【NLP】How to Generate Embeddings?
How to represent words.
0 .
Native represtation: one-hot vectors
Demision: |all words|
(too large and hard to express senmatic similarity)
Idea:produce dense vector representations based on the context/use of words
So, there are Three main approaches:
1.
Count-based methods
(1) Define a basis vocabulary C(lower than all words dimision) of context words(expect:the、a、of…)
(2) Define a word window size W
(3) Count the basis vocabulary words occurring W words to the left or right of each instance of a target word in the corpus
(4) From a vector represtation of the target word based on these counts
Example-express:


We can calculate the similarity of two words using inner product or cosine.
For instance.

2.
Neural Embedding Models(Main Idea)
To generate an embedding matrix in R(|all words| * |context words|) which looks like:
 (count based vectors)
(count based vectors)
Rows are word vectores.
We can retrieve a certain word vector with one-hot vector.

(One)generic idea behind embedding learning:
(1) Collect instances ti∈inst(t) of a word t of vocab V
(2) For each instance, collect its context word c(ti) (e.g.k-word window)
(3) Define some score function score(ti,c(ti),θ,E) with upper bound on output
(4) Define a loss

(5) Estimate:
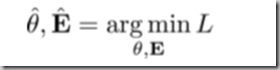
(6) Use the estimated E as the embedding matrix
Attention:
Scoring function estimates whether a sentence(or the object word and its context) is said or used normally by a people,so the higher the score,the more likely it is.
3.
C&W
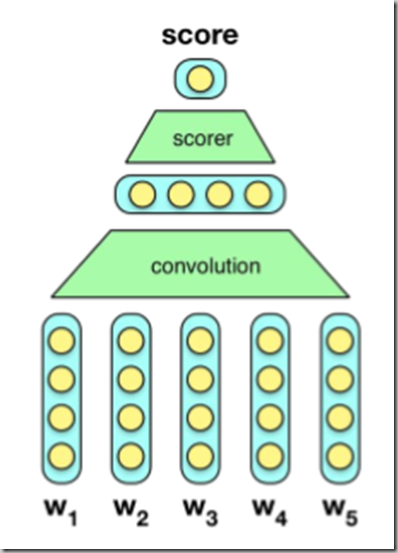
Firstly,we embed all words in a sentence with E.
Then,sentence(w1,w2,w3,w4,w5) goes through a convolution layer(maybe just simpal connection layer).
Then,it goes through a simpal MLP.
Then,it goes through the ‘scorer’layer and output the final Score.
Minimize the loss function(!),and use the parameter matrix of input layer and ..


4. Word2Vec
1) CBoW(contextual bag of words)
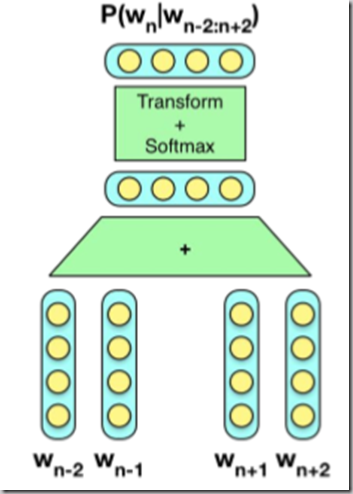

2) Skip-gram:


【NLP】How to Generate Embeddings?的更多相关文章
- 【NLP】前戏:一起走进条件随机场(一)
前戏:一起走进条件随机场 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有 ...
- 【NLP】基于自然语言处理角度谈谈CRF(二)
基于自然语言处理角度谈谈CRF 作者:白宁超 2016年8月2日21:25:35 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】基于机器学习角度谈谈CRF(三)
基于机器学习角度谈谈CRF 作者:白宁超 2016年8月3日08:39:14 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都 ...
- 【NLP】基于统计学习方法角度谈谈CRF(四)
基于统计学习方法角度谈谈CRF 作者:白宁超 2016年8月2日13:59:46 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务 ...
- 【NLP】条件随机场知识扩展延伸(五)
条件随机场知识扩展延伸 作者:白宁超 2016年8月3日19:47:55 [摘要]:条件随机场用于序列标注,数据分割等自然语言处理中,表现出很好的效果.在中文分词.中文人名识别和歧义消解等任务中都有应 ...
- 【NLP】Tika 文本预处理:抽取各种格式文件内容
Tika常见格式文件抽取内容并做预处理 作者 白宁超 2016年3月30日18:57:08 摘要:本文主要针对自然语言处理(NLP)过程中,重要基础部分抽取文本内容的预处理.首先我们要意识到预处理的重 ...
- [转]【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理 阅读目录
[NLP]干货!Python NLTK结合stanford NLP工具包进行文本处理 原贴: https://www.cnblogs.com/baiboy/p/nltk1.html 阅读目录 目 ...
- 【NLP】Conditional Language Models
Language Model estimates the probs that the sequences of words can be a sentence said by a human. Tr ...
- 【NLP】干货!Python NLTK结合stanford NLP工具包进行文本处理
干货!详述Python NLTK下如何使用stanford NLP工具包 作者:白宁超 2016年11月6日19:28:43 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的 ...
随机推荐
- 多个jdk 变更 引起 tomcat插件 启动不了 The JRE could not be found.Edit the server and change the JRE location.
The JRE could not be found.Edit the server and change the JRE location. 在Windows->Preferences-> ...
- 【C#复习总结】垃圾回收机制(GC)1
摘要:今天我们漫谈C#中的垃圾回收机制,本文将从垃圾回收机制的原理讲起,希望对大家有所帮助. GC的前世与今生 虽然本文是以.NET作为目标来讲述GC,但是GC的概念并非才诞生不久.早在1958年,由 ...
- Linux iptables 命令
iptables 是 Linux 管理员用来设置 IPv4 数据包过滤条件和 NAT 的命令行工具.iptables 工具运行在用户态,主要是设置各种规则.而 netfilter 则运行在内核态,执行 ...
- 六、Xadmin忘记密码
1.如果用的是django自带的User模块,忘记了超级用户的密码,可以通过以下方法找回密码: 终端进入项目根目录,然后输入如下命令: python manage.py shell 然后在python ...
- 剑指offer--4.重建二叉树
题目:输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树.假设输入的前序遍历和中序遍历的结果中都不含重复的数字.例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2, ...
- Krpano教程tour.xml详解
<krpano version="1.18" //版本号 onstart="" //网页启动时调用的函数 basedir="%FIRSTXML% ...
- H5 表单标签
33-表单标签3 列表数据 注意点: 1.下拉列表不能输入内容, 但是可以直接在列表中选择内容 2.可以通过给option标签添加一个selected属性来指定列表的默认值 3.可以通过给option ...
- Python编码与变量
(一)Python执行的方式 Window: 在CMD里面,使用 Python + 相对路径/绝对路径 在解释器里面,直接输入,一行代码一行代码的解释 Linux: 明确地指出用Python解释器来执 ...
- java中的代码块是什么意思,怎么用
代码块是一种常见的代码形式.他用大括号“{}”将多行代码封装在一起,形成一个独立的代码区,这就构成了代码块.代码块的格式如下: 方法/步骤 普通代码块:是最常见的代码块,在方法里用一对“{ ...
- IdentityServer4【Topic】之StartUp中的配置
Startup 身份服务器是中间件和服务的组合.所有的配置都是在启动类中完成的. Configuring services 通过调用如下代码在DI(dependency inject,依赖注入)中添加 ...