python 数据清洗之字符串处理
在数据分析中,特别是文本分析中,字符处理需要耗费极大的精力,
因而了解字符处理对于数据分析而言,也是一项很重要的能力。
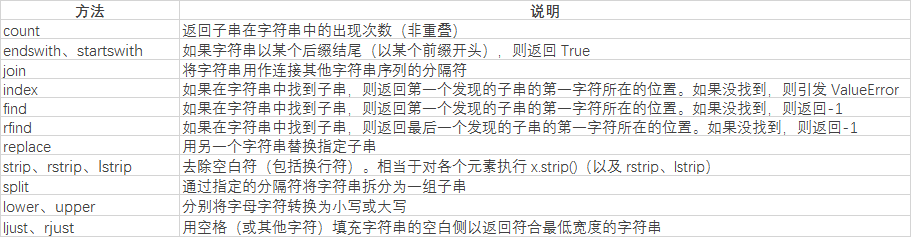
字符串处理方法
首先我们先了解下都有哪些基础方法
首先我们了解下字符串的拆分split方法
str='i like apple,i like bananer'
print(str.split(','))
对字符str用逗号进行拆分的结果:
['i like apple', 'i like bananer']
print(str.split(' '))
根据空格拆分的结果:
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(','))
print(str.find(','))
两个查找结果都为:
12
找不到的情况下index返回错误,find返回-1
print(str.count('i'))
结果为:
4
connt用于统计目标字符串的频率
print(str.replace(',', ' ').split(' '))
结果为:
['i', 'like', 'apple', 'i', 'like', 'bananer']
这里replace把逗号替换为空格后,在用空格对字符串进行分割,刚好能把每个单词取出来。
除了常规的方法以外,更强大的字符处理工具费正则表达式莫属了。
正则表达式
在使用正则表达式前我们还要先了解下,正则表达式中的诸多方法。

下面我来看下个方法的使用,首先了解下match和search方法的区别
str = "Cats are smarter than dogs"
pattern=re.compile(r'(.*) are (.*?) .*')
result=re.match(pattern,str)
for i in range(len(result.groups())+1):
print(result.group(i))
结果为:
Cats are smarter than dogs
Cats
smarter
这种形式的pettern匹配规则下,match和search方法的的返回结果是一样的
此时如果把pattern改为
pattern=re.compile(r'are (.*?) .*')
match则返回none,search返回结果为:
are smarter than dogs
smarter
接下来我们了解下其他方法的使用
str = "138-9592-5592 # number"
pattern=re.compile(r'#.*$')
number=re.sub(pattern,'',str)
print(number)
结果为:
