【Hadoop学习】HDFS中的集中化缓存管理
Hadoop版本:2.6.0
本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接:
http://www.cnblogs.com/zhangningbo/p/4146398.html
概述
HDFS中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的HDFS路径。NameNode会和保存着所需快数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中。
HDFS集中化缓存管理具有许多重大优势:
1.明确的锁定可以阻止频繁使用的数据被从内存中清除。当工作集的大小超过了主内存大小(这种情况对于许多HDFS负载都是司空见惯的)时,这一点尤为重要。
2.由于DataNode缓存是由NameNode管理的,所以,在确定任务放置位置时,应用程序可以查询一组缓存块位置。把任务和缓存块副本放在一个位置上可以提高读操作的性能。
3.当块已经被DataNode缓存时,客户端就可以使用一个新的更高效的零拷贝读操作API。因为缓存数据的checksum校验只需由DataNode执行一次,所以,使用这种新API时,客户端基本上不会有开销。
4.集中缓存可以提高整个集群的内存使用率。当依赖于每个DataNode上操作系统的buffer缓存时,重复读取一个块数据会导致该块的N个副本全部被送入buffer缓存。使用集中化缓存管理,用户就能明确地只锁定这N个副本中的M个了,从而节省了N-M的内存量。
使用场景
集中化缓存管理对于重复访问的文件很有用。例如,Hive中的一个较小的fact表(常常用于joins操作)就是一个很好的缓存对象。另一方面,对于一个全年报表查询的输入数据做缓存很可能就没有多大作用了,因为,历史数据只会读取一次。
集中化缓存管理对于带有性能SLA的混合负载也很有用。缓存正在使用的高优先级负载可以保证它不会和低优先级负载竞争磁盘I/O。
架构
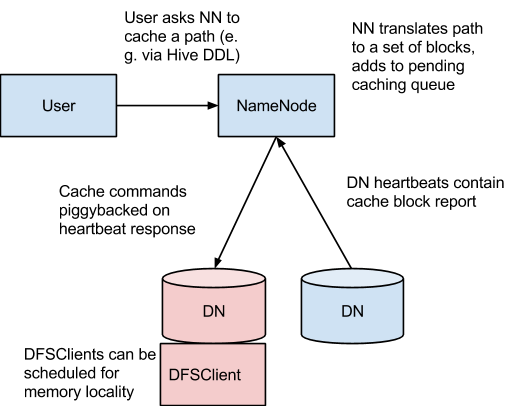
在这个架构中,NameNode负责协调集群中所有DataNode的off-heap缓存。NameNode周期性地接收来自每个DataNode的缓存报告(其中描述缓存在给定DN中的所有块)。NameNode通过借助DataNode心跳上的缓存和非缓存命令来管理DataNode缓存。
NameNode查询自身的缓存指令集来确定应该缓存那个路径。缓存指令永远存储在fsimage和edit日志中,而且可以通过Java和命令行API被添加、移除或修改。NameNode还存储了一组缓存池,它们是用于把资源管理类和强制权限类的缓存指令进行分组的管理实体。
NameNode周期性地重复扫描命名空间和活跃的缓存指定以确定需要缓存或不缓存哪个块,并向DataNode分配缓存任务。重复扫描也可以又用户动作来触发,比如,添加或删除一条缓存指令,或者删除一个缓存池。
当前,我们不缓存construction、corrupt下的块数据,或者别的不完整的块。如果一条缓存指令包含一个符号链接,那么该符号链接目标不会被缓存。
当前,我们只实现了文件或目录级的缓存。块和子块缓存是未来的目标。
概念
缓存指令
一条缓存指令定义了一个要被缓存的路径(path)。这些路径(path)可以是文件夹或文件。文件夹是以非迭代方式缓存的,只有在文件夹顶层列出的文件才有意义。
文件夹也可以指定额外的参数,比如缓存副本因子,有效期等。副本因子指定了要缓存的块副本数。如果多个缓存指令指向同一个文件,那么就用最大缓存副本因子。
有效期是在命令行指定的,就像TTL一样,相对有效期会在未来版本引入。缓存指令过期之后,在决定缓存时,它就不再被NameNode考虑了。
缓存池
缓存池是一个管理实体,用于管理缓存指令组。缓存池拥有类UNIX的权限,可以限制哪个用户和组可以访问该缓存池。写权限允许用户向缓存池添加或从中删除缓存指令 。读权限允许用户列出缓存池内的缓存指令,还有其他元数据。执行权限不能使用。
缓存池也可以用于资源管理。它可以强加一个最大限制值,可以限制通过缓存池中的指令缓存入的字节数。通常,缓存池限制值之和约等于为HDFS在集群中做缓存而保留的总内存量。缓存池也可以追踪许多统计信息以便于集群用户决定应该缓存什么。
缓存池也可以强加一个TTL最大值。该值限制了被添加到缓存池的指令的最大有效期。
缓存管理命令接口
在命令行上,管理员和用户可以使用过hdfs cacheadmin子命令借助缓存池来交互。
缓存指令由一个唯一的无重复的64位整数ID来标识。即使缓存指令后来被删除了,ID也不会重复使用。
缓存池由一个唯一的字符串名称来标识。
缓存管理命令
addDirective
用法: hdfs cacheadmin -addDirective -path <path> -pool <pool-name> [-force] [-replication <replication>] [-ttl <time-to-live>]
| <path> | 要缓存的路径。该路径可以是文件夹或文件。 |
| <pool-name> | 要加入缓存指令的缓存池。你必须对改缓存池有写权限以便添加新的缓存指令。 |
| -force | 不检查缓存池的资源限制 |
| <replication> | 要使用的缓存副本因子,默认为1 |
