HBase Snapshot简介
一、简介
HBase 从0.95开始引入了Snapshot,可以对table进行Snapshot,也可以Restore到Snapshot。Snapshot可以在线做,也可以离线做。Snapshot的实现不涉及到table实际数据的拷贝,仅仅拷贝一些元数据,比如组成table的region info,表的descriptor,还有表对应的HFile的文件的引用。
Hbase snapshot功能让你对表进行快照而不对regionserver 产生太多影响。快照,克隆 和恢复操作不涉及数据拷贝。而且,将快照导出到其他集群也不会对regionserver有影响。
0.94之前的版本,备份或克隆的唯一方法就是利用 Copytable/ExportTable , 或在禁用表后复制HDFS中的所有hfiles。这些方法的缺点是你会降低regionserver的性能,或者你需要禁用表。那意味着不能读写,这在生产环境通常是不可接受的。
首先在配置项中打开snapshot
<property><name>hbase.snapshot.enabled</name><value>true</value></property>
创建一个snapshot
无论表是否可用,你都可以做快照。Snapshot操作不涉及到数据复制。
$ ./bin/hbase shellhbase> snapshot 'myTable', 'myTableSnapshot-122112'
默认的行为是在snapshot之前刷一遍内存中的数据。这意味着内存中的数据也包括在snapshot之中。大多数情况中,这是我们所希望的。然而,如果你的配置可以忍受内存中的数据没有刷进snapshot,你可以使用SKIP_FLUSH 选项来关闭。
没有办法确定或预测一个非常规并发的插入,更新将包括在给定的快照中,是否启用刷新。快照只是在时间窗口中的表的表示。
快照操作到达每个区域服务器所需的时间从几秒钟到一分钟不等,取决于资源负载和硬件或网络的速度,以及其他因素。也没有办法知道一个给定的插入或更新是在内存中还是被刷新。
列出snapshot
$ ./bin/hbase shellhbase> list_snapshots
删除snapshot
$ ./bin/hbase shellhbase> delete_snapshot 'myTableSnapshot-122112'
从snapshot 克隆一个表
从snapshot你可以创建一张数据与做snapshot时一样的新表。克隆操作,不涉及数据拷贝,修改克隆表也不影响snapshot和原始表。
$ ./bin/hbase shellhbase> clone_snapshot 'myTableSnapshot-122112', 'myNewTestTable'
恢复一张表
恢复操作需要表离线不可用,恢复操作将让表回到snapshot时的状态,同时改变数据和schema,如果必要的话。
$ ./bin/hbase shellhbase> disable 'myTable'hbase> restore_snapshot 'myTableSnapshot-122112'
输出到其他集群
$ bin/hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase -mappers 16
与其它集群的导出或导入
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \-snapshot MySnapshot -copy-to hdfs://srv2:8082/hbase \-chuser MyUser -chgroup MyGroup -chmod 700 -mappers 16hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot \-snapshot MySnapshot -copy-from hdfs://srv2:8082/hbase \-copy-to hdfs://srv1:50070/hbase \
用来改表名
hbase> disable 'tableName'hbase> snapshot 'tableName', 'tableSnapshot'hbase> clone_snapshot 'tableSnapshot', 'newTableName'hbase> delete_snapshot 'tableSnapshot'hbase> drop 'tableName'
二、原理解析
Snapshot之所以能在常数时间内完成,是因为它只是一组元数据(MetaData)的集合。Snapshot的操作都不需要复制任何业务数据。
