Consistent hashing —— 一致性哈希
原文地址:http://www.codeproject.com/Articles/56138/Consistent-hashing
基于BSD License
What is libconhash
libconhash is a consistent hashing library which can be compiled both on Windows and Linux platforms, with the following features:
- High performance and easy to use, libconhash uses a red-black tree to manage all nodes to achieve high performance.
- By default, it uses the MD5 algorithm, but it also supports user-defined hash functions.
- Easy to scale according to the node's processing capacity.
Consistent hashing
Why you need consistent hashing
Now we will consider the common way to do load balance. The machine number chosen to cache object o will be:
hash(o) mod n
Here, n is the total number of cache machines. While this works well until you add or remove cache machines:
- When you add a cache machine, then object o will be cached into the machine:
hash(o) mod (n+1)
- When you remove a cache machine, then object o will be cached into the machine:
hash(o) mod (n-1)
So you can see that almost all objects will hashed into a new location. This will be a disaster since the originating content servers are swamped with requests from the cache machines. And this is why you need consistent hashing.
Consistent hashing can guarantee that when a cache machine is removed, only the objects cached in it will be rehashed; when a new cache machine is added, only a fairly few objects will be rehashed.
Now we will go into consistent hashing step by step.
Hash space
Commonly, a hash function will map a value into a 32-bit key, 0~2^32-1. Now imagine mapping the range into a circle, then the key will be wrapped, and 0 will be followed by 2^32-1, as illustrated in figure 1.

Map object into hash space
Now consider four objects: object1~object4. We use a hash function to get their key values and map them into the circle, as illustrated in figure 2.

hash(object1) = key1;
.....
hash(object4) = key4;
Map the cache into hash space
The basic idea of consistent hashing is to map the cache and objects into the same hash space using the same hash function.
Now consider we have three caches, A, B and C, and then the mapping result will look like in figure 3.
hash(cache A) = key A;
....
hash(cache C) = key C;

Map objects into cache
Now all the caches and objects are hashed into the same space, so we can determine how to map objects into caches. Take object obj for example, just start from where obj is and head clockwise on the ring until you find a server. If that server is down, you go to the next one, and so forth. See figure 3 above.
According to the method, object1 will be cached into cache A; object2 and object3 will be cached into cache C, and object4 will be cached into cache B.
Add or remove cache
Now consider the two scenarios, a cache is down and removed; and a new cache is added.
If cache B is removed, then only the objects that cached in B will be rehashed and moved to C; in the example, see object4 illustrated in figure 4.

If a new cache D is added, and D is hashed between object2 and object3 in the ring, then only the objects that are between D and B will be rehashed; in the example, see object2, illustrated in figure 5.

Virtual nodes
It is possible to have a very non-uniform distribution of objects between caches if you don't deploy enough caches. The solution is to introduce the idea of "virtual nodes".
Virtual nodes are replicas of cache points in the circle, each real cache corresponds to several virtual nodes in the circle; whenever we add a cache, actually, we create a number of virtual nodes in the circle for it; and when a cache is removed, we remove all its virtual nodes from the circle.
Consider the above example. There are two caches A and C in the system, and now we introduce virtual nodes, and the replica is 2, then three will be 4 virtual nodes. Cache A1 and cache A2 represent cache A; cache C1 and cache C2 represent cache C, illustrated as in figure 6.

