MySQL读写IO的操作过程解析
数据库作为存储系统,所有业务访问数据的操作都会转化为底层数据库系统的IO行为(缓存系统也可以当做是key-value的数据库),本文主要介绍访问MySQL数据库的IO流程以及IO相关的参数。
一、MySQL的文件
首先简单介绍一下MySQL的数据文件,MySQL 数据库包含如下几种文件类型:
1)数据文件 (datafile)
存放表中的具体数据的文件。
2)数据字典
记录数据库中所有innodb表的信息。
3)重做日志 (redolog)
记录数据库变更记录的文件,用于系统异常crash(掉电)后的恢复操作,可以配置多个(配置这个参数innodb_log_files_in_group)比如 ib_logfile0、 ib_logfile1。
4)回滚日志 (undolog)
也存在于mysql 的ibdata文件,用户记录事务的回滚操作。注在mysql5.6以上版本可以拆开出来,单独文件夹存在。
5)归档日志 (binlog)
事务提交之后,记录到归档日志中。
6)中继日志 (relaylog)
从master获取到slave的中转日志文件,sql_thread则会应用relay log并重放于从机器。
7)其他日志slowlolg, errorlog, querylog
这里慢日志也经常用。可以结合pt-query-digest工具和anemometer一起展示出来。
对于以上文件的IO访问顺序可以分为顺序访问 比如binlog ,redolog ,relay log是顺序读写,datafile,ibdata file是随机读写,这些IO访问的特点决定了在os 配置磁盘信息时候,如何考虑分区 ,比如顺序写可以的log可以放到SAS盘 ,随机读写的数据文件可以放到ssd或者fio高性能的存储。
二、数据访问流程
数据库访问分为两种类型, 一种是读操作,另外一种是写操作。
- 读操作
|
1
2
3
4
5
6
|
create table t (
id int not null primary key ,
k1 int not null,
data varchar(50),
key ind_k1(k1)
) engine=innodb default charset=utf8;
|
以select * from tab where k1=1 ;为例。
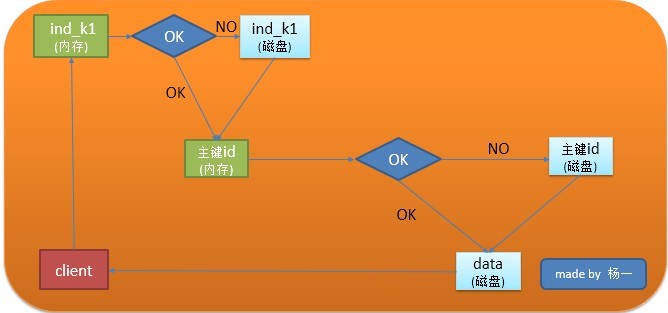
读操作的IO流程
1、查看缓存中是否存在id,
2、如果有则从内存中访问,否则要访问磁盘,
3、并将索引数据存入内存,利用索引来访问数据,
4、对于数据也会检查数据是否存在于内存,
5、如果没有则访问磁盘获取数据,读入内存。
6、返回结果给用户。
- 写操作