| <time-to-live> | 缓存指令可以保持有效多长时间。可以按照分钟,小时,天来指定,如30m,4h,2d。有效单位为[smhd]。“never”表示永不过期的指令。如果未指定该值,那么,缓存指令就不会过期。 |
removeDirective
用法: hdfs cacheadmin -removeDirective <id>
| <id> | 要删除的缓存指令的ID。你必须对该指令的缓存池拥有写权限,以便删除它。要查看详细的缓存指令列表,可以使用-listDirectives命令。 |
removeDirectives
用法: hdfs cacheadmin -removeDirectives <path>
| <path> | 要删除的缓存指令的路径。你必须对该指令的缓存池拥有写权限,以便删除它。要查看详细的缓存指令列表,可以使用-listDirectives命令。 |
listDirectives
用法:hdfs cacheadmin -listDirectives [-stats] [-path <path>] [-pool <pool>]
| <path> | 只列出带有该路径的缓存指令。注意,如果路径path在缓存池中有一条我们没有读权限的缓存指令,那么它就不会被列出来。 |
| <pool> | 只列出该缓存池内的缓存指令。 |
| -stats | 列出基于path的缓存指令统计信息。 |
缓存池命令
addPool
用法:hdfs cacheadmin -addPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>
| <name> | 新缓存池的名称。 |
| <owner> | 该缓存池所有者的名称。默认为当前用户。 |
| <group> | 缓存池所属的组。默认为当前用户的主要组名。 |
| <mode> | 以UNIX风格表示的该缓存池的权限。权限以八进制数表示,如0755.默认值为0755. |
| <limit> | 在该缓存池内由指令总计缓存的最大字节数。默认不设限制。 |
| <maxTtl> | 添加到该缓存池的指令的最大生存时间。该值以秒,分,时,天的格式来表示,如120s,30m,4h,2d。有效单位为[smhd]。默认不设最大值。“never”表示没有限制。 |
modifyPool
用法:hdfs cacheadmin -modifyPool <name> [-owner <owner>] [-group <group>] [-mode <mode>] [-limit <limit>] [-maxTtl <maxTtl>]
| <name> | 要修改的缓存池的名称。 |
| <owner> | 该缓存池所有者的名称。 |
| <group> | 缓存池所属的组。 |
| <mode> | 以UNIX风格表示的该缓存池的权限。八进制数形式。 |
| <limit> | 在该缓存池内要缓存的最大字节数。 |
| <maxTtl> | 添加到该缓存池的指令的最大生存时间。 |
removePool
用法:hdfs cacheadmin -removePool <name>
| <name> | 要删除的缓存池的名称 |
listPools
用法:hdfs cacheadmin -listPools [-stats] [<name>]
| -stats | 显示额外的缓存池统计信息 |
| <name> | 若指定,则仅列出该缓存池的信息 |
help
用法:hdfs cacheadmin -help <command-name>
| <command name> | 要获得详细帮助信息的命令。如果没有指定命令,则打印所有命令的帮助信息。 |
配置
本地库
为了把块文件锁定在内存,DataNode需要依赖本地JNI代码(Linux系统为libhadoop.so,Windows系统为hadoop.dll)。如果你正在使用HDFS集中化缓存管理,请确保使能JNI。
配置属性
| 属性名称 | 默认值 | 描述 |
| dfs.datanode.max.locked.memory | 0 | DataNode的内存中缓存块副本要用的内存量(以字节表示)。DataNode的最大锁定内存软限制ulimit(RLIMIT_MEMLOCK)必须至少设为该值。 否则,DataNode在启动时会终止。默认值为0,表示禁止内存缓存。如果本地库对于该DataNode不可用,那么,该配置就无效。 |
| dfs.namenode.list.cache.directives.num.responses | 100 | 该参数控制NameNode在响应listDirectives RPC命令时通过wire发送的缓存指令数。 |
| dfs.namenode.list.cache.pools.num.responses | 100 | 该参数控制NameNode在响应listDirectives RPC命令时通过wire发送的缓存池数。 |
| dfs.namenode.path.based.cache.refresh.interval.ms | 30000 | 两次子路径缓存重复扫描的时间间隔,单位毫秒。路径缓存重复扫描发生在计算缓存哪个块,以及在哪个DataNode上缓存时。默认为30秒。 |