Then, the map from object to the virtual node will be:
objec1->cache A2; objec2->cache A1; objec3->cache C1; objec4->cache C2
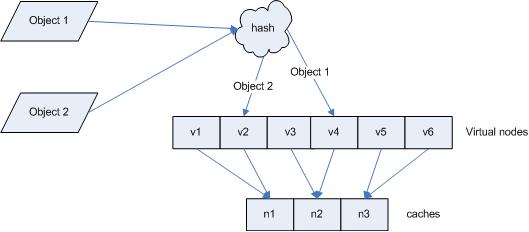
When you get the virtual node, you get the cache, as in the above figure.
So object1 and object2 are cached into cache A, and object3 and object4 are cached into cache. The result is more balanced now.
So now you know what consistent hashing is.
Using the code
Interfaces of libconhash
/* initialize conhash library
* @pfhash : hash function, NULL to use default MD5 method
* return a conhash_s instance
*/
CONHASH_API struct conhash_s* conhash_init(conhash_cb_hashfunc pfhash); /* finalize lib */
CONHASH_API void conhash_fini(struct conhash_s *conhash); /* set node */
CONHASH_API void conhash_set_node(struct node_s *node,
const char *iden, u_int replica); /*
* add a new node
* @node: the node to add
*/
CONHASH_API int conhash_add_node(struct conhash_s *conhash,
struct node_s *node); /* remove a node */
CONHASH_API int conhash_del_node(struct conhash_s *conhash,
struct node_s *node);
... /*
* lookup a server which object belongs to
* @object: the input string which indicates an object
* return the server_s structure, do not modify the value,
* or it will cause a disaster
*/
CONHASH_API const struct node_s*
conhash_lookup(const struct conhash_s *conhash,
const char *object);
Libconhash is very easy to use. There is a sample in the project that shows how to use the library.
First, create a conhash instance. And then you can add or remove nodes of the instance, and look up objects.
The update node's replica function is not implemented yet.
/* init conhash instance */
struct conhash_s *conhash = conhash_init(NULL);
if(conhash)
{
/* set nodes */
conhash_set_node(&g_nodes[0], "titanic", 32);
/* ... */ /* add nodes */
conhash_add_node(conhash, &g_nodes[0]);
/* ... */
printf("virtual nodes number %d\n", conhash_get_vnodes_num(conhash));
printf("the hashing results--------------------------------------:\n"); /* lookup object */
node = conhash_lookup(conhash, "James.km");
if(node) printf("[%16s] is in node: [%16s]\n", str, node->iden);
}
Reference
License
This article, along with any associated source code and files, is licensed under The BSD License
Consistent hashing —— 一致性哈希的更多相关文章
- hash环/consistent hashing一致性哈希算法
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似.一致性哈希修正了CARP使用的 ...
- consistent hash(一致性哈希算法)
一.产生背景 今天咱不去长篇大论特别详细地讲解consistent hash,我争取用最轻松的方式告诉你consistent hash算法是什么,如果需要深入,Google一下~. 举个栗子吧: 比如 ...
- 一致性哈希算法(consistent hashing)(转)
原文链接:每天进步一点点——五分钟理解一致性哈希算法(consistent hashing) 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网 ...
- 一致性哈希算法学习及JAVA代码实现分析
1,对于待存储的海量数据,如何将它们分配到各个机器中去?---数据分片与路由 当数据量很大时,通过改善单机硬件资源的纵向扩充方式来存储数据变得越来越不适用,而通过增加机器数目来获得水平横向扩展的方式则 ...
- 一致性哈希算法与Java实现
原文:http://blog.csdn.net/wuhuan_wp/article/details/7010071 一致性哈希算法是分布式系统中常用的算法.比如,一个分布式的存储系统,要将数据存储到具 ...
- Consistent Hashing算法
前几天看了一下Memcached,看到Memcached的分布式算法时,知道了一种Consistent Hashing的哈希算法,上网搜了一下,大致了解了一下这个算法,做下记录. 数据均衡分布技术在分 ...
- _00013 一致性哈希算法 Consistent Hashing 新的讨论,并出现相应的解决
笔者博文:妳那伊抹微笑 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最遥远的距离不是天涯,也不是海角,而是我站在妳的面前.妳却感觉不到我的存在 技术方向: ...
- 深入一致性哈希(Consistent Hashing)算法原理,并附100行代码实现
转自:https://my.oschina.net/yaohonv/blog/1610096 本文为实现分布式任务调度系统中用到的一些关键技术点分享——Consistent Hashing算法原理和J ...
- (转)每天进步一点点——五分钟理解一致性哈希算法(consistent hashing)
背景:在redis集群中,有关于一致性哈希的使用. 一致性哈希:桶大小0~(2^32)-1 哈希指标:平衡性.单调性.分散性.负载性 为了提高平衡性,引入“虚拟节点” 每天进步一点点——五分钟理解一致 ...
随机推荐
- SQLServer的数据存储结构01 文件与文件组
在SQLServer中,每当新建一个数据库时,则会有一组相应的SQLServer文件被创建,这些单独的SQLServer文件构成的总体称为文件组. 一个数据库对应着一个文件组,在这个文件组里,会包括三 ...
- TestNG BeforeClass BeforeMethod Test AfterClass AfterMethod
http://topmanopensource.iteye.com/blog/1983729 1.TestNG测试注解和Junit注解的不同以及生命周期: TestNG测试的一个方法的生命周期: @B ...
- 关于unity碰撞检测器的用法
今天已经是我第三次忘记了这两种碰撞检测的用法,混淆了.特意整理一下 首先把今天要解决涉及到的东西列出来 碰撞方法: public void OnTriggerEnter(Collider other) ...
- Brew安装MacVim
brew install macvim --with-cscope --with-lua --with-python cscope lua python支持 附一些简单的brew命令 查看brew的帮 ...
- 简单谈一谈JavaScript中的变量提升的问题
1,随笔由来 第一天开通博客,用于监督自己学习以及分享一点点浅见,不出意外的话,应该是一周一更或者一周两更. 此博客所写内容主要为前端工作中遇上的一些问题以及常见问题,在此基础上略微发表自己的一点浅 ...
- 本地搭建PHP环境后进入应用失败
进入localhost/wordpress或者其他应用,直接出现类似以下这种情况: 解决方法是修改tomcat的配置文件httpd.conf中: <IfModule dir_module> ...
- web sql database数据存储位置
Q1: 数据存储在哪儿? Web Storage / Web SQL Database / Indexed Database 的数据都存储在浏览器对应的用户配置文件目录(user profile di ...
- SAP连接电脑串口读数(电子称,磅等数据读取)
这是几年前做的了,一直都不想分享出来,后来想想为了能够给大家点想法,献出来了... 这是一个电脑读称的方法,一般用COMM口连接的电子设备都可参考. 如果是对串口参数不确定的,可以网上找个串口测试工具 ...
- H5瀑布流如何实现
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 安装Windows 7
-EndFragment--> 1.安装win7_64位步骤: https://www.douban.com/note/224102684/ 安装Win7系统为硬盘分区的方法 笨小康2012-0 ...