GB和GBDT 算法流程及分析
1、优化模型的两种策略:
1)基于残差的方法
残差其实就是真实值和预测值之间的差值,在学习的过程中,首先学习一颗回归树,然后将“真实值-预测值”得到残差,再把残差作为一个学习目标,学习下一棵回归树,依次类推,直到残差小于某个接近0的阀值或回归树数目达到某一阀值。其核心思想是每轮通过拟合残差来降低损失函数。
总的来说,第一棵树是正常的,之后所有的树的决策全是由残差来决定。
2)使用梯度下降算法减小损失函数。
对于一般损失函数,为了使其取得最小值,通过梯度下降算法,每次朝着损失函数的负梯度方向逐步移动,最终使得损失函数极小的方法(此方法要求损失函数可导)。
2、GB(Gradient Boosting)梯度提升算法
GB其实是一个算法框架,即可以将已有的分类或回归算法放入其中,得到一个性能很强大的算法。
GB总共需要进行M次迭代,每次迭代产生一个模型,我们需要让每次迭代生成的模型对训练集的损失函数最小,而如何让损失函数越来越小呢?我们采用梯度下降的方法,在每次迭代时通过向损失函数的负梯度方向移动来使得损失函数越来越小,这样我们就可以得到越来越精确的模型。
梯度提升算法(GB)过程如下:[1]
1)初始化损失函数。
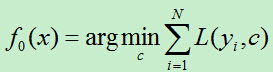
2)对于第m轮迭代,当m<=M时循环执行A)~D) (m=1,2,…,M)
A)计算残差rmi:
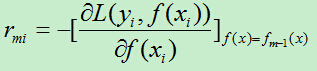
计算损失函数的负梯度在当前模型的值,将它作为残差的估计,对于平方损失函数它就是残差,对于一般损失函数,它就是残差的近似值。
B)对rmi拟合一颗回归树,得到第m课树的叶节点区域Rmj。(j=1,2,…,J)
(估计回归树叶节点区域,拟合残差近似值)
C)对j=1,2,…,J,线性搜索出损失函数的最小值
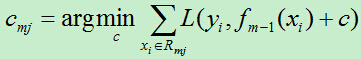
D)更新f(x)
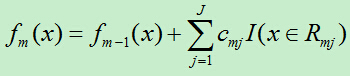
3)得到回归树
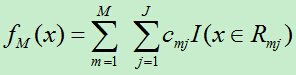
下面给出Friedman大牛论文中的GB算法[6],论文下载链接:http://pan.baidu.com/s/1pJxc1ZH

图2.1 Gradient Boost算法[6]
3、GBDT (Gradient Boosting Decision Tree):梯度提升决策树算法
此处主要讨论多类Logistic回归问题

图3.1 多类logistic回归算法[6]
关于以上代码,网友已有分析:[5] (在此借用)
“1. 表示建立M棵决策树(迭代M次)
2. 表示对函数估计值F(x)进行Logistic变换
3. 表示对于K个分类进行下面的操作(其实这个for循环也可以理解为向量的操作,每一个样本点xi都对应了K种可能的分类yi,所以yi, F(xi), p(xi)都是一个K维的向量,这样或许容易理解一点)
4. 表示求得残差减少的梯度方向
5. 表示根据每一个样本点x,与其残差减少的梯度方向,得到一棵由J个叶子节点组成的决策树
6. 为当决策树建立完成后,通过这个公式,可以得到每一个叶子节点的增益(这个增益在预测的时候用的)
每个增益的组成其实也是一个K维的向量,表示如果在决策树预测的过程中,如果某一个样本点掉入了这个叶子节点,则其对应的K个分类的值是多少。
7. 的意思为,将当前得到的决策树与之前的那些决策树合并起来,作为新的一个模型
”
最后本人对GBDT研究得还不够透彻,下次研究清楚了再专门写一篇GBDT的文章!!
参考文献:
[1] 李航,统计学习方法。
[2] 林轩田,机器学习技法。
[3] 程序员之家,http://www.programerhome.com/?p=3665
[4] DianaCody, http://www.dianacody.com/2014/11/01/GBRT.html
[5] leftnoteasy, http://www.cnblogs.com/leftnoteasy/archive/2011/03/07/random-forest-and-gbdt.html
[6] Friedman J H. Greedy Function Approximation: A Gradient Boosting Machine[C]// Annals of Statistics1999:1189--1232.
