Hive SQL 监控系统 - Hive Falcon
1.概述
在开发工作当中,提交 Hadoop 任务,任务的运行详情,这是我们所关心的,当业务并不复杂的时候,我们可以使用 Hadoop 提供的命令工具去管理 YARN 中的任务。在编写 Hive SQL 的时候,需要在 Hive 终端,编写 SQL 语句,来观察 MapReduce 的运行情况,长此以往,感觉非常的不便。另外随着业务的复杂化,任务的数量增加,此时我们在使用这套流程,已预感到力不从心,这时候 Hive 的监控系统此刻便尤为显得重要,我们需要观察 Hive SQL 的 MapReduce 运行详情以及在 YARN 中的相关状态。
因此,我们经过调研,从互联网公司的一些需求出发,从各位 DEVS 的使用经验和反馈出发,结合业界的一些大的开源的 Hadoop SQL 消息监控,用监控的一些思考出发,设计开发了现在这样的监控系统:Hive Falcon。
Hive Falcon 用于监控 Hadoop 集群中被提交的任务,以及其运行的状态详情。其中 Yarn 中任务详情包含任务 ID,提交者,任务类型,完成状态等信息。另外,还可以编写 Hive SQL,并运 SQL,查看 SQL 运行详情。也可以查看 Hive 仓库中所存在的表及其表结构等信息。下载地址,如下所示:
2.内容
Hive Falcon 涉及以下内容:
- Dashboard
- Query
- Tables
- Tasks
- Clients & Nodes
2.1 Dashboard
我们通过在浏览器中输入 http://host:port/hf,访问 Hive Falcon 的 Dashboard 页面。该页面包含以下内容:
- Hive Clients
- Hive Tables
- Hadoop DataNodes
- YARN Tasks
- Hive Clients Graph
如下图所示:

2.2 Query
Query 模块下,提供一个运行 Hive SQL 的界面,该界面可以用来查看观察 SQL 运行的 MapReduce 详情。包含 SQL 编辑区,日志输出,以及结果展示。如下图所示:

提示:在 SQL 编辑区可以通过 Alt+/ 快捷键,快速调出 SQL 关键字。
2.3 Tables
Tables 展示 Hive 中所有的表信息,包含以下内容:
- 表名
- 表类型(如:内部表,外部表等)
- 所属者
- 存放路径
- 创建时间
如下图所示:

每一个表名都附带一个超链接,可以通过该超链接查看该表的表结构,如下图所示:

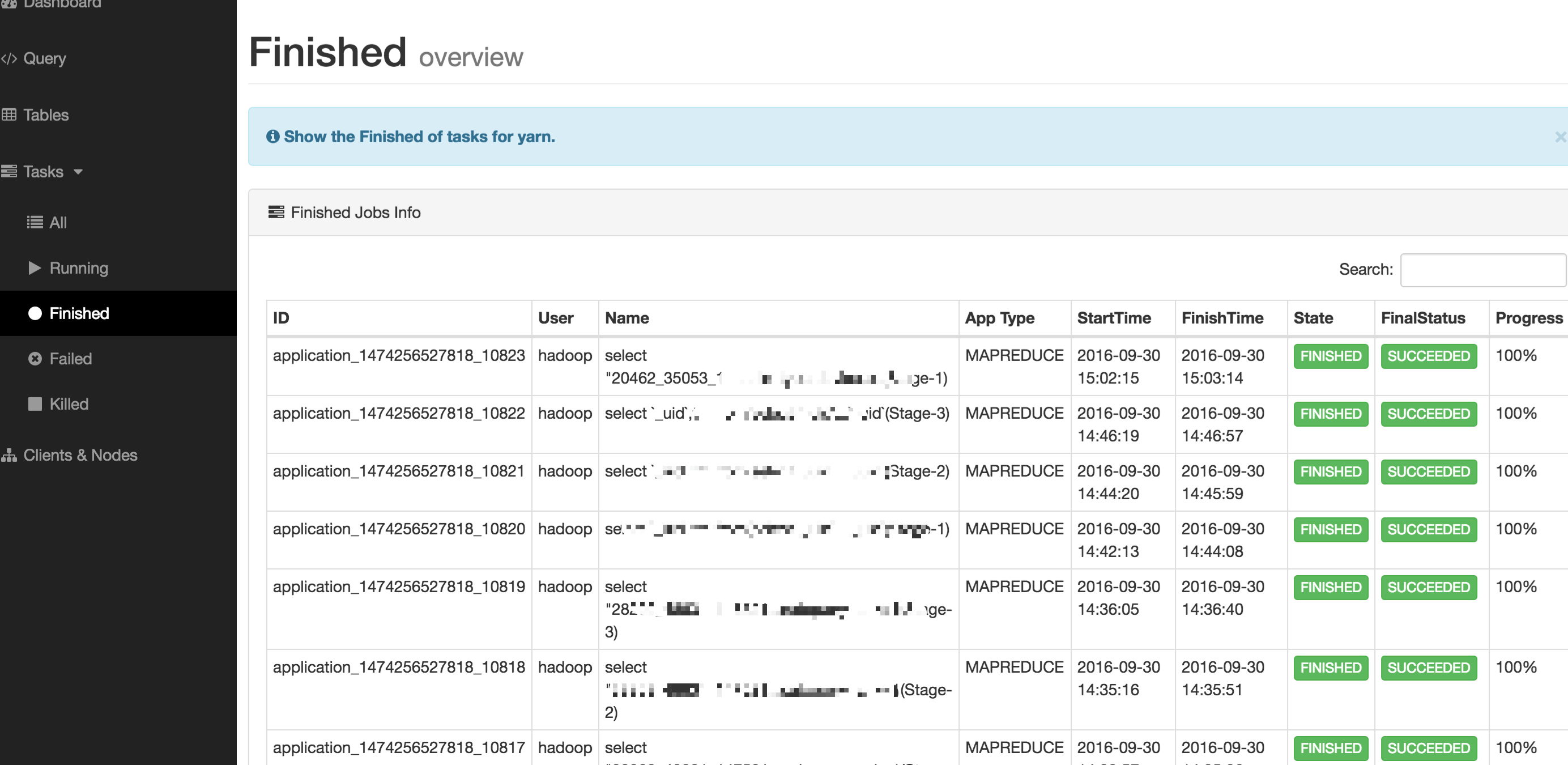
2.4 Tasks
Tasks 模块下所涉及的内容是 YARN 上的任务详情,包含的内容如下所示:
- All(所有任务)
- Running(正在运行的任务)
- Finished(已完成的任务)
- Failed(以失败的任务)
- Killed(已失败的任务)
如下图所示:
2.5 Clients & Nodes
该模块展示 Hive Client 详情,以及 Hadoop DataNode 的详情,如下图所示:

2.6 脚本命令
| 命令 | 描述 |
| hf.sh start | 启动 Hive Falcon |
| hf.sh status | 查看 Hive Falcon |
| hf.sh stop | 停止 Hive Falcon |
| hf.sh restart | 重启 Hive Falcon |
| hf.sh stats | 查看 Hive Falcon 在 Linux 系统中所占用的句柄数量 |
3.数据采集
Hive Falcon 系统的各个模块的数据来源,所包含的内容,如下图所示:

