肯定是无从下手. 首先,我们会发现,对于无向图的一个最小生成树来说,只有当存在一些边与内部的某些边权值相同的时候且能等效替代的时候,才 ...