编程思想与算法leetcode_二分算法详解
二分算法通常用于有序序列中查找元素:
有序序列中是否存在满足某条件的元素;
有序序列中第一个满足某条件的元素的位置;
有序序列中最后一个满足某条件的元素的位置。
思路很简单,细节是魔鬼。
二分查找
一.有序序列中是否存在满足某条件的元素
首先,二分查找的框架:
def binarySearch(nums, target):
l = 0 #low
h = ... #high
while l...h:
m = (l + (h - l) / 2) #middle,防止h+l溢出
if nums[m] == target:
...
elif nums[m] < target:
l = ... #缩小边界
elif nums[m] > target:
h = ...
return ... #查找结果
其次,最基本的查找有序序列中的一个元素
def binarySearch(nums, target):
l = 0
h = len(nums) - 1 while l <= h :
m = (l + (h - l) / 2)
if nums[m] == target:
return m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m - 1
return -1
循环的条件为什么是 <=,而不是 < ?
答:要保证能遍历到数组的第一个元素和最后一个元素。因为初始化 h 的赋值是 len(nums) - 1,即最后一个元素的索引,而不是 len(nums)。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [l, h],后者相当于左闭右开区间 [l, h),因为索引大小为 len(nums) 是越界的。
我们这个算法中使用的是 [l, h] 两端都闭的区间。这个区间就是每次进行搜索的区间,我们不妨称为「搜索区间」(search space)。
此算法有什么缺陷?
答:至此,你应该已经掌握了该算法的所有细节,以及这样处理的原因。但是,这个算法存在局限性。
比如说给你有序数组 nums = [1,2,2,2,3],target = 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3,这样的话此算法是无法处理的。
这样的需求很常见。你也许会说,找到一个 target 索引,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的时间复杂度了。
我们后续的算法就来讨论这两种二分查找的算法。
二、寻找一个数(基本的二分搜索)
这个场景是最简单的,可能也是大家最熟悉的,即搜索一个数,如果存在,返回其索引,否则返回 -1。
def binarySearch([] nums, target):
l = 0
h = len(nums) - 1
while l <= h:
m = (l + (h - l) / 2)
if nums[m] == target:
return m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m - 1
return -1
1. 为什么 while 循环的条件中是 <=,而不是 < ?
答:因为初始化 h 的赋值是 len(nums) - 1,即最后一个元素的索引,而不是 len(nums)。
这二者可能出现在不同功能的二分查找中,区别是:前者相当于两端都闭区间 [l, h],后者相当于左闭右开区间 [l, h),因为索引大小为 len(nums) 是越界的。
我们这个算法中使用的是 [l, h] 两端都闭的区间。这个区间就是每次进行搜索的区间,我们不妨称为「搜索区间」(search space)。
什么时候应该停止搜索呢?当然,找到了目标值的时候可以终止:
if nums[m] == target
return m
但如果没找到,就需要 while 循环终止,然后返回 -1。那 while 循环什么时候应该终止?搜索区间为空的时候应该终止,意味着你没得找了,就等于没找到嘛。
while(l <= h)的终止条件是 l == h + 1,写成区间的形式就是 [h + 1, h],或者带个具体的数字进去 [3, 2],可见这时候搜索区间为空,因为没有数字既大于等于 3 又小于等于 2 的吧。所以这时候 while 循环终止是正确的,直接返回 -1 即可。
while(l < h)的终止条件是 l == h,写成区间的形式就是 [h, h],或者带个具体的数字进去 [2, 2],这时候搜索区间非空,还有一个数 2,但此时 while 循环终止了。也就是说这区间 [2, 2] 被漏掉了,索引 2 没有被搜索,如果这时候直接返回 -1 就可能出现错误。
当然,如果你非要用 while(l < h) 也可以,我们已经知道了出错的原因,就打个补丁好了:
#...
while l < h:
# ...
return nums[l] == target ? l : -1
2. 为什么 l = m + 1,h = m - 1?我看有的代码是 h = m 或者 l = m,没有这些加加减减,到底怎么回事,怎么判断?
答:这也是二分查找的一个难点,不过只要你能理解前面的内容,就能够很容易判断。
刚才明确了「搜索区间」这个概念,而且本算法的搜索区间是两端都闭的,即 [l, h]。那么当我们发现索引 m 不是要找的 target 时,如何确定下一步的搜索区间呢?
当然是去搜索 [l, m - 1] 或者 [m + 1, h] 对不对?因为 m 已经搜索过,应该从搜索区间中去除。
3. 此算法有什么缺陷?