4.总结
Hive Falcon 的安装使用比较简单,下载安装,安装文档的描述进行安装配置即可,安装部署文档地址,如下所示:
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Hive SQL 监控系统 - Hive Falcon的更多相关文章
- hive sql常用整理-hive引擎设置
遇到个情况,跑hive级联insert数据报错,可以尝试换个hive计算引擎 hive遇到FAILED: Execution Error, return code 2 from org.apache. ...
- SQL Standard Based Hive Authorization(基于SQL标准的Hive授权)
说明:该文档翻译/整理于Hive官方文档https://cwiki.apache.org/confluence/display/Hive/SQL+Standard+Based+Hive+Authori ...
- Hive SQL运行状态监控(HiveSQLMonitor)
引言 目前数据平台使用Hadoop构建,为了方便数据分析师的工作,使用Hive对Hadoop MapReduce任务进行封装,我们面对的不再是一个个的MR任务,而是一条条的SQL语句.数据平台内部 ...
- 【hive】——Hive sql语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- hive sql 语法详解
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
- 由“Beeline连接HiveServer2后如何使用指定的队列(Yarn)运行Hive SQL语句”引发的一系列思考
背景 我们使用的HiveServer2的版本为0.13.1-cdh5.3.2,目前的任务使用Hive SQL构建,分为两种类型:手动任务(临时分析需求).调度任务(常规分析需求),两者均通过我们的 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 【甘道夫】使用HIVE SQL实现推荐系统数据补全
需求 在推荐系统场景中,假设基础行为数据太少,或者过于稀疏,通过推荐算法计算得出的推荐结果非常可能达不到要求的数量. 比方,希望针对每一个item或user推荐20个item,可是通过计算仅仅得到8个 ...
- Hadoop Hive sql 语法详细解释
Hive 是基于Hadoop 构建的一套数据仓库分析系统.它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,能够将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
随机推荐
- 我的ORM之示例项目
我的ORM索引 示例项目 code.taobao.org/svn/MyMvcApp/ 1. 编译 MyTool ,DbEnt, WebApp, 安装JRE. 2. 配置 Web.config 数据库字 ...
- Github注册账户
这是注册页面: 注册完后应该会受到邮件,但我一直没有收到,换了邮箱也没有用 ± 账户可以登上去却没办法创建仓库.
- 整理BOM时写的关于拆分单元格的VB代码
Public Function AddRows(pos As Integer, amount As Integer) Dim rpos As Integer rpos = pos + To amoun ...
- [ZigBee] 9、ZigBee之AD剖析——AD采集CC2530温度串口显示
1.ADC 简介 ADC 支持多达14 位的模拟数字转换,具有多达12 位有效数字位.它包括一个模拟多路转换器,具有多达8 个各自可配置的通道:以及一个参考电压发生器.转换结果通过DMA 写入存储器. ...
- 基于Token的WEB后台认证机制
几种常用的认证机制 HTTP Basic Auth HTTP Basic Auth简单点说明就是每次请求API时都提供用户的username和password,简言之,Basic Auth是配合RES ...
- 每天一个linux命令(57):ss命令
ss是Socket Statistics的缩写.顾名思义,ss命令可以用来获取socket统计信息,它可以显示和netstat类似的内容.但ss的优势在于它能够显示更多更详细的有关TCP和连接状态的 ...
- PMP和PRINCE2
首先先简单介绍一下,PMP是属于美国的项目管理知识体系.PRINCE2是属于英国项目体系. 美国的项目管理知识体系最主要的价值是把世界上所有跟项目管理相关的,不管是知识.最佳实践.工具技术,把它们汇总 ...
- salesforce 零基础学习(三十四)动态的Custom Label
custom label在项目中经常用到,常用在apex class或者VF里面用来显示help text或者error message.有的时候我们需要用到的信息是动态变化的,那样就需要动态来显示信 ...
- Android后台保活实践总结:即时通讯应用无法根治的“顽疾”
前言 Android进程和Service的保活,是困扰Android开发人员的一大顽疾.因涉及到省电和内存管理策略,各厂商基于自家的理解,在自已ROOM发布于都对标准Android发行版作为或多或少的 ...
- 总结baiduTemplate和djangoTemplate的学习
引入 开发工作中需要,除了今天要介绍的两种template,还有很多模板,但他们的终点都是相同的,都是为了开发的便利. 模板的作用 是一套模板语法,开发者可以通过写一 ...