| dfs.namenode.path.based.cache.retry.interval.ms | 30000 | 当NameNode不需要缓存某些数据,或者缓存那些没有缓存的数据时,它必须通过在DataNode心跳响应中发送DNA_CACHE或者DNA_UNCACHE命令,以便指导DataNode这么去做。该参数控制NameNode重复发送这些命令的频率。(即多长时间重发一次) |
| dfs.datanode.fsdatasetcache.max.threads.per.volume | 4 | DataNode上缓存新数据时每个卷要用的最大线程数。 这些线程要消耗I/O和CPU。该参数影响普通DataNode操作。 |
| dfs.cachereport.intervalMsec | 10000 | 决定两次缓存上报动作的时间间隔,单位毫秒。超过这个时间后,DataNode会向NameNode发送其缓存状态的完整报告。 NameNode使用缓存报告来更新缓存块与DataNode位置之间的映射关系。如果内存缓存被禁用了(设置属性dfs.datanode.max.locked.memory为0,这是默认值),那么该参数就无效了。如果本地库对于该DataNode不可用,那么,该配置就无效。 |
| dfs.datanode.cache.revocation.timeout.ms | 900000 | 当DFSClient从DataNode正在缓存的块文件中读取数据时,DFSClient可以不做checksums校验。DataNode一直将块文件保存在缓存中直到客户端完成。然而,如果客户端一改往常般运行了很长时间,那么,DataNode可能需要从缓存中清除这个块文件。该参数控制DataNode等待一个正在执行无校验读操作的客户端发送一个副本要花多少时间。 |
| dfs.datanode.cache.revocation.polling.ms | 500 | DataNode需要多长时间轮询一次客户端是否停止使用DataNode不想缓存的副本。 |
必选属性
| 属性名称 | 默认值 | 描述 |
| dfs.datanode.max.locked.memory | 该参数用于确定DataNode给缓存使用的最大内存量。DataNode用户的“locked-in-memory size”ulimit(ulimit -l)也需要增加以匹配该参数(详见下文OS限制)。当设置了该值时,请记住你还需要一些内存空间用于做其他事情,比如,DataNode和应用程序JVM堆内存、以及操作系统的页缓存。 |
可选属性
以下属性不是必选的,但可能用于调优:
| 属性名称 | 默认值 | 描述 |
| dfs.namenode.path.based.cache.refresh.interval.ms | 300000 | NameNode使用该参数作为两次子路径缓存重复扫描的动作之间的时间间隔,单位为毫秒。该参数计算要缓存的块和每个DataNode包含一个该块应当缓存的副本。 |
| dfs.datanode.fsdatasetcache.max.threads.per.volume | 4 | DataNode使用该参数作为缓存新数据时每个卷要用的最大线程数。 |
| dfs.cachereport.intervalMsec | 10000 | DataNode使用该参数作为两次发送缓存状态报告给NameNode的动作之间的时间间隔。单位为毫秒。 |
| dfs.namenode.path.based.cache.block.map.allocation.percent | 0.25 | 分配给已缓存块映射的Java堆内存的百分比。它是hash map,使用链式hash。如果缓存块的数目很大,那么map越小,访问速度越慢;map越大,消耗的内存越多。 |
OS限制
如果你遇到错误“Cannot start datanode because the configured max locked memory size... is more than the datanode's available RLIMIT_MEMLOCK ulimit,”,就意味着操作系统对用户可以锁定的内存使用量强加了一个限制,该限制值比用户设置的值更低一些。要修复这个问题,必须使用“ulimit -l”命令来调整DataNode运行需要锁定的内存值。通常,该值是在/etc/security/limits.conf文件中配置的。然而,它也会因用户所用的操心系统和分发版的不同而变化。
当你从shell中运行“ulimit -l”并得到一个比你用属性dfs.datanode.max.locked.memory设置的值更高的值,或者字符串“ulimited”(表示没有限制)时,你就会明白你已经正确配置了该值。值得注意的是,ulimit -l命令通常以KB为单位输出内存锁定限制值,但是dfs.datanode.max.locked.memory的值必须以字节为单位。
这些信息不适用于Windows环境部署。Windows没有和“ulimit -l”相对应的命令。
【Hadoop学习】HDFS中的集中化缓存管理的更多相关文章
- HDFS集中化缓存管理
概述 HDFS中的集中化缓存管理是一个明确的缓存机制,它允许用户指定要缓存的HDFS路径.NameNode会和保存着所需快数据的所有DataNode通信,并指导他们把块数据缓存在off-heap缓存中 ...