为了保证数据写入操作的安全性,数据库系统设置了 undo,redo 保护机制,避免因为os或者数据库系统异常导致的数据丢失或者不一致的异常情况发生。
以insert into t values(1,1,’shuiyi’);为例。
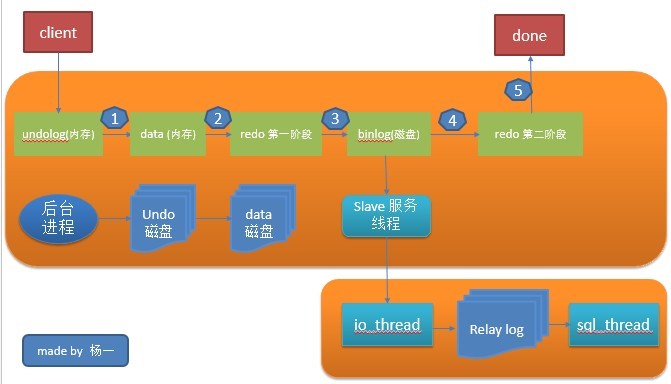
写操作的IO流程
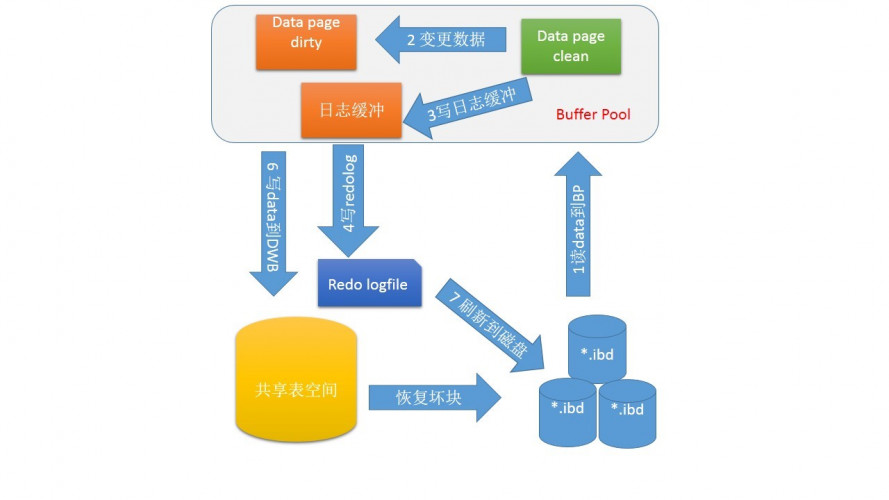
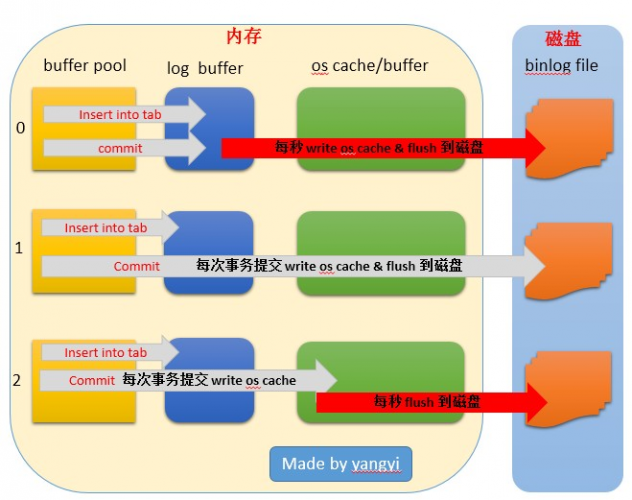
我们假定数据在内存中,不考虑从磁盘中获取数据的情形,大致的写操作步骤:
1、先写undo log。
2、在内存更新数据,这步操作就在内存中形成了脏页,如果脏页过多,checkpoint机制进行刷新,innodb_max_dirty_pages_pct决定了刷新脏页比例。innodb_io_capacity参数可以动态调整刷新脏页的数量,innodb_lru_scan_depth这个参数决定了刷新每个innodb_buffer_pool的脏页数量。
3、记录变更到redo log,prepare这里会写事务id。innodb_flush_log_at_trx_commit决定了事务的刷盘方式。为0时,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行。该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去.为2,每次事务提交时MySQL都会把log buffer的数据写入log file.但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
4、写入binlog这里会写入一个事务id这里有个sync_binlog参数决定多个事务进行一次性提交。
5、redo log第二阶段,这里会进行判断前2步是否成功,成功则默认commit,否则rollback。刷入磁盘操作。这里是先从脏页数据刷入到内存2M大小的doublewrite buffer,然后是一次性从内存的doublewrite buffer刷新到共享表空间的doublewrite buffer,这里产生了一次IO。然后从内存的内存的doublewrite buffer刷新2m数据到磁盘的ibd文件中,这里需要发生128次io。然后校验,如果不一致,就由共享表空间的副本进行修复。这里有个参数innodb_flush_method决定了数据刷新直接刷新到磁盘,绕过os cache。
6、返回给client。
如果有slave,第4步之后经过slave服务线程io_thread写到从库的relay log ,再由sql thread应用relay log到从库中。
关于性能?