138-9592-5592
以上是通过把#号后面的内容替换为空实现提取号码的目的。
我们还可以进一步对号码的横杆进行替换
print(re.sub(r'-*','',number))
结果为:
13895925592
我们还可以用find的方法把找到的字符串打印出来
str = "138-9592-5592 # number"
pattern=re.compile(r'5')
print(pattern.findall(str))
结果为:
['5', '5', '5']
正则表达式的整体内容比较多,需要我们对匹配的字符串的规则有足够的了解,下面是具体的匹配规则。
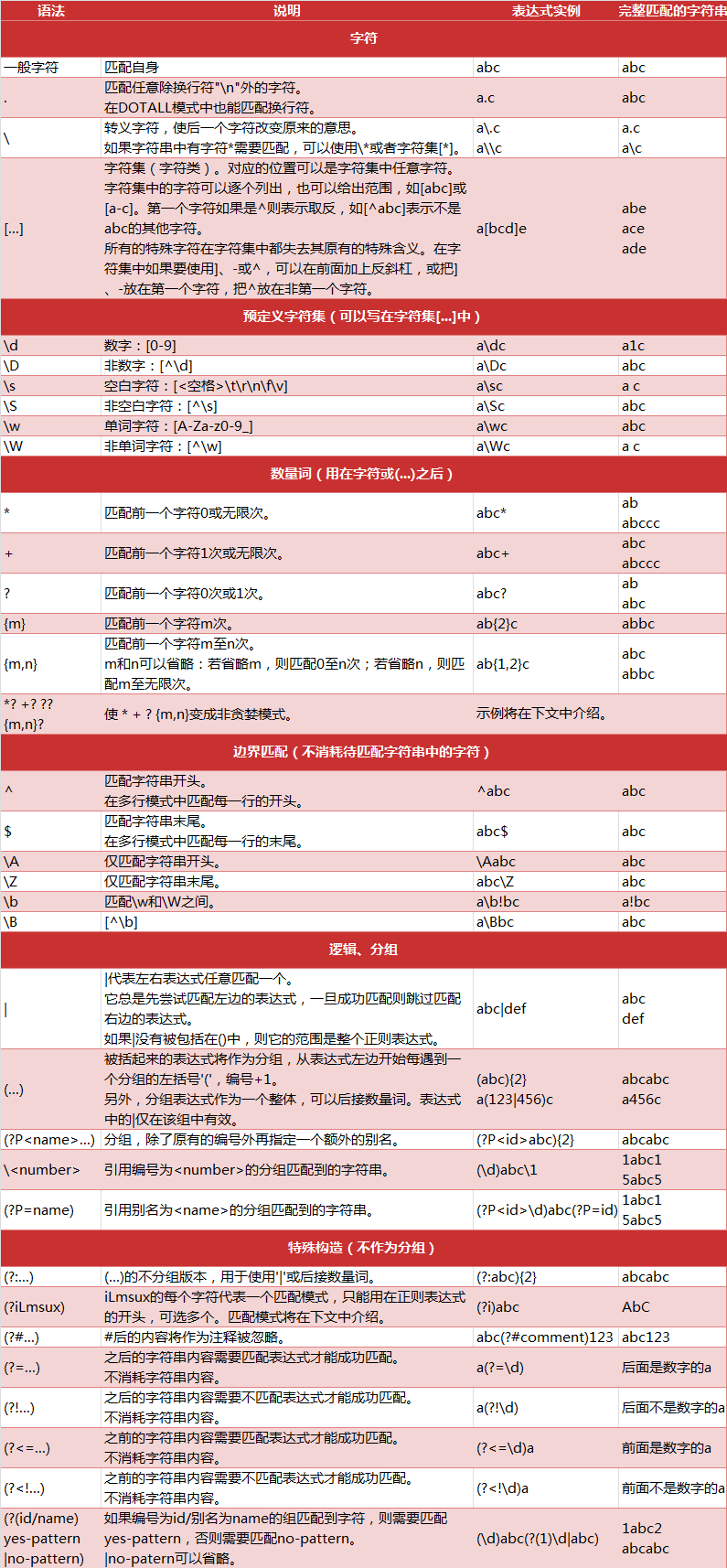
矢量化字符串函数
清理待分析的散乱数据时,常常需要做一些字符串规整化工作。
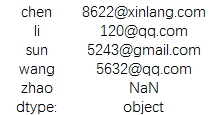
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)
结果为:
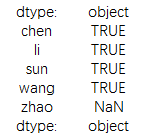
可以通过规整合的一些方法对数据做初步的判断,比如用contains 判断每个数据中是否含有关键词
print(data.str.contains('@'))
结果为:
也可以对字符串进行分拆,把需要的字符串提取出来
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result)
结果为:
chen [(8622, xinlang, com)]
li [(120, qq, com)]
sun [(5243, gmail, com)]
wang [(5632, qq, com)]
zhao NaN
dtype: object
此时加入我们需要提取邮箱前面的名称
print(result.str.get(0))
结果为:
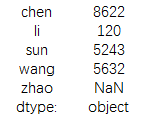
或者需要邮箱所属的域名
print(result.str.get(1))
结果为:

当然也可以用切片的方式进行提取,不过提取的数据准确性不高
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])
结果为:

最后我们了解下矢量化的字符串方法

python 数据清洗之字符串处理的更多相关文章
- 【Python自动化Excel】Python与pandas字符串操作
Python之所以能够成为流行的数据分析语言,有一部分原因在于其简洁易用的字符串处理能力. Python的字符串对象封装了很多开箱即用的内置方法,处理单个字符串时十分方便:对于Excel.csv等表格 ...
