hadoop中联结不同来源数据
装载自http://www.cnblogs.com/dandingyy/archive/2013/03/01/2938462.html
有时可能需要对来自不同源的数据进行综合分析:
如下例子:
有Customers文件,每个记录3个域:Custom ID, Name, Phone Number
Customers Orders
1,Stephanie Leung,555-555-5555 3,A,12.95,02-Jun-2008
2,Edward Kim,123-456-7890 1,B,88.25,20-May-2008
3,Jose Madriz,281-330-8004 2,C,32.00,30-Nov-2007
4,David Stork,408-555-0000 3,D,25.02,22-Jan-2009
1.Reduce侧的联结
Hadoop中名为datajoin得contrib软件包,用作数据联结的通用框架。处理多被放在reducer侧,故称为Reduce侧的联结。
术语:数据源——即表,Customers,和 Orders
标签(tag)——标记数据源
组键(group key)——即两个表得链接键,本例子中为custom ID
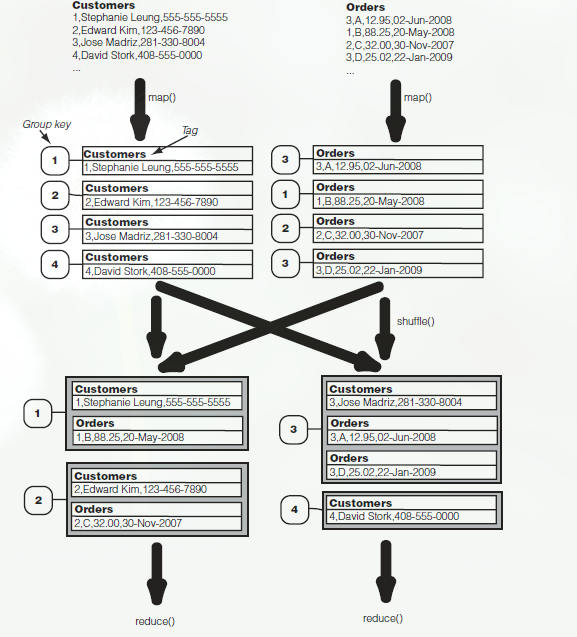
分析该流程图可以看到,每个map处理不同的源,并且map()阶段的工作就是对每条记录进行打包——即设置其tag,Group key 和内容;
对于数据的联结,map()输出一个记录包,采用组键作为联结键。值为原始记录,并且值由文件名tag标记;
map()封装了输入后,就进行MapReduce标准的分区、洗牌和排序操作。最终相同联结键的记录会被送到同一个reducer上;
reducer接受上面的输入数据后,进行完全交叉乘积,reduce生成所有值的合并结果(这个部分由reduce 自己完成,程序员不用处理)。规定一个合并中每个值最多标记一次(即只有一个标签)。如组健1,2,4所示,组健3如下:
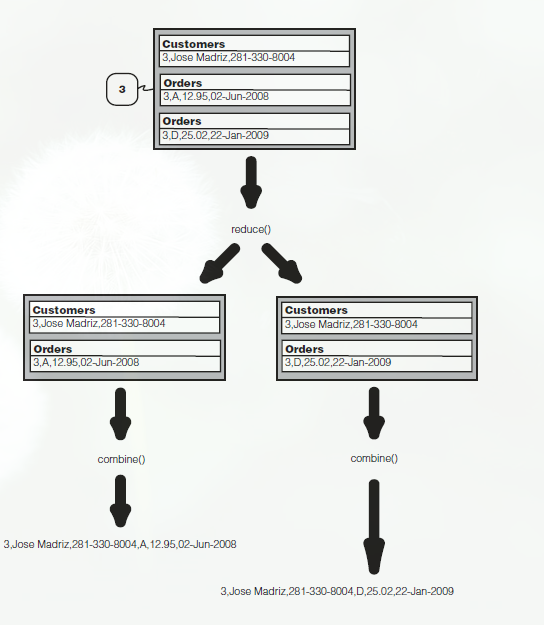
交叉乘积结果送入combine()中(这里的combine()与前面的Combiner不同),combine决定了操作时内联结、外联结、还是其他方式的联结。
内联结丢弃未含全部tag的结果(如4)。然后合并剩余记录。
整个过程结束,这就是 重分区排序-合并联结。
- 使用DATAJOIN软件包联结
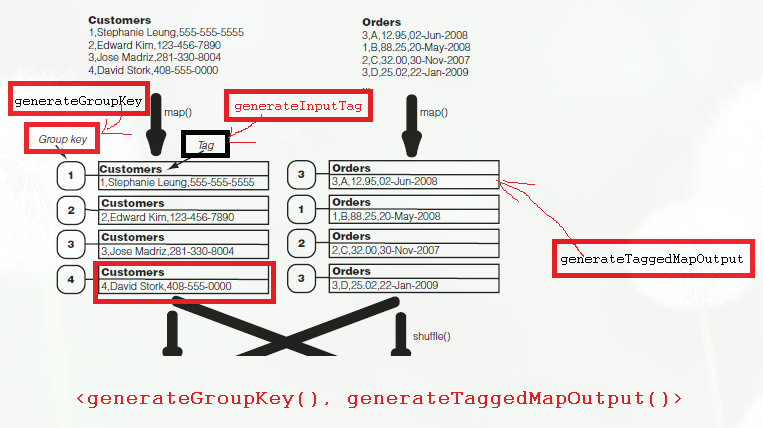
Hadoop的datajoin软件包提供了3个供继承的抽象类:DataJoinMapperBase,DataJoinReducerBase和TaggedMapOut类
所以MapperClass实现DataJoinMapperBase类;Reducer实现DataJoinReducerBase类。map()和reduce()方法已经由datajoin软件包提供了,我们的子类只需实现几种配置详细信息的方法
datajoin指定键为Text型,而值为新的抽象数据类型TaggedMapOutput。
TaggedMapOutput是一种用Text标签封装记录的数据类型。实现了getTag()和setTag(Text tag)方法。
我们要自己实现抽象方法getData(),有时还需实现setData()方法,将记录传入,也可以从构造函数中传入。
另外,作为值,TaggedMapOutput须为Writable型,所以要实现readFields() write()方法。
对于data join的mapper需要继承自DataJoinMapperBase,并且该mapper需要实现三个方法:
以下为《hadoop in action》示例,注意在eclipse下使用datajoin须添加hadoop-datajoin-0.20.203.0.jar包到工程的Library中