首先我们要理解,HBase的底层存储文件HFile是什么,以及是怎么被生成的、怎么被删除的(或者叫生命周期)。其次就不难理解Snapshot为什么不需要复制业务数据了。
1. HFile是什么
HBase是一个Key-Value数据库,其基本数据操作(如Put、Delete等)最后都化归为Key-Value对,存储在HDFS的一个个文件(HFile)中: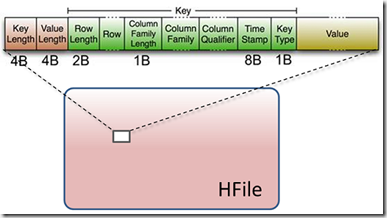
注意上图绿色的Key字段中,最后有个1 Byte的Key Type域,即是用来区分Put和Delete的。
另外更需注意的一点是,HBase的Delete操作并不是立即定位到目标数据将其删除或者做个删除标记,因为HDFS不支持这种随机写。Delete操作也跟Put一样存储,只是Key Type域不一样,以及Value域为空而已。HBase在读取时,会将拥有Delete操作的数据过滤掉。而具体何时删除目标数据,则是在对HFile做Compaction时。
2. HFile的两种生成方式
HFile有两种生成方式,分别是MemStore Flush和Compaction
- MemStore Flush
写操作(Put、Delete等)在WAL(Write-Ahead Log)提交成功后,马上会写入对应Region Server的内存缓冲区(MemStore)中。在MemStore里这些操作是按key排好序的。当MemStore写满时,就会将这些数据写入到HDFS中成为一个HFile。 - Compaction
HFile内部的数据是按key排好序的,但HFile之间的数据并不能保证key的顺序,也就是说,对于新生成的HFile,其里面的key值并不都比老的HFile的大。因此每次检索时,都需要在所有HFile中检索一次,再将结果合并。虽然HBase针对这个设计了各种加速机制(如Bloom Filter),但HFile文件数目一多还是会比较吃力,因此就需要对HFile做合并操作(Compaction)。Compaction分为minor和major两种级别,本质上都是从几个HFile生成合并后的HFile(类似于合并几个有序数组),然后,老的HFile被删除,起用合并后的HFile。
3. HFile何时会被删除
上面提到过的,在完成Compaction后,老的HFile就会被删除,起用合并后的HFile。
4. Snapshot操作的实现
细心的你是否发现了一个事实,HFile是不会被追加或者修改的!HFile一旦生成,就不会再被改变,只有被拿去合并后,生成了新的HFile,完成自己的使命时才会被删除。
那如果不删除呢?
比如说,我今天建了个表开始跑业务,这个表总共生成了10个HFile,每二天又生成一些HFile,并因此触发了合并操作,现在启用的HFile里有一些是老的没被合并的,有一些是新的由合并产生的。如果昨天那10个HFile还在,那我只要让这个表启用原来的这10个HFile,不就回滚到昨天的状态了嘛。依靠的是什么?就是这10个HFile自从诞生之后就不会被改动,连追加都不会。他们像琥珀一样,记录了这个表昨天的所有数据。
因此,建立Snapshot其实就是把当前所有启用的HFile文件名记录下来,并提醒系统在Compaction时不要删除它们。恢复Snapshot就是重新启用当时的那些HFile。当然这两句话说得不严谨,还有一些细节要处理,比如建Snapshot时要把内存里的东西也存下来先。具体是这样的:
建立Snapshot
1,Master与RegionServer同步,让他们同时进行MemStore flush
2,记录MetaData,即当前表有哪些region,每个region使用的HFile是哪些
3,“标记”HFile以防被删除
*建立Snapshot的过程不需要让表下线。恢复Snapshot
根据Snapshot对应的MetaData恢复各个region,该表需要先下线
总结
本文解析了为什么HBase的Snapshot操作只需要常数时间,不需要复制业务数据。其实说白了就一点,因为HFile生成之后只会被删除,不会被修改,连追加的修改都不会!
参考:
https://blog.csdn.net/zxln007/article/details/78921838
https://blog.csdn.net/huang_quanlong/article/details/50875567
HBase Snapshot简介的更多相关文章
- HBase Snapshot功能介绍
HBase在0.94之后提供了Snapshot功能,一个snapshot其实就是一组metadata信息的集合,它可以让管理员将表恢复到以前的一个状态.snapshot并不是一份拷贝,它只是一个文件名 ...
