【NLP_Stanford课堂】情感分析
一、简介
实例:
- 电影评论、产品评论是positive还是negative
- 公众、消费者的信心是否在增加
- 公众对于候选人、社会事件等的倾向
- 预测股票市场的涨跌
Affective States又分为:
- emotion:短暂的情感,比如生气、伤心、joyful开心、害怕、羞愧、骄傲等
- mood:漫无原因的低强度长时间持续的主观感觉变化,比如cheerful,gloomy阴郁、irritable急躁、
- interpersonal stance:人际关系中对另一个人的立场,比如友好的、友善的
- attitude:态度,比如喜欢、讨厌
- personality trait:个性品质,比如鲁莽、焦虑
在情感分析中,我们针对的是attitude,分析的是:
- attitude的持有者(来源)
- attitude的目标(方面)
- attitude的类型:
- 来自一组类型:喜欢、爱、恨hate、重视value、渴望desire等
- 简单的带权重的极性:积极、消极和中性,均带有强度
- attitude的文本:句子或者整个文档
情感分析的任务:
- 简单任务:文本的attitude是积极还是消极
- 复杂任务:按照1-5对文本的attitude评级
- 高级任务:检查attitude的来源、目标或者复杂的attitude类型
二、基准算法

任务:极性检测:一部IMDB上的电影评论是积极还是消极
数据:Polarity Data 2.0: http://www.cs.cornell.edu/people/pabo/movie-review-data
步骤:
- Tokenization:将文本切分成词汇
- 特征提取
- 使用分类器分类:
- Naive Bayes
- MaxEnt
- SVM
1. Tokenization
需要应对:
- HTML和XML标记
- Twitter的标记(如,用户名、@)
- 大写单词(有时候需要保留)
- 电话号码、日期
- 表情符号
- 其他:

2. 特征提取
有效特征:
- 否定词
- 把在not后面直到下一个标点符号之间的词都加上NOT_,如下:

- 只选择形容词或者所有词(所有词的效果更好)
3. 二值多项式朴素贝叶斯
主要思想:在情感分析或者其他文本分类的任务中,认定一个词是否出现比起出现的频次更重要
训练过程:
- 将所有词的计数都重设为1
- 从训练语料中提取词汇表

- 将每个文档中的词去重,只保留一个实例
- 将所有属于docsj类别的文档都连接成一个文档得到Textj
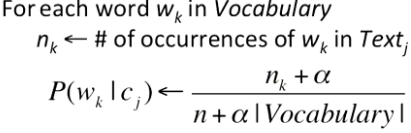
测试过程:
- 将测试文档中的词去重
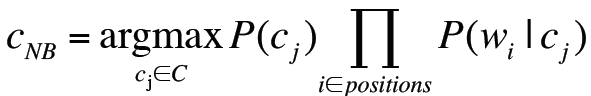
交叉验证:
- 将数据分成10组,每组内的测试集和训练集中positive和negative的比例一样
- 用前9组数据分别训练9个分类器,将最后一组数据完全作为测试集
- 以下是其中五组数据:

- 每组数据得到一个正确率,然后计算平均正确率
4. 难点
- 有些评论很隐晦,难以被分类器察觉
- 评论说的是原来自身的期望,然后说不符合期望,比如It should be brilliant,但是最后一句往往会说一句消极的话,所以语序也很重要
三、情感词典
词典中的每个词都存储了所属的情感。
1. 一般的情感词典
如下:





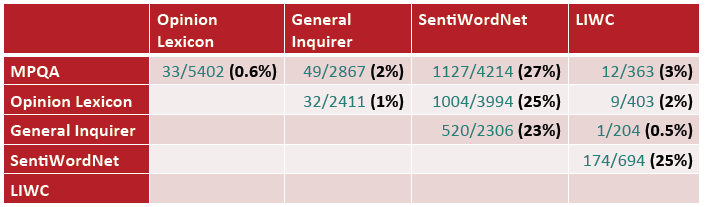
不同情感词典之间的同一个词极性的不一致性
2. 实例分析
分析IMDB中的每个词的极性
类别为1-10星,电影评论中都会附有星级评价,用这个来做类别,然后分析每个评论中的词,用以确定每个词的极性。
同一个词“bad”在不同的星级下计数如下:
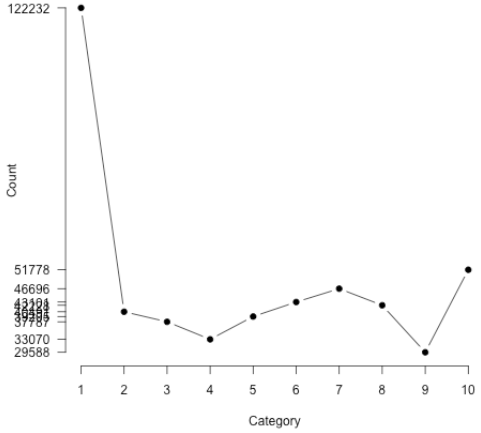
可以发现1星最多,这也是因为1星的评价最多,所以我们不能直接用这个来确定极性,而是用如下计算:
最大似然估计: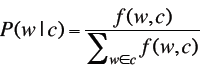
不同词之间的比较使用范围最大似然估计Scaled likelihood: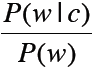
具体分析不同词在不同星级下的范围最大似然估计如下:
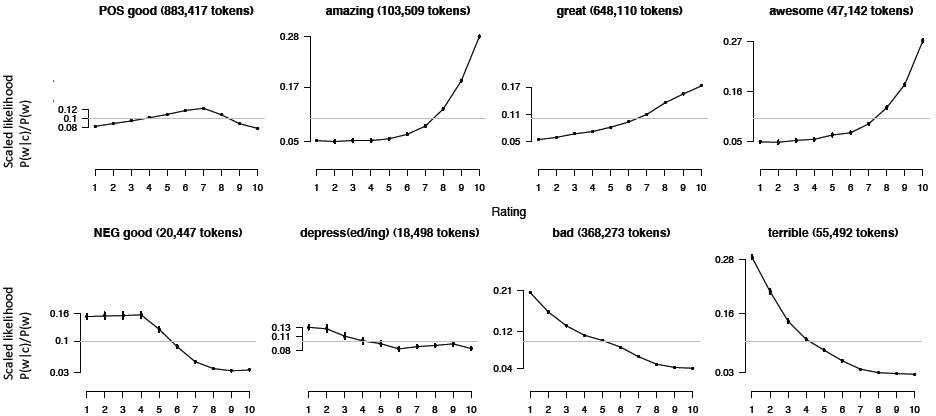
可以发现amazing和awesome在高分星级上出现的比较多,而bad和terrible在低分星级上出现较多
其他情感特征:否定词(no, not)
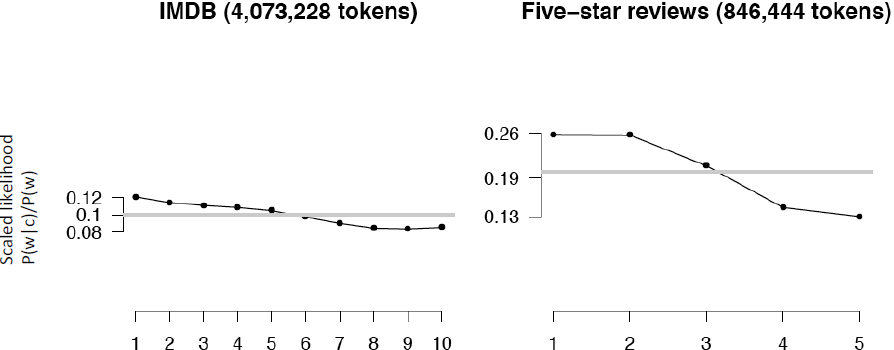
可以发现否定词在低分星级上出现的比较多
四、建立情感词典
主要使用半监督学习
- 先使用一个小的数据集,可能是
- 一些带标签的实例
- 一些手动建立的模式
- 然后建立一个词典
1. 基准算法
基本思想:源于