jar包位于/hadoop/contrib/datajoin/下,添加到 工程/propertites/java build path/Library/add extra jar.
另外新的API已经不再使用mapper,reducer接口,而Datajoin中DataJoinMapperBase,DataJoinReducerBase都是实现前两个的接口,所以job.setMapperClass会出错。只能使用旧的jobconf.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
|
public class DataJoin extends Configured implements Tool{ //TaggedMapOutput是一个抽象数据类型,封装了标签与记录内容 //此处作为DataJoinMapperBase的输出值类型,需要实现Writable接口,所以要实现两个序列化方法 public static class TaggedWritable extends TaggedMapOutput { private Writable data; public TaggedWritable(Writable data) //构造函数 { this.tag = new Text(); //tag可以通过setTag()方法进行设置 this.data = data; } @Override public void readFields(DataInput in) throws IOException { tag.readFields(in); data.readFields(in); } @Override public void write(DataOutput out) throws IOException { tag.write(out); data.write(out); } @Override public Writable getData() { return data; } } //mapper的主要功能是封装一个记录,实现如下三个方法达到次目的 public static class JoinMapper extends DataJoinMapperBase { //这个在任务开始时调用,用于产生标签 //此处就直接以文件名作为标签 @Override protected Text generateInputTag(String inputFile) { return new Text(inputFile); } //这里我们已经确定分割符为',',更普遍的,用户应能自己指定分割符和组键。 @Override protected Text generateGroupKey(TaggedMapOutput record) { String line = ((Text)record.getData()).toString(); String[] tokens = line.split(","); return new Text(tokens[0]); } @Override protected TaggedMapOutput generateTaggedMapOutput(Object value) { TaggedWritable retv = new TaggedWritable((Text) value); retv.setTag(this.inputTag); //不要忘记设定当前键值的标签 return retv; } } //DataJoinReducerBase是DataJoin软件包的核心,它执行了一个完整的外部联结。 //我们的子类只是实现combine方法用来筛选掉不需要的组合,获得所需的联结操作(内联结,左联结等)。