- Hadoop 学习 HDFS
1.HDFS的设计 HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网 ...
- Hadoop学习-HDFS篇
HDFS设计基础与目标 硬件错误是常态.因此需要冗余 流式数据访问.即数据批量读取而非随机读写,Hadoop擅长做的是数据分析而不是事务处理(随机性的读写数据等). 大规模数据集 简单一致性模型.为了 ...
- Hadoop学习---Eclipse中hadoop环境的搭建
在eclipse中建立hadoop环境的支持 1.需要下载安装eclipse 2.需要hadoop-eclipse-plugin-2.6.0.jar插件,插件的终极解决方案是https://githu ...
- Hadoop学习---Ubuntu中hadoop完全分布式安装教程
软件版本 Hadoop版本号:hadoop-2.6.0-cdh5.7.0: VMWare版本号:VMware 9或10 Linux系统:CentOS 6.4-6.5 或Ubuntu版本号:ubuntu ...
- Hadoop学习-hdfs安装及其一些操作
hdfs:分布式文件系统 有目录结构,顶层目录是: /,存的是文件,把文件存入hdfs后,会把这个文件进行切块并且进行备份,切块大小和备份的数量有客户决定. 存文件的叫datanode,记录文件的切 ...
- hadoop的hdfs中的javaAPI操作
package cn.itcast.bigdata.hdfs; import java.net.URI; import java.util.Iterator; import java.util.Map ...
- Hadoop学习---CentOS中hadoop伪分布式集群安装
注意:此次搭建是在ssh无密码配置.jdk环境已经配置好的情况下进行的 可以参考: Hadoop完全分布式安装教程 CentOS环境下搭建hadoop伪分布式集群 1.更改主机名 执行命令:vi / ...
- 深入学习OpenCV中图像灰度化原理,图像相似度的算法
最近一段时间学习并做的都是对图像进行处理,其实自己也是新手,各种尝试,所以我这个门外汉想总结一下自己学习的东西,图像处理的流程.但是动起笔来想总结,一下却不知道自己要写什么,那就把自己做过的相似图片搜 ...
随机推荐
- 基于条件随机场(CRF)的命名实体识别
很久前做过一个命名实体识别的模块,现在有时间,记录一下. 一.要识别的对象 人名.地名.机构名 二.主要方法 1.使用CRF模型进行识别(识别对象都是最基础的序列,所以使用了好评率较高的序列识别算法C ...
- UML与数据流图
Ref: <数据库设计理论及应用(3)——需求分析及数据>http://wenku.baidu.com/link?url=hbhJFytMKT8A ...
- Vim 命令笔记
给指定行添加序号 let la = 行a let lb = 行b +1 let lc = lb - la for i in range(lc) let cl = la + i call setline ...
- maven 仓库下载缓慢,怎么解决
maven下载jar的时候会去寻国外的地址,因此造成了下载jar很缓慢,影响开发效率,于是就出现maven镜像地址,可以使我们开发人员迅速下载相关的jar. 在maven的config的setting ...
- ubuntu install rpm package
Using command 'alien' instead of 'rpm'. sudo apt-get install alien alien -i tst.rpm 'man alien' for ...
- Image.FrameDimensionsList 属性-----具体使用案例2
图片的拆分 1.保存png图片 using System; using System.Collections.Generic;using System.ComponentModel;using Sys ...
- Lists of network protocols
https://en.wikipedia.org/wiki/Lists_of_network_protocols Protocol stack: List of network protocol st ...
- Codeforces Round #204 (Div. 2) C
写了一记忆化 TLE了 把double换成long long就过了 double 这么耗时间啊 #include <iostream> #include<cstdio> #i ...
- Ionic开发中常见问题和解决方案记录
1npm按装包失败 更换源:npm config set registry https://registry.npm.taobao.org 或者使用cnpm sudo npm install -g c ...
- H264 帧结构分析、帧判断
http://blog.csdn.net/dxpqxb/article/details/7631304 H264以NALU(NAL unit)为单位来支持编码数据在基于分组交换技术网络中传输. NAL ...