写undo redo log ,binlog的过程中都是顺序写,都会很快的完成,随机写操作,inset_buffer功能。
对于非聚集类索引的插入和更新操作(5.5 版本及以上支持Update/Delete/Purge等操作的buffer功能),不是每一次都直接插入到索引页中,而是先插入到内存中。具体做法是:如果该索引页在缓冲池中,直接插入;否则,先将其放入插入缓冲区中,再以一定的频率和索引页合并,就可以将同一个索引页中的多个插入合并到一个IO操作中,改随机写为顺序写,大大提高写性能。
关于数据安全,这是数据库写入的重点?
1,2,3过程失败就是事务失败,因为此时还未写入磁盘,对磁盘中的数据无影响,返回事务失败给client,从库也不会受到影响。 4,5过程失败的时候或者已经将写成功返回给客户,可以根据redo log的记录来进行恢复,如果出现部分写失效请参考《double write》。
MySQL的写redo log的第一个阶段会把所有需要做的操作做完,记录数据变更,第二阶段的工作比较简单 ,只做事务提交确认。如果写入binlog成功,而第二阶段失败,MySQL启动时也会将事务进行重做,最终更新到磁盘中。MySQL 5.5+的smei sync可以更好的保障主从的事务一致性。
三、文件访问方式
IO 访问的方式分为两种顺序读写和随机读写, 在MySQL的io过程中可以以此来将数据库文件分类
顺序读写:重做日志ib_logfile*,binlog file。
随机读写:innodb表数据文件,ibdata文件。
根据系统的访问类型,对硬件做如下分类:读多(SSD+RAID)、写多FIO(flashcache)、容量密集(fio + flashcache)。
由于随机io会严重降低系统的性能,在当前的硬件水平下,可以考虑选择奖数据库服务器配置ssd/fusionio。
四、影响IO的参数和策略
影响mysql io的参数有很多个,这里罗列几个重要的参数。
innodb_buffer_pool_size
该参数控制innodb缓存大小,用于缓存应用访问的数据,推荐配置为系统可用内存的80%。
binlog_cache_size
该参数控制二进制日志缓冲大小,当事务还没有提交时,事务日志存放于cache,当遇到大事务cache不够用的时,mysql会把uncommitted的部分写入临时文件,等到committed的时候才会写入正式的持久化日志文件。
innodb_max_dirty_pages_pct
该参数可以直接控制Dirty Page在BP中所占的比率,当dirty page达到了该参数的阈值,就会触发MySQL系统刷新数据到磁盘。
innodb_flush_log_at_trx_commit
该参数确定日志文件何时write、flush。
为0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。
为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去.
为2,每次事务提交时MySQL都会把log buffer的数据写入log file.但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
注意:由于进程调度策略问题,这个“每秒执行一次flush(刷到磁盘)操作”并不是保证100%的“每秒”。
sync_binlog
sync_binlog的默认值是0,像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。
当sync_binlog =N (N>0) ,MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
innodb_flush_method
该参数控制日志或数据文件如何write、flush。可选的值为fsync,o_dsync,o_direct,littlesync,nosync。
数据库的I/O是一个很复杂和细致的知识层面,涉及数据库层和OS层面的IO写入策略,也和硬件的配置有关,更详细看MySQL InnoDB磁盘I/O优化。
MySQL读写IO的操作过程解析的更多相关文章
- 100道MySQL数据库经典面试题解析(收藏版)
前言 100道MySQL数据库经典面试题解析,已经上传github啦 https://github.com/whx123/JavaHome/tree/master/Java面试题集结号 公众号:捡田螺 ...
- Docker安装Mycat并实现mysql读写分离,分库分表
Docker安装Mycat并实现mysql读写分离,分库分表 一.拉取mycat镜像 二.准备挂载的配置文件 2.1 创建文件夹并添加配置文件 2.1.1 server.xml 2.1.2 serve ...
- amoeba实现MySQL读写分离
amoeba实现MySQL读写分离 准备环境:主机A和主机B作主从配置,IP地址为192.168.131.129和192.168.131.130,主机C作为中间件,也就是作为代理服务器,IP地址为19 ...