并且 //将结果化为合适输出格式(如:字段排列,去重等) public static class JoinReducer extends DataJoinReducerBase { //两个参数数组大小一定相同,并且最多等于数据源个数 @Override protected TaggedMapOutput combine(Object[] tags, Object[] values) { if(tags.length < 2) return null; //这一步,实现内联结 String joinedStr = ""; for(int i = 0; i < values.length; i++) { if(i > 0) joinedStr += ","; //以逗号作为原两个数据源记录链接的分割符 TaggedWritable tw = (TaggedWritable)values[i]; String line = ((Text)tw.getData()).toString(); String[] tokens = line.split(",", 2); //将一条记录划分两组,去掉第一组的组键名。 joinedStr += tokens[1]; } TaggedWritable retv = new TaggedWritable(new Text(joinedStr)); retv.setTag((Text)tags[0]); //这只retv的组键,作为最终输出键。 return retv; } |
2.基于DistributedCathe的复制连结
reduce侧连结效率较低,因为map阶段重排了以后可能会丢弃的数据。如果能在map阶段执行连结速度会有较高效率,但是map阶段键不统一,不知道当前记录该与哪个记录连结。
对于特定的数据模式:一个数据源较小,另一个很大的情况,可以将小的复制到所有mapper上,实现map阶段连结。(这种数据成为“背景”数据,由hadoop分布式缓存分发)。
管理分布式缓存的类为:DistributedCathe;采取如下两个步骤使用该类:
使用静态方法DistributedCache.addCatheFile()设定传播到所有节点的文件;
使用静态方法DistributedCache.getLocalCatheFiles()获取本地副本路径;
在使用DistributedCache还会出现一种情况:背景数据在本地系统中,这时
一种方法是添加代码,在addCacheFile()前将本地文件上传到HDFS中;
另一种方法是使用GenericOptionsParser,直接通过这种命令行参数来支持,选项为-files,后面文件以','分隔
hadoop jar DataJoin.jar -files fileA.txt,fileB.txt input.txt output
此时无须自己调用addCacheFile(),在改变一下程序中参数索引即可。
3.半连接:map侧过滤reduce侧连结
要寻找特定键(如ID为415的记录)的所有记录时,可以现在customs中找出所有ID为415的顾客,组成custom415临时文件,然后连结custom415与orders即可;
如果custom415还是太大,可以先把提取出目标键(此例中为415)记录在customID415临时文件中,map阶段会丢弃所有键不再customID415中的记录,最后于orders连结;
如果还是太大,就需要使用Bloom filter数据结构。
hadoop中联结不同来源数据的更多相关文章
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 浅析 Hadoop 中的数据倾斜
转自:http://my.oschina.net/leejun2005/blog/100922 最近几次被问到关于数据倾斜的问题,这里找了些资料也结合一些自己的理解. 在并行计算中我们总希望分配的每一 ...
- Xamarin.Forms中为WebView指定数据来源Source
Xamarin.Forms中为WebView指定数据来源Source 网页视图WebView用来显示HTML和网页形式内容.使用这种方式,可以借助网页形式进行界面设计,并利于更新和维护.WebVi ...