- hbase snapshot 表备份/恢复
snapshot其实就是一组metadata信息的集合,它可以让管理员将表恢复到以前的一个状态.snapshot并不是一份拷贝,它只是一个文件名的列表,并不拷贝数据.一个全的snapshot恢复以为着 ...
- HBase Snapshot原理和实现
HBase 从0.95开始引入了Snapshot,可以对table进行Snapshot,也可以Restore到Snapshot.Snapshot可以在线做,也可以离线做.Snapshot的实现不涉及到 ...
- Hbase snapshot数据迁移
# 在源集群中创建快照(linux shell) hbase snapshot -t <table_name> -n <snapshot_name> 或(hbase shell ...
- HBase技术简介
一.HBase简介 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. ...
- 大数据学习day11------hbase_day01----1. zk的监控机制,2动态感知服务上下线案例 3.HDFS-HA的高可用基本的工作原理 4. HDFS-HA的配置详解 5. HBASE(简介,安装,shell客户端,java客户端)
1. ZK的监控机制 1.1 监听数据的变化 (1)监听一次 public class ChangeDataWacher { public static void main(String[] arg ...
- 【HBase学习】Apache HBase项目简介
原创声明:转载请注明作者和原始链接 http://www.cnblogs.com/zhangningbo/p/4068957.html 英文原版:http://hbase.apache.o ...
- HBase(一)HBase入门简介
一 HBase 的起源 HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop 的子项目来开发维护,用于支持结构化的数据存储. Apache H ...
- hbase filter 简介
一.基本介绍 1.FilterList代表一个过滤器列表 FilterList.Operator.MUST_PASS_ALL --> 取交集 相当一and操作 FilterList.Operat ...
随机推荐
- @CrossOrigin注解与跨域访问
在Controller中看到@CrossOrigin ,这是什么?有什么用?为什么要用? what? @CrossOrigin是用来处理跨域请求的注解 先来说一下什么是跨域: (站在巨人的肩膀上) 跨 ...
- 搭建idea下的vue工程
需要先安装好nodejs和npm 输入下面的命令查看是否成功安装 node -v npm -v 一.开始 工作目录:IdeaProjects使用idea新建Static Web项目:demo 在dem ...
- 042、用volume container 共享数据 (2019-03-05 周二)
参考https://www.cnblogs.com/CloudMan6/p/7188479.html volume container 是专门为其他容器提供 volume 的容器,他提供的卷也可以 ...
- 开源框架.netCore DncZeus学习(一)npm安装
今天看到一个不错的开源项目DncZeus, https://github.com/lampo1024/DncZeus 整个界面挺漂亮,而且权限做到了按钮级别,功能也较容易扩展,刚好学习VUE纯看文章很 ...
- docker之搭建私有镜像仓库和公有仓库
一.搭建私有仓库 1.docker pull registry #下载registry镜像并启动 2. docker run -d -v /opt/registry:/var/lib/registry ...
- 理解PHP中的会话控制
会话控制是一种跟踪用户的通信方式,使用会话控制主要基于以下几点:由于http协议的无状态性,使得不能通过协议来建立两次请求之间的关联:对于通常的页面之间的数据传递方式get和post而言,主要处理参数 ...
- cuda、cuDNN的相关内容
1.nvidia与cuda需要满足关系: https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html/ 2.cuda与cudn ...
- 状压DP初探·总结
2018过农历新年这几天,学了一下状态压缩动态规划,现在先总结一下. 状态压缩其实是一种并没有改变dp本质的优化方法,阶段还是要照分,状态还是老样子,决策依旧要做,转移方程还是得列,最优还是最优, ...
- python web cgi
知识详解: cgi:通用网关接口,网络脚本的解析 python cgi 自带有cgi轻量级服务器,我们通过cgi命令可以开启该服务器 python2 python -m CGIHTTPServer p ...
- Kotlin中与Java不同的地方 需要注意
1. 在Kotlin中不会将基本数据类型的自动转型比如 scriptIntrinsicBlur.setRadius(25) //报错, 必须写成 25f 或者 调用.toFloat() 2.Kotli ...