- 如果两个形容词用“and”连接,那么他们有相同的极性
- 如果用“but"连接,那么他们有相反的极性
步骤:
- 手动标记一个包括1336个形容词的种子数据集,其中有657个词是positive,679个词是negative
- 通过连接的形容词来扩展种子数据集。
- 比如使用Google:
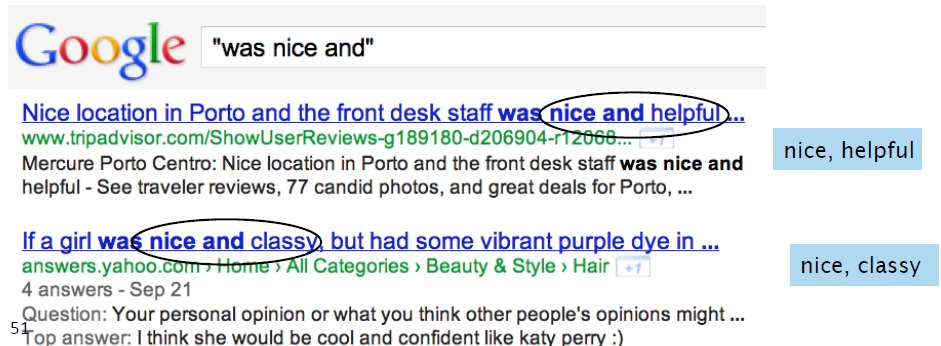
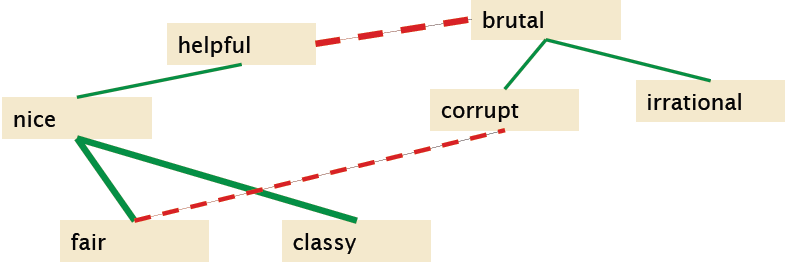
- 建立一个有监督的分类器,用以给每个词对分配极性相似性,即两个词极性上有多相似,主要使用count(AND)和count(BUT)。得到如下示意图:
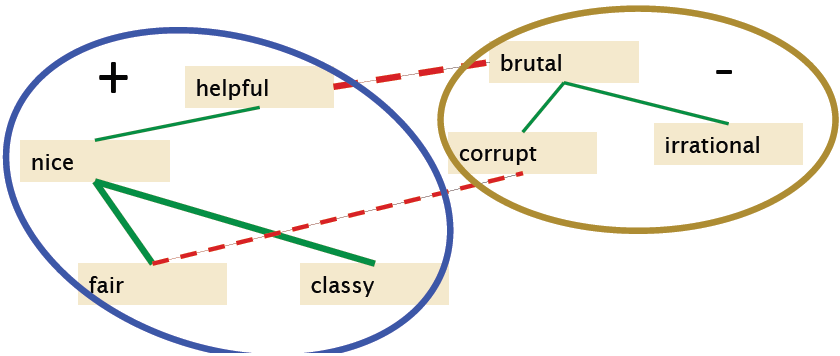
- 将上图聚类成两堆,分别为positive和negative,如下:
- 输出极性的词典:positive和negative