- Python中关于字符串的问题
在Python里面,字符串相加经常会出现'ascii' codec can't decode byte 0xe7 in position 0: ordinal not in range(128)这样的 ...
- python出输出字符串方式:
python出输出字符串方式: >>> who='knights' >>> what='NI' >>> print ('we are the',w ...
- Python学习笔记-字符串
Python之使用字符串 1.所有的标准序列操作(索引,分片,乘法,判断成员资格,求长度,取最小值,最大值)对字符串同样适用.但是字符串都是不可变的. 2.字符串格式化使用字符串格式化操作符即%. f ...
- Python中Unicode字符串
Python中Unicode字符串 字符串还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte ...
- Python基础(二) —— 字符串、列表、字典等常用操作
一.作用域 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. 二.三元运算 result = 值1 if 条件 else 值2 如果条件为真:result = 值1如果条件为 ...
- Python补充05 字符串格式化 (%操作符)
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! 在许多编程语言中都包含有格式化字符串的功能,比如C和Fortran语言中的格式化输 ...
- Python中的字符串处理
Python转义字符 在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符.如下表: 转义字符 描述 \(在行尾时) 续行符 \\ 反斜杠符号 \' 单引号 \" 双引号 \a ...
- Python学习笔记整理(四)Python中的字符串..
字符串是一个有序的字符集合,用于存储和表现基于文本的信息. 常见的字符串常量和表达式 T1=‘’ 空字符串 T2="diege's" 双引号 T3=""&quo ...
随机推荐
- 【转】视差滚动(Parallax Scrolling)效果的原理和实现
原文:http://www.cnblogs.com/JoannaQ/archive/2013/02/08/2909111.html 视差滚动(Parallax Scrolling)是指让多层背景以不同 ...
- WCF RIA Services异常
.svc处理程序映射缺失导致的WCF RIA Services异常 在确定代码.编译结果和数据库都正常的情况下,无法从数据库取到数据.错误提示:Sysyem.Net.WebException:远程服务 ...
- Java中的嵌套类和内部类
以前看<Java编程思想>的时候,看到过嵌套类跟内部类的区别,不过后来就把它们的概念给忘了吧.昨天在看<数据结构与算法分析(Java语言版)>的时候,又遇到了这个概念,当时就很 ...
- SpringMVCURL请求到Action的映射规则
SpringMVC学习系列(3) 之 URL请求到Action的映射规则 在系列(2)中我们展示了一个简单的get请求,并返回了一个简单的helloworld页面.本篇我们来学习如何来配置一个acti ...
- javascript继承之借用构造函数与原型
javascript继承之借用构造函数与原型 在js中,关于继承只有利用构造函数和原型链两种来现实.以前所见到的种种方法与模式,只不过是变种罢了. 借用构造函数 1 2 3 4 5 6 7 8 9 1 ...
- jquery 实现飘落效果
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [转]How WebKit’s Event Model Works
原文:https://homes.cs.washington.edu/~burg/projects/timelapse/articles/webkit-event-implementation/ Fi ...
- C语言变参函数的编写
1. 引言 一般我们编程的时候,函数中形式参数的数目通常是确定的,在调用时要依次给出与形式参数对应的实际参数.但在某些情况下我 们希望函数的参数个数可以根据需要确定,因此c语言引入可变参数函数.典型的 ...
- CentOS安装Python教程
下载/安装python yum install -y bzip2* #nodejs 0.8.5需要,请安装python前,先安装此模块. wget http://www.python.org/ft ...
- Cracking the Coding Interview(Trees and Graphs)
Cracking the Coding Interview(Trees and Graphs) 树和图的训练平时相对很少,还是要加强训练一些树和图的基础算法.自己对树节点的设计应该不是很合理,多多少少 ...