GB和GBDT 算法流程及分析的更多相关文章
- 一步一步理解GB、GBDT、xgboost
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- GBDT算法简述
提升决策树GBDT 梯度提升决策树算法是近年来被提及较多的一个算法,这主要得益于其算法的性能,以及该算法在各类数据挖掘以及机器学习比赛中的卓越表现,有很多人对GBDT算法进行了开源代码的开发,比较火的 ...
- GB、GBDT、XGboost理解
GBDT和xgboost在竞赛和工业界使用都非常频繁,能有效的应用到分类.回归.排序问题,虽然使用起来不难,但是要能完整的理解还是有一点麻烦的.本文尝试一步一步梳理GB.GBDT.xgboost,它们 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- Weka算法Clusterers-DBSCAN源代码分析
假设说世界上仅仅能存在一种基于密度的聚类算法的话.那么它必须是DBSCAN(Density-based spatial clustering of applications with noise).D ...
- 【机器学习实战】第11章 使用 Apriori 算法进行关联分析
第 11 章 使用 Apriori 算法进行关联分析 关联分析 关联分析是一种在大规模数据集中寻找有趣关系的任务. 这些关系可以有两种形式: 频繁项集(frequent item sets): 经常出 ...
- GBDT 算法:原理篇
本文由云+社区发表 GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效的运算大受欢迎. 这里简单介绍一下 GBDT 算法的原理,后续再写一个实战篇. 1.决策树的分类 决策树分为两大 ...
- 转载:GBDT算法梳理
学习内容: 前向分布算法 负梯度拟合 损失函数 回归 二分类,多分类 正则化 优缺点 sklearn参数 应用场景 转自:https://zhuanlan.zhihu.com/p/58105824 G ...
- Zbar算法流程介绍
博客转载自:https://blog.csdn.net/sunflower_boy/article/details/50783179 zbar算法是现在网上开源的条形码,二维码检测算法,算法可识别大部 ...
随机推荐
- ubuntu上面安装eclipse android到adt下载方法
如果自动安装有问题的话,就需要手动安装,其实是差不多的,唯一不同的就是手动下载ADT插件包,http://dl.google.com/android/ADT-0.9.6.zip ,可以下载到. 版本号 ...
- string 与wstring 的转换
std::wstring StringToWString(const std::string &str) { std::wstring wstr(str.length(),L' '); std ...
- js 中ajax请求时设置 http请求头中的x-requestd-with= ajax
今天发现 AngularJS 框架的$http服务提供的$http.get() /$http.post()的ajax请求中没有带 x-requested-with字段. 这样的话,后端的php 就无法 ...
- Ubuntu系统如何修改主机名
1.执行命令 hostname temp_name 这样主机名就改掉了.只不过重启后名字会恢复不一定使我们想要的.机器重启后会重新去读取/etc/hostname里面存储的主机名.所以如果想永久改掉的 ...
- UIView 视图切换
UIView之间常用视图之间切换方式 转载自:http://www.jianshu.com/p/0d53f9402c07 在平时编写代码的过程中,页面之间的跳转可以说就和MVC模式一样是开发必须的.但 ...
- Fragment在Activity中的应用 (转载)
原文链接 http://www.cnblogs.com/nanxin/archive/2013/01/24/2875341.html 在本小节中介绍在Activity中创建Fragment. 官网有很 ...
- HDU 1176 免费馅饼(数塔dp)
一开始被吓到了,后来再仔细一读发现就是一个数塔,没有那么复杂 #include<stdio.h> #include<string.h> #include<algorith ...
- XML简单的增改删操作
XML文件的简单增改删,每一个都可以单独拿出来使用. 新创建XML文件,<?xmlversion="1.0"encoding="utf-8"?> & ...
- 皓轩的jquery mobile之路(二)
jQuery Mobile 使用 HTML5 & CSS3 最小的脚本来布局网页. 编写代码要注意最外层div需要添加data-role="page" ,标题需要添加dat ...
- Django之路:简介以及环境
(sudo) pip install Django 或者 (sudo) pip install Django==1.6.10 或者 pip install Django==1.7.6 Windows ...