答:至此,你应该已经掌握了该算法的所有细节,以及这样处理的原因。但是,这个算法存在局限性。
比如说给你有序数组 nums = [1,2,2,2,3],target = 2,此算法返回的索引是 2,没错。但是如果我想得到 target 的左侧边界,即索引 1,或者我想得到 target 的右侧边界,即索引 3,这样的话此算法是无法处理的。
这样的需求很常见。你也许会说,找到一个 target 索引,然后向左或向右线性搜索不行吗?可以,但是不好,因为这样难以保证二分查找对数级的时间复杂度了。
我们后续的算法就来讨论这两种二分查找的算法。
三、寻找左侧边界的二分搜索
直接看代码,其中的标记是需要注意的细节:
def l_bound(nums, target):
if len(nums) == 0 return -1
l = 0
h = len(nums)
while l < h
m = int(l + (h - l) / 2)
if nums[m] == target:
h = m
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m
return l
为什么 while(l < h) 而不是 <= ?
答:用相同的方法分析,因为初始化 h = len(nums) 而不是 len(nums) - 1 。因此每次循环的「搜索区间」是 [l, h) 左闭右开。
while(l < h) 终止的条件是 l == h,此时搜索区间 [l, l) 恰巧为空,所以可以正确终止。
为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
答:因为要一步一步来,先理解一下这个「左侧边界」有什么特殊含义:
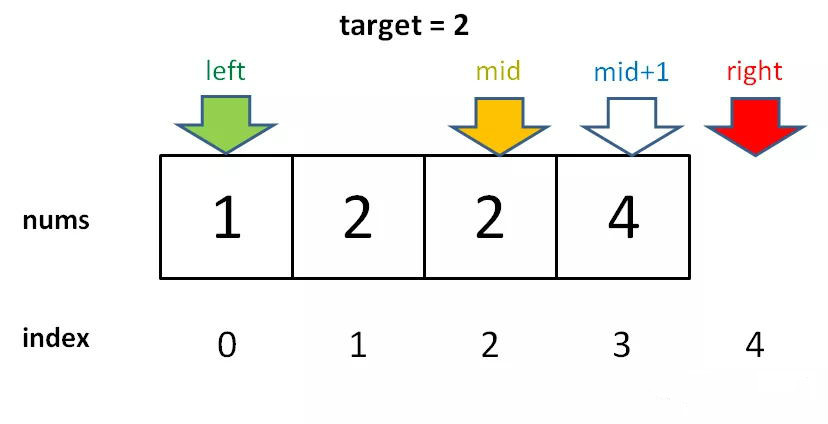
对于这个数组,算法会返回 1。这个 1 的含义可以这样解读:nums 中小于 2 的元素有 1 个。
比如对于有序数组 nums = [2,3,5,7], target = 1,算法会返回 0,含义是:nums 中小于 1 的元素有 0 个。如果 target = 8,算法会返回 4,含义是:nums 中小于 8 的元素有 4 个。
综上可以看出,函数的返回值(即 l 变量的值)取值区间是闭区间 [0, len(nums)],所以我们简单添加两行代码就能在正确的时候 return -1:
while l < h:
#...
# target 比所有数都大
if l == len(nums) return -1
# 类似之前算法的处理方式
return nums[l] == target ? l : -1
3. 为什么 l = m + 1,h = m ?和之前的算法不一样?
答:这个很好解释,因为我们的「搜索区间」是 [l, h) 左闭右开,所以当 nums[m] 被检测之后,下一步的搜索区间应该去掉 m 分割成两个区间,即 [l, m) 或 [m + 1, h)。
4. 为什么该算法能够搜索左侧边界?
答:关键在于对于 nums[m] == target 这种情况的处理:
if nums[m] == target:
h = m
可见,找到 target 时不要立即返回,而是缩小「搜索区间」的上界 h,在区间 [l, m) 中继续搜索,即不断向左收缩,达到锁定左侧边界的目的。
5. 为什么返回 l 而不是 h?
答:返回l和h都是一样的,因为 while 终止的条件是 l == h。
四、寻找右侧边界的二分查找
寻找右侧边界和寻找左侧边界的代码差不多,只有两处不同,已标注:
def h_bound(nums, target):
if len(nums) == 0 return -1
l = 0
h = len(nums)
while l < h:
m = int((l + h) / 2)
if nums[m] == target:
l = m + 1
elif nums[m] < target:
l = m + 1
elif nums[m] > target:
h = m
return l - 1
1. 为什么这个算法能够找到右侧边界?