- Hadoop中两表JOIN的处理方法(转)
1. 概述 在传统数据库(如:MYSQL)中,JOIN操作是非常常见且非常耗时的.而在HADOOP中进行JOIN操作,同样常见且耗时,由于Hadoop的独特设计思想,当进行JOIN操作时,有一些特殊的 ...
- hadoop中HBase子项目入门讲解
HBase 是Hadoop的一个子项目,HBase采用了Google BigTable的稀疏的,面向列的数据库实现方式的理论,建立在hadoop的hdfs上,一方面里用了hdfs的高可靠性和可伸缩行, ...
- Hadoop中两表JOIN的处理方法
Dong的这篇博客我觉得把原理写的很详细,同时介绍了一些优化办法,利用二次排序或者布隆过滤器,但在之前实践中我并没有在join中用二者来优化,因为我不是作join优化的,而是做单纯的倾斜处理,做joi ...
- Hadoop基础之初识大数据与Hadoop
前言 从今天起,我将一步一步的分享大数据相关的知识,其实很多程序员感觉大数据很难学,其实并不是你想象的这样,只要自己想学,还有什么难得呢? 学习Hadoop有一个8020原则,80%都是在不断的配置配 ...
- Hadoop中MR程序的几种提交运行模式
本地模型运行 1:在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行 ----输入输出数据可以放在本地路径下(c:/wc ...
- Hadoop中客户端和服务器端的方法调用过程
1.Java动态代理实例 Java 动态代理一个简单的demo:(用以对比Hadoop中的动态代理) Hello接口: public interface Hello { void sayHello(S ...
随机推荐
- Java中需要总结的几个问题
慢慢总结,不然每次百度挺心烦的. 1. java文件的读写 2. String和StringBuffer的区别
- NOIP2013-普及组复赛-第一题-计数问题
题目描述 Description 试计算在区间 1 到 n 的所有整数中,数字 x(0 ≤ x ≤ 9)共出现了多少次?例如,在 1到 11 中,即在 1.2.3.4.5.6.7.8.9.10.11 ...
- C# 循环语句
本次主要学习了for循环语句. for循环语句的基本格式是: for(初始条件;循环条件;状态改变) { 循环体; } break——中断循环,跳出循环. continue——停止本次循环,进入下次循 ...
- java类中为什么设置set和get方法操作属性
java程序规范中会建议大家尽量将类中的属性私有化,即定义为private变量,通过设置set和get函数来对属性进行操作.一些人存在这样的疑问,为什么不直接将属性设置为public,以后调用属性时直 ...
- java 邮件
使用java语言实现邮件的简单的发送和接受. 说明:使用Java应用程序发送E-mail比较简单,在使用下列程序之前,你需要将mail.jar和activation.jar 添加到你的CLASSP ...
- ubuntu14.04 安装 tensorflow
如果内容侵权的话,联系我,我会立马删了的-因为参考的太多了,如果一一联系再等回复,战线太长了--蟹蟹给我贡献技术源泉的作者们- 最近准备从理论和实验两个方面学习深度学习,所以,前面装好了Theano环 ...
- radiobutton以及checkbox背景图片拉伸变形的问题
设置RadioButton的text属性,只需要有这个属性就可以(设置“”内容就行),然后再添加textsize属性,将字体大小属性值设置为比较小,我设置为2sp.运行后我们会发现图片变形问题不复存在 ...
- ios UIApplocation 中APP启动方式
iOS app启动的方式有哪些: 自己启动(用户手动点击启动) urlscheme启动(关于urlScheme的详解)http://www.cnblogs.com/sunfuyou/p/6183064 ...
- Javascript:scrollWidth,clientWidth,offsetWidth的区别(转)
网页可见区域宽:document.body.clientWidth; 网页可见区域高:document.body.clientHeight; 网页可见区域高:document.body.offsetW ...
- 《JS权威指南学习总结--3.4null和undefined》
内容要点 一.相似性 var a= undefined; var b= null; if(a==b){ alert("相等"); ...