以上是针对形容词,下面介绍一种针对短语的词典的建立方法Turney Algorithm。
2. Turney算法
步骤类似,如下:
- 从评论中提取建立一个短语词典
- 将有如下词性组合的两个词都作为一个短语:
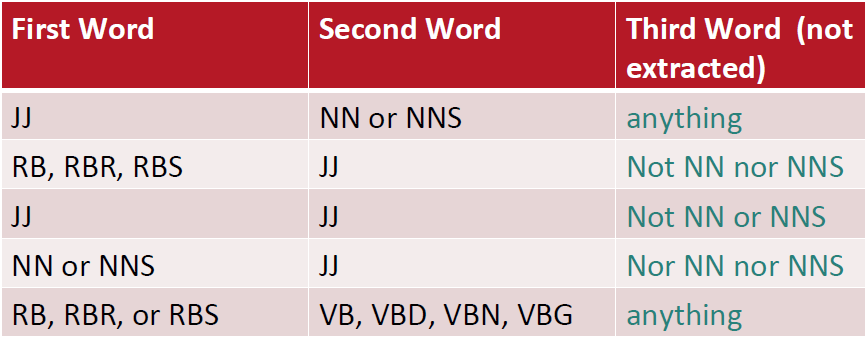 ,其中JJ表示形容词,NN表示名词,NNS表示复数形式的名词
,其中JJ表示形容词,NN表示名词,NNS表示复数形式的名词
- 将有如下词性组合的两个词都作为一个短语:
- 学习每个短语的词性:使用点间互信息PMI,基本思想也是使用两个词“and”共现的词的计数
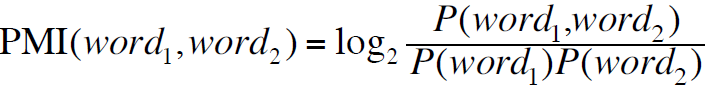
- 如何预估PMI:使用查询机制,类似于上述的搜索Google:
- 然后计算一个短语的极性:
- 对一个评论,计算其中的短语的平均极性,再评级
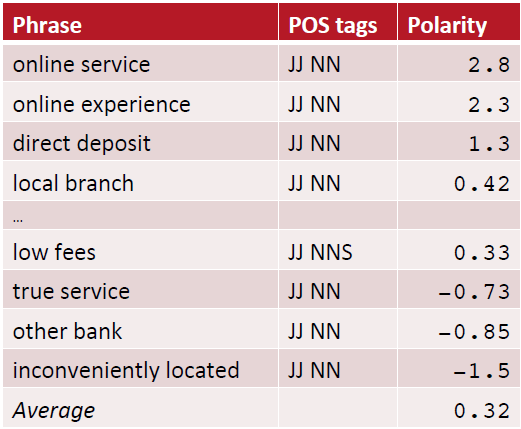
- 一个评论结果如下:
- 一个评论结果如下:

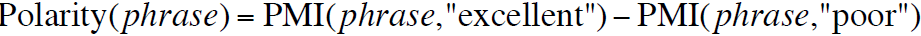
Turney Algorithm结果如下:

可以发现Turney算法比起基准算法更准确,或许是因为
- 短语比起单个词更准确
- Turney算法可以学到特定领域的信息
3. 使用WordNet学习极性
WordNet:在线同义词词典
步骤:
- 创建positive和negative的种子词典(“good”和“terrible”)
- 找到各种子词典里的同义词和反义词
- 重复以上步骤
- 过滤
五、其他情感分析任务
【NLP_Stanford课堂】情感分析的更多相关文章
- 朴素贝叶斯算法下的情感分析——C#编程实现
这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Language Pr ...
- Stanford NLP学习笔记:7. 情感分析(Sentiment)
1. 什么是情感分析(别名:观点提取,主题分析,情感挖掘...) 应用: 1)正面VS负面的影评(影片分类问题) 2)产品/品牌评价: Google产品搜索 3)twitter情感预测股票市场行情/消 ...
- 情感分析的现代方法(包含word2vec Doc2Vec)
英文原文地址:https://districtdatalabs.silvrback.com/modern-methods-for-sentiment-analysis 转载文章地址:http://da ...
- SA: 情感分析资源(Corpus、Dictionary)
先主要摘自一篇中文Survey,http://wenku.baidu.com/view/0c33af946bec0975f465e277.html 4.2 情感分析的资源建设 4.2.1 情感分析 ...
- 爬虫再探实战(五)———爬取APP数据——超级课程表【四】——情感分析
仔细看的话,会发现之前的词频分析并没有什么卵用...文本分析真正的大哥是NLP,不过,这个坑太大,小白不大敢跳...不过还是忍不住在坑边上往下瞅瞅2333. 言归正传,今天刚了解到boson公司有py ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- C#编程实现朴素贝叶斯算法下的情感分析
C#编程实现 这篇文章做了什么 朴素贝叶斯算法是机器学习中非常重要的分类算法,用途十分广泛,如垃圾邮件处理等.而情感分析(Sentiment Analysis)是自然语言处理(Natural Lang ...
- R语言做文本挖掘 Part5情感分析
Part5情感分析 这是本系列的最后一篇文章,该.事实上这种单一文本挖掘的每一个部分进行全部值获取水落石出细致的研究,0基础研究阶段.用R里面现成的算法,来实现自己的需求,当然还參考了众多网友的智慧结 ...
- 如何科学地蹭热点:用python爬虫获取热门微博评论并进行情感分析
前言:本文主要涉及知识点包括新浪微博爬虫.python对数据库的简单读写.简单的列表数据去重.简单的自然语言处理(snowNLP模块.机器学习).适合有一定编程基础,并对python有所了解的盆友阅读 ...
随机推荐
- 股神 C++
题目描述 有股神吗? 有,小赛就是! 经过严密的计算,小赛买了一支股票,他知道从他买股票的那天开始,股票会有以下变化:第一天不变,以后涨一天,跌一天,涨两天,跌一天,涨三天,跌一天...依此类推. 为 ...
- CSAPP阅读笔记-存储器层次结构-第六章-P400-P462
6.1 存储技术 1.随机访问存储器(RAM),是易失性存储器,掉电存储信息会丢失,与之相对的是非易失性存储器(ROM),它掉电后存储信息不丢失,但前者访问速度较快,但容量有限,通常只有几百或几千兆字 ...
- 查看SqlServer某张表的物理空间占用情况
以下语句可以查看表的物理空间使用情况 包括 [ROWS] 内容的行数.. [reserved] 保留的磁盘大小.. [data] 数据占用的磁盘大小.. [index_size] 索引占用的磁盘大小. ...
- XML 十六进制值 是无效的字符错误 解决方法之一 转
/// <summary> /// 过滤非打印字符 /// </summary> /// <param name="tmp">待过滤</p ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- JVM的内存结构
程序计数器 程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器.字节码解释器工作时就是通过改变这个计数器的值来选取下一条 ...
- wcf 登录认证 angular 认证重定向
自定义认证管理器,分为两级:1.登陆认证.2.权限认证.权限主要是用户.角色.角色用户关系.功能(系统资源).角色功能关系,5部分决定用户的权限(视图). 两层认证都通过后,更新session的最新交 ...
- 微信小程序 三元运算 checked
预期效果: 根据用户性别,显示radio group,并将相应radio checked 代码如下: <view class="form-line"> <v ...
- redis(9)集群搭建
一.搭建流程 以下我们将构建这样一个redis集群:三个主节点,分别备有一个从节点,主节点之间相互通信,如果主节点挂掉,从节点将被提升为主节点. redis集群至少需要3个redis实例 那么我们需要 ...
- centos top 命令详解及退出top命令-使用p键及free命令
1.作用 top命令用来显示执行中的程序进程,使用权限是所有用户. 2.格式 top [-] [d delay] [q] [c] [S] [s] [i] [n] 3.主要参数 d:指定更新的间隔,以秒 ...