答:类似地,关键点还是这里:
if nums[m] == target:
l = m + 1
当 nums[m] == target 时,不要立即返回,而是增大「搜索区间」的下界 l,使得区间不断向右收缩,达到锁定右侧边界的目的。
2. 为什么最后返回 l - 1 而不像左侧边界的函数,返回 l?而且我觉得这里既然是搜索右侧边界,应该返回 h 才对。
答:首先,while 循环的终止条件是 l == h,所以 l 和 h 是一样的,你非要体现右侧的特点,返回 h - 1 好了。
至于为什么要减一,这是搜索右侧边界的一个特殊点,关键在这个条件判断:
if nums[m] == target:
l = m + 1
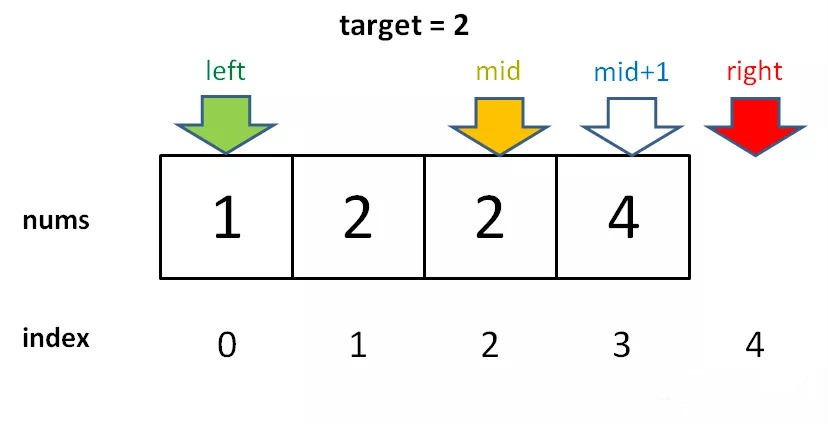
因为我们对 l 的更新必须是 l = m + 1,就是说 while 循环结束时,nums[l] 一定不等于 target 了,而 nums[l - 1]可能是target。
至于为什么 l 的更新必须是 l = m + 1,同左侧边界搜索,就不再赘述。
3. 为什么没有返回 -1 的操作?如果 nums 中不存在 target 这个值,怎么办?
答:类似之前的左侧边界搜索,因为 while 的终止条件是 l == h,就是说 l 的取值范围是 [0, len(nums)],所以可以添加两行代码,正确地返回 -1:
while l < h:
# ...
if l == 0 return -1
return nums[l-1] == target ? (l-1) : -1
五、最后总结
先来梳理一下这些细节差异的因果逻辑:
第一个,最基本的二分查找算法:
因为我们初始化 h = len(nums) - 1
所以决定了我们的「搜索区间」是 [l, h]
所以决定了 while (l <= h)
同时也决定了 l = m+1 和 h = m-1
因为我们只需找到一个 target 的索引即可
所以当 nums[m] == target 时可以立即返回
第二个,寻找左侧边界的二分查找:
因为我们初始化 h = len(nums)
所以决定了我们的「搜索区间」是 [l, h)
所以决定了 while (l < h)
同时也决定了 l = m+1 和 h = m
因为我们需找到 target 的最左侧索引
所以当 nums[m] == target 时不要立即返回
而要收紧右侧边界以锁定左侧边界
第三个,寻找右侧边界的二分查找:
因为我们初始化 h = len(nums)
所以决定了我们的「搜索区间」是 [l, h)
所以决定了 while (l < h)
同时也决定了 l = m+1 和 h = m
因为我们需找到 target 的最右侧索引
所以当 nums[m] == target 时不要立即返回
而要收紧左侧边界以锁定右侧边界
又因为收紧左侧边界时必须 l = m + 1
所以最后无论返回 l 还是 h,必须减一
如果以上内容你都能理解,那么恭喜你,二分查找算法的细节不过如此。
通过本文,你学会了:
1. 分析二分查找代码时,不要出现 else,全部展开成 elif 方便理解。
2. 注意「搜索区间」和 while 的终止条件,如果存在漏掉的元素,记得在最后检查。
3. 如需要搜索左右边界,只要在 nums[m] == target 时做修改即可。搜索右侧时需要减一。
就算遇到其他的二分查找变形,运用这几点技巧,也能保证你写出正确的代码。LeetCode Explore 中有二分查找的专项练习,其中提供了三种不同的代码模板,现在你再去看看,很容易就知道这几个模板的实现原理了。
编程思想与算法leetcode_二分算法详解的更多相关文章
- python 排序算法总结及实例详解
python 排序算法总结及实例详解 这篇文章主要介绍了python排序算法总结及实例详解的相关资料,需要的朋友可以参考下 总结了一下常见集中排序的算法 排序算法总结及实例详解"> 归 ...
