Django(21)migrate报错的解决方案
前言
在讲解如何解决migrate报错原因前,我们先要了解migrate做了什么事情,migrate:将新生成的迁移脚本。映射到数据库中。创建新的表或者修改表的结构。
问题1:migrate怎么判断哪些迁移脚本需要执行?
它会将代码中的迁移脚本和数据库中django_migrations中的迁移脚本进行对比,如果发现数据库中,没有这个迁移脚本,那么就会执行这个迁移脚本。
问题2:migrate做了什么事情
- 将相关的迁移脚本翻译成SQL语句,在数据库中执行这个SQL语句。
- 如果这个SQL语句执行没有问题,那么就会将这个迁移脚本的名字记录到
django_migrations中。
实战案例
当我们了解清楚migrate的作用后,我们来看一个案例
首先我们创建一个项目orm_migrations_demo,接着创建2个app应用front和article,代码结构如下图
接着在front.models.py和article.models.py中创建模型
# front.models.py
class Article(models.Model):
name = models.CharField(max_length=200)
# article.models.py
class FrontUser(models.Model):
name = models.CharField(max_length=200)
接着在settings.py的INSTALL_APPS中将app注册
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'front',
'article',
]
接着我们打开命令行,输入makemigrations article,再输入makemigrations front,此时2个app目录中都会出现迁移文件0001_initial.py,此时数据库中是没有表的,因为还没有执行迁移命令
接着我们执行migrate article,再输入migrate front,migrate发现数据库中没有迁移脚本,那么就会执行刚才生成的2个迁移脚本,将迁移脚本翻译成SQL语句,然后创建了2张表,执行完成后,会将迁移脚本记录到django_migrations表中,数据库中表结构如下

django_migrations表中内容如下:

接下来我们在article.models.py中添加一个content字段
class Article(models.Model):
name = models.CharField(max_length=200)
content = models.CharField(max_length=200, null=True)
然后执行命令makemigrations article,会在项目中生成迁移文件0002_article_content.py,接着执行migrate article,执行迁移脚本,此时数据库中表django_migrations有3个迁移脚本

现在我们来模仿错误信息内容,我们将数据库中django_migrations表中的0002_article_content这行记录删除,然后我们来看下0002_article_content的代码
class Migration(migrations.Migration):
dependencies = [
('article', '0001_initial'),
]
operations = [
migrations.AddField(
model_name='article',
name='content',
field=models.CharField(max_length=200, null=True),
),
]
这个迁移脚本的作用是为article模型添加content字段,但是我们现在看一下article中的字段