- 使用Atlas实现MySQL读写分离+MySQL-(Master-Slave)配置
参考博文: MySQL-(Master-Slave)配置 本人按照博友北在北方的配置已成功 我使用的是 mysql5.6.27版本. 使用Atlas实现MySQL读写分离 数据切分——Atlas读 ...
- MySQL读写分离技术
1.简介 当今MySQL使用相当广泛,随着用户的增多以及数据量的增大,高并发随之而来.然而我们有很多办法可以缓解数据库的压力.分布式数据库.负载均衡.读写分离.增加缓存服务器等等.这里我们将采用读写分 ...
- MySQL数据库IO问题
--MySQL数据库IO问题 ----------------------2014/05/25 看http://www.mysqlperformanceblog.com 的时候,发现Perco ...
- mysql读写分离总结
随着一个网站的业务不断扩展,数据不断增加,数据库的压力也会越来越大,对数据库或者SQL的基本优化可能达不到最终的效果,我们可以采用读写分离的策略来改变现状.读写分离现在被大量应用于很多大型网站,这个技 ...
- laravel 读写分离源码解析
前言:上一篇我们说了<laravel 配置MySQL读写分离>,这次我们说下,laravel的底层代码是怎样实现读写分离的. 一.实现原理 说明: 1.根据 database.php ...
- mysql读写分离[高可用]
顾名思义, 在mysql负载均衡中有多种方式, 本人愚钝,只了解驱动中间件和mysql_proxy两种方式, 对于驱动,利用的是ReplicationDriver,具体请看远哥的这篇文章: MySQL ...
随机推荐
- Linux基础服务搭建综合
Linux服务综合搭建的文章目录 =============================================== 1.foundation创建yum仓库 2.部署DNS 3.将YUM源 ...
- jvm源码解读--02 Array<u1>* tags = MetadataFactory::new_writeable_array<u1>(loader_data, length, 0, CHECK_NULL); 函数引入的jvm内存分配解析
current路径: #0 Array<unsigned char>::operator new (size=8, loader_data=0x7fd4c802e868, length=8 ...
- ASP.NET Datalist制作显示效果和img的数据库存储
1. 具体实现效果如下图: 2.首先使用datalist控件编辑模板,在属性面板选择RepeatColumns="3" RepeatDirection="Horizont ...
- 3G/4G串口服务器
Z3G/4G串口服务器 ZLAN8303-7是上海卓岚继ZLAN8100之后推出的3G/4G联网解决方案.支持7模的4G串口服务器.其产品支持Modbus功能.自定义注册包心跳包功能. ZLAN830 ...
- Java 7 新特性之try-with-resources实践理解
想象这么一个情景,我们需要使用一个资源,在使用完之后需要关闭该资源,并且使用该资源的过程中有可能有异常抛出.此时我们都会想到用try-catch语句,在finally中关闭该资源.此时会有一个问题,如 ...
- 只要套路对,薪资直接翻一倍!保姆级Android面试葵花宝典,肝完面试犹如开挂
跳槽,这在 IT 互联网圈是非常普遍的,也是让自己升职加薪,走上人生巅峰的重要方式.那么作为一个普通的Android程序猿,我们如何才能斩获大厂offer 呢? 疫情向好.面试在即,还在迷茫踌躇中的后 ...
- Docker部署ELK之部署elasticsearch7.6.0(1)
1. 拉取elasticsearch7.6.0镜像: sudo docker pull elasticsearch:7.6.0 2. 输入命令,构建容器: sudo docker run --name ...
- 绿色djvu阅读软件
官方的djvu viewer都需要安装,总算找到一个绿色版的,名为STDU Viewer,可以阅读的格式包括DjVu, PDF, TIFF, XPS, FB2等,版本为1.6.2.
- 【笔记】Bagging和Pasting以及oob(Out-of-Bag)
Bagging和Pasting以及oob(Out-of-Bag) Bagging和Pasting 前面讲到soft voting classifier和hard voting classifier两个 ...
- CobaltStrike去除流量特征
CobaltStrike去除流量特征 普通CS没有做流量混淆会被防火墙拦住流量,所以偶尔会看到CS上线了机器但是进行任何操作都没有反应.这里尝试一下做流量混淆.参考网上的文章,大部分是两种方法,一种 ...