- SSD算法及Caffe代码详解(最详细版本)
SSD(single shot multibox detector)算法及Caffe代码详解 https://blog.csdn.net/u014380165/article/details/7282 ...
- Partition算法以及其应用详解上(Golang实现)
最近像在看闲书一样在看一本<啊哈!算法> 当时在amazon上面闲逛挑书,看到巨多人推荐这本算法书,说深入浅出简单易懂便买来阅读.实际上作者描述算法的能力的确令人佩服.就当复习常用算法吧. ...
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
- Floyd算法(二)之 C++详解
本章是弗洛伊德算法的C++实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明出处:http://www.cnblogs.c ...
- 关联规则算法(The Apriori algorithm)详解
一.前言 在学习The Apriori algorithm算法时,参考了多篇博客和一篇论文,尽管这些都是很优秀的文章,但是并没有一篇文章详解了算法的整个流程,故整理多篇文章,并加入自己的一些注解,有了 ...
- KMP算法的优化与详解
文章开头,我首先抄录一些阮一峰先生关于KMP算法的一些讲解. 下面,我用自己的语言,试图写一篇比较好懂的 KMP 算法解释. 1. 首先,字符串"BBC ABCDAB ABCDABCDABD ...
- SSD(single shot multibox detector)算法及Caffe代码详解[转]
转自:AI之路 这篇博客主要介绍SSD算法,该算法是最近一年比较优秀的object detection算法,主要特点在于采用了特征融合. 论文:SSD single shot multibox det ...
- 算法笔记--sg函数详解及其模板
算法笔记 参考资料:https://wenku.baidu.com/view/25540742a8956bec0975e3a8.html sg函数大神详解:http://blog.csdn.net/l ...
随机推荐
- 搭建 MySQL 高可用高性能集群
什么是MySQL集群,什么是MySQL集群,如果你想知道什么是MySQL集群,我现在就带你研究. MySQL 是一款流行的轻量级数据库,很多应用都是使用它作为数据存储.作为小型应用的数据库,它完全可以 ...
- DOS命令行(11)——更多实用的命令行工具
start 启动另一个窗口运行指定的程序或命令,所有的DOS命令和命令行程序都可以由start命令来调用.该命令不仅能运行程序,还能运行协议对应的程序 命令格式:START ["title& ...
- Kubernetes之Ingress
在Service篇里面介绍了像集群外部的客户端公开服务的两种方法,还有另一种方法---创建Ingress资源. 定义Ingress (名词)-进入或进入的行为;进入的权利;进入的手段或地点;入口. 接 ...
- centos7 安装最新的 wiki confluence
41.1 下载confluence Confluence是一个企业级的Wiki,可用于企业.部门.团队内部进行信息共享和协同编辑. 下载地址: https://www.atlassian.com/so ...
- Docker入门与进阶(上)
Docker入门与进阶(上) 作者 刘畅 时间 2020-10-17 目录 1 Docker核心概述与安装 1 1.1 为什么要用容器 1 1.2 docker是什么 1 1.3 docker设计目标 ...
- 2、配置tomcat-service服务
1.将Tomcat设置成服务 (假设我们缺省的Tomcat目录为d:\Tomcat_oa) : 2.同时按住"win+r"键调出"运行",在方框内输入" ...
- sed 大括号 sed {} 的作用详解
今天看别人写的脚本的时候,看到了sed -r {} 我看网上对于这个的记录比较少,所以就写了这篇随笔. 先看一下效果 cat test.txt image: qqq/www/eee:TAG ...
- SpringBoot:SpringBoot中@Value注入失败
1. 第一步检测语法是否正确 @Value("${test}") private String test; 2.第二步检测配置文件中是否有进行配置 url=testusername ...
- shell 重定向以及文件描述符
1.对重定向的理解 Linux Shell 重定向分为两种,一种输入重定向,一种是输出重定向:从字面上理解,输入输出重定向就是「改变输入与输出的方向」的意思. 输入方向就是数据从哪里流向程序.标准输入 ...
- bugku flag在index里面
先点进去看看. 看到file,似乎在暗示着我们,php://filter/read/convert.base64-encode/resource=index.php, 这句将index.php内容用b ...