Java_冒泡排序_原理及优化
冒泡排序及其优化
一.原理及优化原理
1.原理讲解
冒泡排序即:第一个数与第二个数进行比较,如果满足条件位置不变,再把第二个数与第三个数进行比较.不满足条件则替换位置,再把第二个数与第三个数进行比较,以此类推,执行完为一个趟,趟数等于比较的个数减一.
2.冒泡排序原理图示:(以98765序列为例,排序结果从小到大)
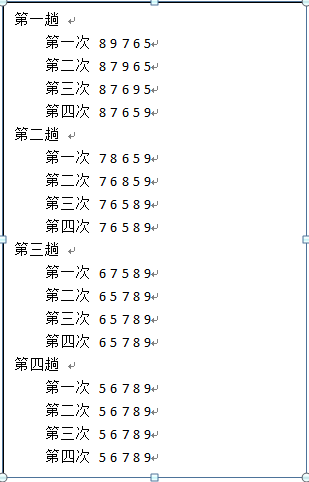
3.冒泡排序优化
优化版:每一次减少一次循环(即红色部分不需要在进行比较)

4.冒泡排序最终版
最终版:每一趟减少一次循环(删除线不需要再执行)

二.实现代码
1.冒泡排序实现主要代码
public static void main(String[] args) {
int []arr={9,8,7,6,5};
int len=arr.length;
for (int i=0;i<len-1;i++) {
for (int j=0;j<len-1;j++) {
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
System.out.println(Arrays.toString(arr));
}
冒泡排序实现代码
2.冒泡排序优化代码
public static void main(String[] args) {
int []arr={9,8,7,6,5,10};
int len=arr.length;
for (int i=0;i<len-1;i++) {
for (int j=0;j<len-1-i;j++) {
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
System.out.println(Arrays.toString(arr));
}
冒泡排序优化代码
3.冒泡排序最终代码
public static void main(String[] args) {
int []arr={9,8,7,6,5};
int len=arr.length;
for (int i=0;i<len-1;i++) {
System.out.println("第"+(i+1)+"趟");
//增加判断位
boolean flag=true;
for (int j=0;j<len-1-i;j++) {
System.out.println("第"+(j+1)+"次");
if(arr[j]>arr[j+1]){
int temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
flag=false;
}
System.out.println(Arrays.toString(arr));
}
//如果上面没有执行直接退出
if(flag){
break;
}
}
System.out.println(Arrays.toString(arr));
}
冒泡排序最终版
三.注意事项
1.多思考
Java_冒泡排序_原理及优化的更多相关文章
- Junit 注解 类加载器 .动态代理 jdbc 连接池 DButils 事务 Arraylist Linklist hashset 异常 哈希表的数据结构,存储过程 Map Object String Stringbufere File类 文件过滤器_原理分析 flush方法和close方法 序列号冲突问题
Junit 注解 3).其它注意事项: 1).@Test运行的方法,不能有形参: 2).@Test运行的方法,不能有返回值: 3).@Test运行的方法,不能是静态方法: 4).在一个类中,可以同时定 ...
- Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理 2017年01月04日 08:52:12 阅读数:18366 基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB ...
- [GO]冒泡排序的原理和代码实现
冒泡排序的原理:对于一个数组里所有的元素进行两两比较,发生大于则变换数组下标则为升序排序,发生小于则变换数据下标的则为降序排序 比如给定的数组为[1, -2, 3, -4],对于我们的需求,两两比较后 ...
- MySQL/MariaDB数据库的索引工作原理和优化
MySQL/MariaDB数据库的索引工作原理和优化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 实际工作中索引这个技术是影响服务器性能一个非常重要的指标,因此我们得花时间去了 ...
- jvm出现OutOfMemoryError时处理方法/jvm原理和优化参考
The heap stores all of the objects created by your java program.The heap's contents is monitored by ...
- Redis从出门到高可用--Redis复制原理与优化
Redis从出门到高可用–Redis复制原理与优化 单机有什么问题? 1.单机故障; 2.单机容量有瓶颈 3.单机有QPS瓶颈 主从复制:主机数据更新后根据配置和策略,自动同步到备机的master/s ...
- Nginx 笔记(四)nginx 原理与优化参数配置 与 nginx 搭建高可用集群
个人博客网:https://wushaopei.github.io/ (你想要这里多有) 一.nginx 原理与优化参数配置 master-workers 的机制的好处 首先,对于每个 ...
- Redis 入门到分布式 (七)Redis复制的原理与优化
一.目录 Redis复制的原理与优化 什么是主从复制 全量复制和部分复制 复制的配置 故障处理 开发运维常见问题 二. 什么是主从复制 1.单机有什么问题? 单机如果机器故障,那么久无法及时提供服务: ...
- InvalidClassException异常_原理和解决方案和练习_序列化集合
InvalidClassException异常_原理和解决方案 当JVM反序列化对象的时候,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个Inv ...
随机推荐
- CentOS6.2上安装pip
如果yum install pip执行失败.按如下步骤执行 首先安装epel扩展源: yum -y install epel-release 然后执行yum --disablerepo=epel -y ...
- redis启动出现错误creating server tcp listening socket 127.0.0.1:6379: bind No error
creating server tcp listening socket 127.0.0.1:6379: bind No error 的解决方案如下按顺序输入如下命令就可以连接成功 1. redis- ...
- MySQL--Double Write
##=======================================##目前大部分服务器使用4K或512B来格式化磁盘,而Innodb存储引擎使用默认16K的数据页,在写入16KB数据页 ...
- (爬虫向)python_json学习笔记
JSON学习笔记 - 在线工具 - https://www.sojson.com/ - http://www.w3school.com.cn/json/ - http://www.runoob.com ...
- IntelliJ IDEA 的下载和安装
下载 官网地址:https://www.jetbrains.com/idea/ 直接点击 DOWNLOAD 下载 接下来跳转到一个页面,可以看到第一个红框中是选择操作系统的,IDEA分为收费的旗舰版和 ...
- 数据结构图解(递归,二分,AVL,红黑树,伸展树,哈希表,字典树,B树,B+树)
递归反转 二分查找 AVL树 AVL简单的理解,如图所示,底部节点为1,不断往上到根节点,数字不断累加. 观察每个节点数字,随意选个节点A,会发现A节点的左子树节点或右子树节点末尾,数到A节点距离之差 ...
- Mysql学习笔记整理手册
目录 (1) str_to_date (2) 递归查询 (3) 排序问题 (4) 条件函数 (5) 列转行函数 (6) find_int_set (7) 类型转换函数 (8) 合并更新 继上一篇博客& ...
- Ubuntu 16.04 下octave的使用入门
SciLab和octave是开源的且免费的矩阵计算工具,二者都有希望成为矩阵计算的新宠.相比之下, octave与MatLab的兼容性更高. octave遵循GPL协议(GNU General Pub ...
- git使用方法----如何利用git管理代码?如何使用git将代码传到github中去
## 在文件夹中打开 git here; 1.git init ===初始化一个仓库(这个仓库会存放,git对我们代码进行备份的文件)2.配置个人信息 -- --在git中设置当前使用的用户是==( ...
- How JavaScript works: an overview of the engine, the runtime, and the call stack
https://blog.sessionstack.com/how-does-javascript-actually-work-part-1-b0bacc073cf