爬虫入门【10】Pyspider框架简介及安装说明
Pyspider是python中的一个很流行的爬虫框架系统,它具有的特点如下:
1、可以在Python环境下写脚本
2、具有WebUI,脚本编辑器,并且有项目管理和任务监视器以及结果查看。
3、支持多种数据库
4、支持定义任务优先级,自动重试链接。。。
5、分布式架构
等等优点。
pyspider的设计基础是:以python脚本驱动的抓取环模型爬虫。
教程: http://docs.pyspider.org/en/latest/tutorial/
文档: http://docs.pyspider.org/
发布版本: https://github.com/binux/pyspider/releases
入门范例
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
【插入图片,Pyspider界面】
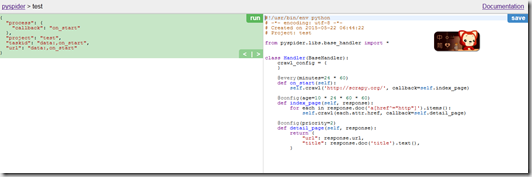
代码简单介绍
def on_start(self):
这是脚本的入口节点,当我们点击run的时候,程序会自动调用这个函数。
self.crawl(url, callback=self.index_page):
这时最重要的API,将会添加新任务,大部分选项使用crawl的参数来指定。
def index_page(self, response):
这个方法得到一个response对象,然后通过PyQuery的doc命令来解析。
def detail_page(self, response):
返回一个dict对象作为结果。这个结果可以保存到数据库中。
我们还可以在脚本中自定义函数或者对象。
【插入图片,运行界面】
安装
推荐使用Pycharm,在Project Interpreter里面添加pyspider,目前最新的版本是0.3.9.
或者使用pip命令安装。
今天来不及把整个项目内容讲完了,明天继续。
爬虫入门【10】Pyspider框架简介及安装说明的更多相关文章
- 爬虫基础(五)-----scrapy框架简介
---------------------------------------------------摆脱穷人思维 <五> :拓展自己的视野,适当做一些眼前''无用''的事情,防止进入只关 ...
- 爬虫开发7.scrapy框架简介和基础应用
scrapy框架简介和基础应用阅读量: 1432 scrapy 今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数 ...
- 10.scrapy框架简介和基础应用
今日概要 scrapy框架介绍 环境安装 基础使用 今日详情 一.什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被 ...
- python爬虫入门(六) Scrapy框架之原理介绍
Scrapy框架 Scrapy简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬 ...
- 爬虫入门之Scrapy 框架基础功能(九)
Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非 ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- 人工智能 tensorflow框架-->简介及安装01
简介:Tensorflow是google于2015年11月开源的第二代机器学习框架. Tensorflow名字理解:图形边中流动的数据叫张量(Tensor),因此叫Tensorflow 既 张量流动 ...
- 爬虫入门之Scrapy框架实战(新浪百科豆瓣)(十二)
一 新浪新闻爬取 1 爬取新浪新闻(全站爬取) 项目搭建与开启 scrapy startproject sina cd sina scrapy genspider mysina http://roll ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
随机推荐
- res与res-auto的区别
Solution: Upgrade to latest SDK & ADT version (fixed was released since r17) and usehttp://schem ...
- C++ opencv高速样例学习——读图显示
1.关键函数 1. 读入图片 imread(图片或位置,显示格式)默觉得:IMREAD_COLOR 显示格式: IMREAD_UNCHANGED =-1 // 8bit, color or no ...
- APP消息推送功能
1.APP内部最好设计-我的消息-的功能,以便用户查看推送消息历史记录,通过角标.已读.未读等设计吸引用户读取消息.(画下来这都是重点) 2.建议提供推送设置功能,允许用户设置推送消息是否显示于通知栏 ...
- html5_storage存取实例
<script src="jquery-1.8.3.js"></script><script>function set(){ var tt ...
- ajax 上传图片
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- mysql-group-replication 测试环境的搭建与排错
mysql-group-replication 是由mysql-5.7.17这个版本提供的强一致的高可用集群解决方案 1.环境规划 主机ip 主机名 172.16.192.201 balm001 17 ...
- object-c全局变量
跟c++一定,在.m里Obj*obj=NULL,在.h里extern Obj*obj 即可.
- unity, UGUI Text outline
UGUI Text的勾边效果是通过添加component实现的: Add Component->UI->Effects->Outline 参考:http://www.cnblogs. ...
- 点滴积累【JS】---JS小功能(JS实现排序)
效果: 思路: 首先,获得用到的ID,在把得到的<li>数组添加到array数组里面,然后在进行array排序,排序完后再将array中的数据用appendChild添加到ul里面: 代码 ...
- Docker Python API 与 Docker Command
span.kw { color: #007020; font-weight: bold; } code > span.dt { color: #902000; } code > span. ...