从上图中我们可以清楚的看到article表中已经有了content字段,那么我们再执行migrate article命令时,就会报错,说content字段重复了,报错信息如下
django.db.utils.OperationalError: (1060, "Duplicate column name 'content'")
如果发生这种报错信息,解决办法是在migrate命名后添加参数--fake,--fake可以将指定的迁移脚本名字添加到数据库中。但是并不会把迁移脚本转换为SQL语句去修改数据库中的表
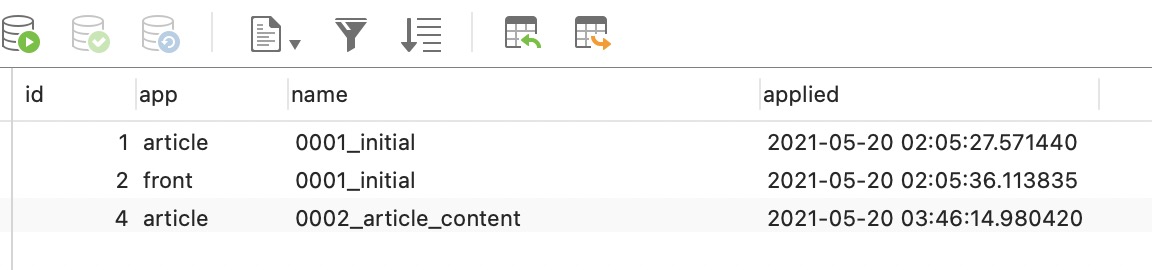
所以,我们可以执行命名migrate article --fake,会在django_migrations表中插入迁移脚本记录0002_article_content,如下图
此时数据库中表结构和django中的表结构完全一致,接下来执行迁移命令,就不会报错了
第一种报错情况总结
原因:执行migrate命令会报错的原因是。数据库的django_migrations表中的迁移版本记录和代码中的迁移脚本不一致导致的。
解决办法:使用--fake参数:首先对比数据库中的迁移脚本和代码中的迁移脚本。然后找到哪个不同,之后再使用--fake,将代码中的迁移脚本添加到django_migrations中,但是并不会执行sql语句。这样就可以避免每次执行migrate的时候,都执行一些重复的迁移脚本。
第二种报错情况
如果我们不管怎么执行migrate命令都会报错,那么就执行第二种方案
- 将出问题的app下的所有模型,都和数据库中的表保持一致。
- 将出问题的app下的所有迁移脚本文件都删掉。再在
django_migrations表中将出问题的app相关的迁移记录都删掉。 - 使用
makemigrations,重新将模型生成一个迁移脚本。 - 使用
migrate --fake-initial参数,将刚刚生成的迁移脚本,标记为已经完成(因为这些模型相对应的表,其实都已经在数据库中存在了,不需要重复执行了。) - 可以做其他的映射了。
Django(21)migrate报错的解决方案的更多相关文章
- Python Django migrate 报错解决办法
1. 在现有基础上又添加一个表的时候migrate报错 migrate报错django.db.utils.OperationalError: (1050, "Table 'cmdb_eidc ...
- django migrate报错(提前删除表等)
python3 manage.py makemigrations python3 manage.py migrate ##报错 改为##更改migrates的状态 python3 manage.py ...
- Django迁移数据库报错
Django迁移数据库报错 table "xxx" already exists错误 django在migrate时报错django migrate error: table 'x ...
- Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案
Mysql only_full_group_by以及其他关于sql_mode原因报错详细解决方案 网上太多相关资料,但是抄袭严重,有的讲的也是之言片语的,根本不连贯(可能知道的人确实不想多说) 我总共 ...
- 关于Entity Framework中的Attached报错相关解决方案的总结
关于Entity Framework中的Attached报错的问题,我这里分为以下几种类型,每种类型我都给出相应的解决方案,希望能给大家带来一些的帮助,当然作为读者的您如果觉得有不同的意见或更好的方法 ...
- 新手常见的python报错及解决方案
此篇文章整理新手编写代码常见的一些错误,有些错误是粗心的错误,但对于新手而已,会折腾很长时间才搞定,所以在此总结下我遇到的一些问题.希望帮助到刚入门的朋友们.后续会不断补充. 目录 1.NameErr ...
- django startproject xxx:报错UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 13: ordinal not in range(128)
django startproject xxx:报错UnicodeDecodeError: 'ascii' codec can't decode byte 0xe6 in position 13: o ...
- Win7下nginx默认80端口被System占用,造成nginx启动报错的解决方案
Win7下nginx默认80端口被System占用,造成nginx启动报错的解决方案 在win7 32位旗舰版下,启动1.0.8版本nginx,显示如下错误: [plain] 2012/04/0 ...
- Mac上PyCharm运行多进程报错的解决方案
Mac上PyCharm运行多进程报错的解决方案 运行时报错 may have been in progress in another thread when fork() was called. We ...
随机推荐
- IPFS矿池集群方案详解
IPFS作为一项分布式存储技术,可以说是web3.0发展的基石.关于IPFS的产业,如存储.技术.矿机.矿池等也发展得非常迅速. 什么是单机挖矿? 单机挖矿就是一台机器就是一个节点,一台机器就完成挖矿 ...
- 练习使用Unicorn、Capstone
Unicorn是一个轻量级的多平台,多体系结构的CPU仿真器框架.官网:http://www.unicorn-engine.org/ Capstone是一个轻量级的多平台,多体系结构的反汇编框架.官网 ...
- SQL排名问题,100% leetcode答案大公开!
(首先原谅我最近新番看多了,起了一个中二的名字) 最近在找实习,所以打算系统总结(复习)一下sql中经常遇到问题.不管是刷leetcode还是牛客的sql题,有一个问题总是绕不开的,那就是排名问题.其 ...
- Redis入门到放弃系列-redis安装
Redis是什么? Redis is an open source (BSD licensed), in-memory data structure store, used as a database ...
- Android学习之启动活动的最佳写法
•开始热身 通过之前的学习,我们现在可以很容易的启动一个活动: 首先通过 Intent 构造出当前的 "意图",然后调用 startActivity() 方法将活动启动起来: ...
- 亲测有效,解决80端口被svchost.exe进程占用的问题,网上的方法不行,可以试试这个
先说网上无效的方法(个人尝试无效,不具有代表性): 网上第一个说法:把IIS给关了,Windows10系统本身IIS是处于禁用状态的,并且没有额外安装IIS和启动IIS. 网上第二个说法:和SQL S ...
- java面试一日一题:java线程池
问题:请讲下java中的线程池 分析:在面试中经常问到线程池的问题,要掌握其基本概念,使用方法,注意事项等,引申下tomcat中默认的线程数是多少 回答要点: 主要从以下几点去考虑, 1.为什么要使用 ...
- java面试-G1垃圾收集器
一.以前收集器的特点 年轻代和老年代是各自独立且连续的内存块 年轻代收集器使用 eden + S0 + S1 进行复制算法 老年代收集必须扫描整个老年代区域 都是以尽可能的少而快速地执行 GC 为设计 ...
- .netcore 写快递100的快递物流信息查询接口
快递100的物流信息查询接口,官方提供了一些demo;还好官方提供的代码是.netcore版本写的,不过写的有点low;根据官方提供的代码,我按照.netcore 的风格重构了代码:核心代码如下: / ...
- 哈工大LTP基本使用-分词、词性标注、依存句法分析、命名实体识别、角色标注
代码 import os from pprint import pprint from pyltp import Segmentor, Postagger, Parser, NamedEntityRe ...